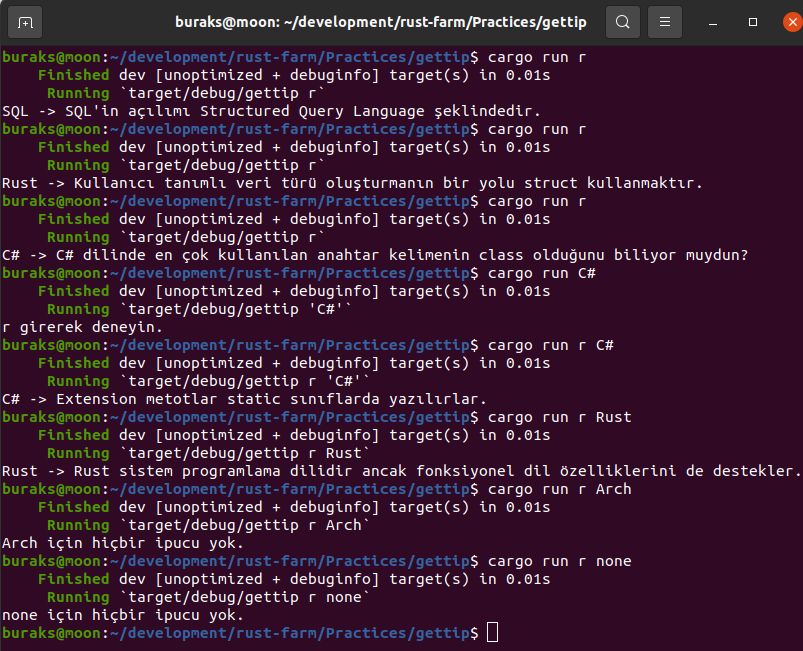
![]() Hepimiz için berbat geçen bir yılı geride bırakıyoruz. Koca sene boyunca uğraştığımız salgının etkileri daha da sürecek gibi duruyor. 2021 bize neler getirir bilemiyorum ama yazılımcıların bilgisayarları başında daha çok vakit geçirdiği günlerin hayatımızda kalıcı hale geldiğini de ifade edebilirim. Geçen yılın bir bölümünde işlerden arta kalan vakitlerde kendimce yeni şeyler öğrenmeye gayret ettim. Bunlardan birisi de Mozilla Labs'ın gücünü arkasına almış olan Rust programlama diliydi.
Hepimiz için berbat geçen bir yılı geride bırakıyoruz. Koca sene boyunca uğraştığımız salgının etkileri daha da sürecek gibi duruyor. 2021 bize neler getirir bilemiyorum ama yazılımcıların bilgisayarları başında daha çok vakit geçirdiği günlerin hayatımızda kalıcı hale geldiğini de ifade edebilirim. Geçen yılın bir bölümünde işlerden arta kalan vakitlerde kendimce yeni şeyler öğrenmeye gayret ettim. Bunlardan birisi de Mozilla Labs'ın gücünü arkasına almış olan Rust programlama diliydi.
Stackoverflow 2020 yılı geliştirici anketine göre en sevilen programlama dili olduğunu söylemeden geçmeyelim ki bu son birkaç yıldır da böyle. Geliştiricilerini Rustaceans olarak adlandırıldığı programlama dilini öğrenmekte zorlandığımı itiraf edeyim (Halen daha emekleme aşamasındayım)Özellikle ownership(sahiplenme), borrowing(borç alma), referans türlerin yaşam ömürlerinin kontrolü(lifetime,scope), mutex yapıları, reference counting, smart pointers vb
Uzun yıllar Garbage Collector gibi enstrümanlara sahip yönetimli ortamlarda geliştirme yapınca, birden tüm bellek operasyon maliyetlerinin ne olacağını bilerek kodlama yapmaya çalışmak çok kolay olmuyor. Üstelik Rust derleyicisi oldukça akıllı ve kodlama hatalarınızda sizi en iyi seçeneğe gitmeniz noktasında sürekli olarak uyarıyor. Kod gelişitirken özellikle derleyici açısından baktığımızda GO'nun katı kuralcılığını açıkça hissediyorsunuz.
Fonksiyonel programlama paradigmasına ait özellikler barındıran Rust daha çok sistem seviyesinde programlama için tasarlanmış bir dil ancak farklı kullanım alanları da var. Örneğin Deno platformu, Microsoft Azure IoT Edge'in çok büyük bir kısmı, Servo isimli yüksek hızlı tarayıcı motoru, TockOS, Tifflin, RustOS, QuiltOS, Redox gibi işletim sistemleri, Linux ls komutunun alternatifi olan exa bu dil kullanılarak geliştirilmiş. Bunların dışında oyun motorları, derleyiciler, container'lar, sanal makineler(VM), Linux dosya sistemleri ile gömülü cihaz sürücülerinin geliştirilmesinde de tercih ediliyor. Bir başka ifadeyle Rust diliyle iş odaklı uygulamalar harici yazılım ve yazılım platformları geliştirildiğini ifade edebiliriz. Bu nedenle Rust donanım dostu bir dil desek yeridir.
Rust ortamında Garbage Collector gibi bir mekanizma yok ve bunun en büyük amacı tahmin edileceği üzere çalışma zamanı performansının artırılması. Koda eklenen her satırın parasını ödememizi isteyen bir ortam sunuyor diyelim. Cimri bir dil olduğunu ve bellek kullanımında aşırı masraftan kaçınmamızı istediğini belirteyim. Öyleki tüm değişkenler varsayılan olarak immutable(değiştirilemez) oluşuyor ve herhangi bir fonksiyon içerisinde kullanıldıktan sonra bulunduğu scope içerisinde tekrar kullanılamıyor(Diğer fonksiyonda kullanıldı ve artık işi bitti, Bellekten At!!! Tabii bu kuralı esnetebiliriz) Ayrıca immutable kullanım minik veri yapılarında(Data Structures) önemli bir performans kazanımı sunmaktadır. Yüklü veri yapılarında ise mutable kullanım daha uygun olabilir nitekim referans almak yığının bir kopyasını oluşturarak çalıştırmaktan daha mantıklıdır.
Bu dilin diğer önemli hedefleri arasında eş zamanlılık(Concurrency) ve güvenli bellek kullanımı yer almakta. Derlemeli bir dil olan Rust çıktı olarak Web Assembly'da üretebiliyor(Şuradaki dokümana bir bakın derim) Rust dilinde paket yöneticisi olarak Cargo isimli araç kullanılıyor.
Dilin henüz öğrenmeye çalıştığım daha pek çok özelliği var. Gelin bu uzun dokümantasyonla hangi konuları ele aldık inceleyelim. Ben ilgili örnekleri Heimdall(Ubuntu 20-04)üstünde ve Visual Studio Code kullanarak geliştirdim. Sistemde Rust ortamını hazırlamak ve rs uzantılı bir kod dosyası oluşturup derlemek oldukça basitti.
curl https://sh.rustup.rs -sSf | sh
# Dilin genel özelliklerini tanımak için bir dosya üstünde çalışalım
touch WhoAreYouRust.rs
Burada kullandığımız kod parçası ise şöyle.
// fonksiyon bildirimi anlamına gelir
fn main(){ // Tahmin edileceği üzere programın giriş noktası. Önceden tanımlı fonksiyondur println!("I hate hello world!"); // Sondaki ünlem işareti println'in bir macro olduğu ifade eder. /* Makrolar fonksiyonların genişletilmiş hali olarak ifade ediliyor. Çalışma zamanındaki meta bilgileri ile konuşma olanakları varmış.
Sanırım bunu ilerde daha net anlarım.
*/
}Peki bu kodu nasıl çalıştıracağız? Öncelikle bir derleme işlemi yapmamız gerekiyor. Sonrasında platform için oluşan binary'yi çağırabiliriz.
# Rust kodlarını derlemek için
rustc WhoAreYouRust.rs
# Çalıştırmak içinse
./WhoAreYouRust
Faktöryel ile Hello World
Biraz önce paket yöneticisi olarak Cargo isimli programın kullanıldığından bahsetmiştik. Cargo ile rust projeleri oluşturabilir, onları çalıştırabilir, paketleri yönetebilir ve testler başlatabiliriz. Bundan sonraki örneklerin tamamında cargo aracının kullanıldığını ifade edeyim. Örneğin factorial isimli biraz da ortamı koklayacağımız örneği oluşturmak için aşağıdaki terminal komutunu vermemiz yeterli.
cargo new factorial
main.rs içeriğini aşağıdaki gibi kodlayabiliriz. Yorum satırlarını dikkatlice okumaya gayret edin.
/* isimlendirme standardı olarak snake_case kullanılıyor.
Mesela input_x yerine inputX kullanınca cargo check sonrası uyarılar alıyoruz.
Bu ilk kod parçası ekrandan bir sayı değeri alıp faktöryelini buluyor.
*/
use std::io; // IO modülünü kullanacağımızı belirttik. stdin fonksiyonunu kullanabilmek için gerekli
fn main() { println!("Selam! Ben bir hesap makinesiyim :P"); println!("X değeri?");
/* Aşağıdaki iki değişken tanımı söz konusu. Rust dilinde değişkenler varsayılan olarak immutable'dır. Yani atamadan sonra değerleri değiştirilmez.
*/ let mut input_x = String::new(); // bunun mutable olması gerektiğinden mut keyword'ü kullanıldı.
let x: u32; io::stdin().read_line(&mut input_x).expect("Bir hata oldu"); // ekrandan girilen bilgiyi input_x'e okuyoruz (& sanıyorum pointer. İleride netleştirelim)
x = input_x .trim() .parse() .expect("Dönüştürme işleminde hata"); // ekrandan alınan bilgi 32bit integer'a dönüştürüyoruz. /* expect fonksiyonları, bir önceki işlemde bir panic havası eserse ilgili mesajı veriyor. Panic'ler nasıl ele alınıyor ilerde öğrenelim.
*/ let y = calculate(x); // hesaplama fonksiyonunu çağırıyoruz
println!("x! = {}", y); // Sonucu ekrana basıyoruz
// x = 9; // Değişkenler varsayılan olarak immutable olduğundan burada derleme hatası oluşur. x'e ikinci kez değer atayamayız.
}
/*
Recursive çalışan fonksiyonumuz. Unsigned Integer 32 alıp aynı tipten sonuç dönüyor.
*/
fn calculate(num: u32) -> u32 { match num { // Pattern matching uygulanıyor
0 | 1 => 1, // 0 veya 1 ise 1 döner _ => calculate(num - 1) * num, // bunlardan farklı ise sayıyı bir azaltıp yine kendisini çağırır
}
}Önce kodu derleyelim ve sonrasında çalıştıralım.
# Cargo üstünde build için
cargo build
# ve çalıştırmak için
cargo run
Bu arada kodu derlemeden kontrol etmek için cargo check, sürüm çıkarmak içinse cargo build --release komutlarını kullanabiliriz.
![]()
Sayı Tahmin Oyunu
Sıradaki örneğimizde rastgele sayı üretimi için kullanacağımız rand isimli bir kütüphane var. Bu örnekte amaçlardan birisi de harici kütüphaneleri nasıl kullanabileceğimizi görmek. Rand kütüphanesini kullanabilmek için toml dosyasındaki [dependencies] kısmında bir bildirim yapmak gerekiyor.
[package]
name = "lucky_number"
version = "0.1.0"
authors = ["buraksenyurt <...@....com>"]
edition = "2018"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
rand = "0.7.3" # random sayı üreten kütüphane
Dolayısıyla Rust uygulamalarının bu tip paket bağımlılıklarının toml dosyasında bildirildiğini ifade edebiliriz. İlgili paketler cargo build sonrası eğer sistemde yoksa indirileceklerdir. Ana program kodlarını aşağıdaki gibi yazarak devam edelim.
use rand::Rng; // rastgele sayı kütüphanesi
use std::cmp::Ordering; // Kıyaslama operasyonu için eklenen Enum. cmp(Compare) için match kullanılan yere dikkat
use std::io; // Standart kütüphane. Ekrandan girdi okumakta işimize yarayacak
/*
Örnek kod parçasında sayı tahmin oyunu icra ediliyor. Yarışmacının 5 tahmin hakkı var.
*/
fn main() { println!("Sayı tahmin oyununa hoşgeldin...");
println!("10 ile 30 arası bir sayı tuttum.\nBakalım bilebilecek misin?"); // 1 ile 50 arası sayı üretiyor // thread_rng, rastgele sayı üretici nesnesini verir // get_range metodu ile let computer_number = rand::thread_rng().gen_range(10, 30); let mut player_guess: u8; // yine mutable bir pozitif tam sayı tanımı. 8 bitlik. println!("Hadi bir tahminde bulun"); // 5 iterasyonlu bir döngü kurduk for i in 1..6 { let mut screen_input = String::new(); // Değeri değiştirilebilir bir String değişken (Mutable) println!("{}. hak", i); // Ekran girilen veriyi screen_input değişkenine alıyoruz
io::stdin() .read_line(&mut screen_input) .expect("Okuma sırasında hata"); // Olası hata durumu mesajımız
/* String değeri u8 tipine dönüştürüyoruz ama nasıl? :) parse metodu bir sonuç döner. Bu sonuç Ok veya Err değerleri içeren bir Enum sabitidir. Bu sabiti match ederek ne yapılacağına karar veriyoruz. Ok ise sorun yok. Yani dönüştürme başarılı olmuş.
Lakin dönüştürme başarısızsa parse dönüşü Err demektir. Bu durumda ekrana mesaj yazdırıp continue ile döngüyü devam ettiriyoruz. */ player_guess = match screen_input .trim() // neden trim'ledik .parse() { Ok(n) => n, Err(_) => { println!("Girdiğin sayıyı dönüştüremedim. Lütfen tekrar dene."); continue; } }; /* cmp çağrısının sonucu Ordering sabitinin hangi durumu oluşuyorsa,
ona göre bir kod parçası işletiliyor.
match Arms Aşağıdaki şekilde bir kullanım söz konusu. match value { pattern => expression, pattern => { expressions }, // blokta olabilir pattern => expression, } */ match player_guess.cmp(&computer_number) { Ordering::Less => println!("Tahminini yükselt"), Ordering::Equal => { // Doğru tahmin etmişse döngüden çıkartırız
println!("Bingo!!!"); break; } Ordering::Greater => println!("Tahminini küçült."), } } println!( "Oyun tamamlandı ve benim tuttuğum sayı {} idi", computer_number );
}İşte çalışma zamanına ait iki örnek çıktı.
![]()
ve
![]()
Sepeti Doldurmaya Devam
Şimdiki örnekte değişkenlerin immutable olma halini, sabitleri(constants), shadowing konusunu, temel veri türlerini, statik dil özelliklerini, tuple ile slice veri yapılarını, for döngülerinde match, iter ve rev kullanımları ile loop döngüsünü ele alıyoruz.
fn main() { /* Rust dilinde değişkenler varsayılan olarak immutable karekteristiktedir. */ let point = 90; println!("Sınav puanın {}", point); // point += 10; // Yandaki atamaya izin verilmez. Derleme zamanı hatası alınır.
// Ancak immutable bir tipin mutable yapılarak sonradan değerinin değiştirilebilmesi de mümkündür. // fight değişkeni mutable olarak işaretlemiştir. Bu nedenle değeri değiştirilebilir.
let mut fight = "Dı dıp dı dıp dı dıp dı dı dıp dı";
println!("Mortal Combat {0}", fight); fight = "dı dı dıı dı dı dı dı dıı dıı dı dı dı dıııd";
println!("Mortal Comat(Remix) {}", fight); /* CONSTANT const ile sabit değişkenler tamınlanabilir. Bunlar sadece tanımlandıkları gibi immutable değildir. Daima immutable'dır.
Bir constant tipi tanımlanırken tür belirtilmelidir. İsimlendirme standardı da aşağıdaki gibidir */ const ALWAYS_ON: bool = false; println!( "Always on mode is {}", match ALWAYS_ON { true => "Active", false => "Passive", } // Şu match ifadesinin kullanımını biraz daha anlayayım diye ); /* SHADOWING let ile tanımladığımız immutable bir değişken(ki varsayılan olarak da öyle zaten) tekrardan let kullanılarak yeni bir değer alabilir ve hatta değişken türü de değişime uğrayabilir.
Buna shadowing deniyor. İkinci let kullanımı ile birlikte ilk değişkenin değeri gölgede bırakılıyor.
shadowing immutable tipler için geçerli bir durum. */ let value = 23.93; let value = value + 0.58; // Burada shadowing söz konusu. println!("Value = {}", value); // En azından buradaki gibi value değişkenini kullanmazsak derleme zamanında Warning mesajı görürüz let value = true; // hatta burada shadowing olmakla kalmıyor veri türü de değişiyor
println!("Value = {}", value); /* DATA TYPES Rust statik tür kullanan bir dildir. Dolayısıyla derleme noktasına gelindiğine her değişkenin türü bellidir. Veri tileri saysıla (Scaler) ve bileşik (Compound) olmak üzere ikiye ayrılır.
Integer Tipi Bit Signed Unsigned 8-bit i8 u8 16-bit i16 u16 32-bit i32 u32 64-bit i64 u64 128-bit i128 u128 arch isize usize İşlemcinin 32 bit veye 64 bit olma durumuna göre boyutlanır
Floating Point Tipi f32 f64 Bunlar haricinde bool, char (4 byte'lık Unicode Scalar türüdür ve neredeyse her dilden karakteri destekler) COMPOUND(Bileşik Türler) Rust dilinde önceden tanımlı iki bileşik tür vardır. Tuple ve Array Tuple tipinde farklı türlerden değişkenleri bir liste olarak tutabiliriz. Array tipi ise sadece aynı türden değişkenleri barındırabilir.
Array'lerde eleman sayısı sabittir. Veriyi stack üzerinde tutmak istediğimizde idealdir. Aksi durumda Vector tipi tercih edilebilir. */ let pi = 3.14; // tip belirtmesekte Rust eşitliğe bakarak varsayılan bir tür ataması yapar let ageLimit: u8 = 12; // pek tabii veri türünü bilinçli olarak söyleyebiliriz de (u8 - 8 Bit Unsigned Integer oluyor) let limit: u8 = "18".parse().expect("Dönüştürme hatası"); // Tipler arası dönüşüm de söz konusudur. Bu durumda da dönüştürülecek veri türü söylenmelidir let eular: f32 = 2.76666666; // 32 bit floating point. Bir şey belirtmezsek f64 türünü alır
let basket = ("Lamba", true, 1.90, 3.14, 10); // Burada basit bir tuple tanımı söz konusu. println!("{} {}", basket.0, basket.3); // tuple içindeki farklı yerlerdeki elemanlara bu şekilde erişebiliriz.
let (a, b, c, _, e) = basket; // pattern matching ile tuple içeriğini bu şekilde değişkenlere de alabiliriz. Hatta _ ile atlayabiliriz de. (Bu arada bu atamaya destructuring deniliyor) println!("{},{},{},{}", a, b, c, e); let numbers = [1, 5, 2, 6, 9, 3, 8, 15, 37, 99]; // Basit bir dizi tanımı
println!("{}", numbers[2]); let colors: [char; 3] = ['R', 'G', 'B']; // Diziyi tanımlarken veri türü ve eleman sayısı da verilebilir println!("{}", colors[2]); let columns = [1; 10]; // Bu da değişik bir kullanım. 10 tane 1 den oluşan bir dizi tanımladık
println!("{}", columns[9]); // let column = columns[11]; //11 numaralı indis olmadığı için derleme hatası oluşur. Hatta VS Code IDE'sinde bile altı kırmızı olarak çizilir /* SLICES Veri yapılarından birisi de slice türüdür. Ownership özelliği yoktur. Bir nesne dizisinden bir dilimin referans eden veri türü gibi düşünülebilir. */ let song = String::from("Uzun ince bir yoldayım. Gidiyorum gündüz gece"); let slice1 = &song[..5]; // baştan itibaren 5 karakterlik bir dilimi işaret eden bir slice println!("{}", song); println!("{}", slice1); let slice2 = &song[5..17]; // bu sefer 5nci karakterden itibaren 16ncıya kadarlık bir kısmı dilimleyip başlangıç adresini işaret eden bir slice değişkeni oluşturduk
println!("{}", slice2); let numbers = [1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 14, 15, 16]; let slice3 = &numbers[10..]; //10ncu eleman sonrasında itibaren son eleman kadar olan kısmı dilimledik for n in slice3 { println!("{}", n); } /* FUNCTIONS Değer döndüren fonksiyonlarda eğer en son noktada işlem sonucu alınıyorsa return kelimesini kullanmak zorunlu değildir,
fonksiyonun farklı noktalarında dönüş vermek istersek return kullanabiliriz */ println!("4+7={}", sum_of_two(4, 7)); // fibonacci fonksiyonunu da çağıralım
println!("13ncü sıradaki fibonacci sayısı {}", find_fibonacci(13)); /* LOOPS Birkaç döngü örneği de koyalım. Rust dilin üç döndü çeşidi var loops,for ve while */ // iter fonksiyonu ile yukarıdaki numbers dizisi elemanlarında ileri yönlü hareket edebiliriz for nmbr in numbers.iter() { println!( "{} {}", nmbr, if nmbr % 3 == 0 { // burada satır içi if koşulu kullandım
"Tek sayı"
} else { "Tek sayı değil"
} ); } // for döngüsünü ters yönlü olarak da kullanabiliriz // 1den 10a kadar tanımlı bir sayı aralığında geriye doğru gidiyoruz for nmbr in (0..11).rev() { print!("{}...", nmbr); } println!("On Live"); // loop örneği. Koşula bağlı tekrarlı kod parçaları için tercih edilebilir // Sonsuz döngü örneği
// loop { // println!("Aghh!!! Çıkarın beni burdan"); // } let mut counter = 0; let result = loop { // loop içerisinde break ile çıktığımızda döndürdüğümüz değer bu değişkene atanır
counter += 1; if counter == 10 { break "işlemler bitti"; } }; println!("{}", result);
}
fn sum_of_two(x: i32, y: i32) -> i32 { x + y // return dememize ve ; koyduğumuzda hata alırız
}
// n'nci sıradaki fibonacci sayısını bulan fonksiyon
fn find_fibonacci(n: u32) -> u32 { match n { // pattern matching kullandık
0 => 1, // n sayısının 0 olma hali 1 => 1, // n sayısının 1 olma hali _ => find_fibonacci(n - 1) + find_fibonacci(n - 2), // n sayısının bunlar 0 ve 1 dışında olma hali }
}Bu örnekte immutable olan point değişkenini değiştirmeye çalıştığımızda aşağıdaki ekran görüntüsünde yer alan derleme zamanı hatasını alırız.
![]()
Sahiplenme(Ownership)
Bu ilk etapta anlamakta oldukça zorlandığım bir kavramdı. Bir değişkenin kullanıcı operatör tarafından sahiplenmesi ve işini yaptıktan sonraki akibeti ile tüm bunların yönetimi aslında performans ve bellek kullanımı güvenliği için önemli. İzleyen örnekte String tipleri arasında yapılan atama sonrası atanan tipin scope dışında kalmasını(move), metot parametre ve dönüş tiplerinde sahipliğin değişmesi, &(referencing) ve *(deReferencing) operatörlerinin kullanımı, borç alma(borrowing), aynı scope içinde birden fazla mutable referans ataması hali(Data Race kısıtı) gibi biraz daha zorlayıcı konulara değinmeye çalışıyoruz. Yorum satırlarına dikkat!
/* RUST dilinde Garbage Collector mekanizması yoktur. Ownership (Sahiplik) dilin en önemli olgularındandır.
Belleğin Stack ve Heap alanlarının ne olduğunu iyi bilmeyi gerektirir.
*/
fn main() { /* Önce scope kavramına bir değinmek lazım.
Aşağıda {} arasında bir scope açtık. Bu scope içinde tanımlı değişkenler sadece bu scope içinde kullanılabilir.
*/ { // greetings değişkeni henüz scope'a dahil değil
let greetings = "It's raining..."; // scope'a dahil oldu println!("{}", greetings); // scope içinde kullanıldı
} //burası açtığımız scope'un sonlandığı yer // println!("{}", greetings); // greetings artık scope dışı ve kullanılamaz
/* string demişken...
Doğal olarak string literal ile tanımlanan değişkenler de diğer türler gibi varsayılan olarak immutable'dır.
Diğer yandan string içeriği kullanıcı tarafından çalışma zamanında da girilebilir. Hatta bu belki bir dosyanın içeriğidir.
Yani başlangıçta ne kadar alan kaplayacağı belli olmayabilir. String veri tipinden yararlanarak içeriği çalışma zamanında belli olacak metinsel içerikler tanımlayabiliriz.
Bilin bakalım String türü bellekte nerede durur (Heap) */ { // Yeni bir scope açtık
let mut username = String::from("Jean"); //scope içinde geçerli username.push_str("Van Damme"); // metne yeni bilgi ekledik. username mutable hale getirildi. println!("{}", username); // scope içinde kullandık
} //scope dışına çıktık. username kaynağa iade edildi // Scope dışına çıkıldığında Rust çalışma zamanı drop isimli bir fonksiyon çağırır. C#'taki Destructor gibi düşünebilirim. /* Değişkenler arası atamalar, bellekte tutuldukları lokasyonlara göre farklı davranışlar gösterirler. Stack'te tutulan sayısal değerler ile String'i karşılaştıralım.
Özellikle String'lerin atamasında move adı verilen bir olay söz konusudur */ let x = 10; // stack'de x için yer açıldı
let mut y = x; // stack'de y için yer açıldı ve içine x'in değeri kopyalandı
y += 5; // y değerini değiştirdim. Atayama rağmen bu x'in değerini bozmaz println!("x={} y={}", x, y); // Şimdi String tipinin durumuna bakalım
// start_city değişkeni tanımlandığında stack'te bir işaretçi alan ve heap'te de içeriğin tutulduğu alanlar ayrılır
// stack'te değişken heap'e referans ettiği adres bilgisi, içeriğin uzunluğu(Length) ve yine içeriğin byte cinsinden ne kadar alan tuttuğu(Capacity) bilgileri de yer alır
let start_city = String::from("London"); let end_city = start_city; // x ve y arasındaki atamaya benzer bir atama yaptık. Farklı olarak stack bölgesinde end_city isimli bir değişken oluşturuldu ve start_city'deki adres, uzunluk ve kapasite bilgileri buraya kopyalandı
// yani end_city'de start_city'nin heap'te referans ettiği veriyi işaret etmekte println!("{}", end_city); // Bu noktada start_city'nin ömrü dolar. Artık sadece end_city geçerlidir // println!("City is {}", start_city); // Burada derleme zamanı hatası alınır.
/* start_city'yi end_city'ye almak scope dışına çıkıldığında bir hataya neden olur. drop fonksiyonu her iki değişken içinde çalışacağından Double Free hatası oluşur ve bellek güvenliği(memory safety) kaybolur. Bu nedenle Rust aslında start_city'nin stack'teki bilgilerini (adres, uzunluk, kapasite) end_city'ye alırken, start_city'yi de geçersiz kılar.
Ancak yine de istersek heap bölgelerinin de birer kopyasını çıkartabiliriz. Deeply Copy */ let name = String::from("niklas"); let copy_of_name = name.clone(); // deeply copy. Artık stack ve heap'te iki ayrı kopya var. Ancak bunun maliyeti yüksektir. Hem temizleme sırasındaki ek operasyon yüzünden hem de programın çalıştığı bellek alanının büyümesi nedeniyle println!("{} {}", name, copy_of_name); /* String gibi Heap kullananlar ile stack'i kullananların fonksiyonlara parametre olarak geçtikleri zamanki duruma bir bakalım.
Sonrasında stack üzerinde duran ve dahili copy işlemine destek veren türlere(i32 mesela) */ let words = String::from("blue,red,green,gold,pink"); process_word(words); // burada move işlemi söz konusu yani artık words oyun dışı kaldı
//println!("{}", words); // burada derleme zamanı hatası alınır
let my_lucky_number = 32; process_number(my_lucky_number); // my_luck_number, fonksiyona kopyalanarak geçti. Yani stack'teki konumu halen daha geçerli println!("{}", my_lucky_number); // bu nedenle my_lucky_number scope'taki konumunu korumaya devam ediyor /* O zaman soru geliyor. Örneğin bir String değişkeni bir metoda ille de referans olarak geçirmek istersem ne yapacağım?
find_world_length metodundaki word, atama sonrası quote değişkeninin stack'teki adres alanını referans eden bir değere sahip olur. sadece adres bilgisini taşır, quote üstünde bir sahipliği yoktur. */ let quote = String::from("Zaman su misali akıyor.Engel tanımadan, duraksamdan, geriye dönmeden"); let l = find_word_length("e); println!("'{}' cümlesinin uzunluğu {} karekterdir", quote, l); // referans türünden taşıma nedeniyle quote hala oyunun içinde(scope dahilinde yani) /* Referanslı değişkenlerin mutable olarak kullanılmasında dikkat edilmesi gereken bir nokta var. Bir referansı mut kelimesi ile mutable yapabiliyoruz ancak aynı scope içinde sadece bir kere yapılabiliyor.
Yani aşağıdaki kor parçası geçersiz. your_quote referansını aynı scope içinde mutable olarak iki değişkene almamız kısıtlanmıştır.
Amaç çalışma zamanında birden fazla pointer'ın aynı bellek adresine erişmesine müsaade etmemektir. Data Races adı verilen bu durum uygulamanın çalışma zamanında beklenmedik davranışlar sergilemesine neden olur. Rust bunu henüz derleme aşamasında engellemek ister. O nedenle aşağıdaki kod build olmaz. Elbette farklı scope'lar kullanarak bu durum aşılabilir.
Diğer yandan aynı scope'da bir mutable ve n sayıda immutable referansa izin verilmektedir */ let mut your_quote = String::from("Hımm...");
let s1 = &mut your_quote; let s2 = &mut your_quote; println!("{} {}", s1, s2);
}
fn process_word(word: String) { println!("{} üstünde işlemler...", word);
}
fn process_number(number: i32) { println!("{}", number);
}
// parametrenin referans olarak taşınması
// word & bildirimi ile bir sahiplik değil referans beklediğini söyler
// Rust dilinde fonksiyonların referans tipinden parametre almasına Borrowing deniliyor
fn find_word_length(word: &String) -> usize { // word.push_str(" - Anonim"); // borrowing durumlarında bu kullanıma izin verilmez. Derleme zamanı hatası alınır. Ancak bir istinsa var. word parametresi mutable hale getirilir. (word: &mut String) şeklinde
word.len()
} // scope dışına çıktığımız yer. word bir sahiplik taşımadığı için metodun çağırıldığı yerdeki quote değişkeni oyunda kalmaya devam ederÖrnekteki borrow of moved hatasına ait ekran görüntüsü aşağıdaki gibidir.
![]()
Kendi Struct Veri Türümüz
Rust tarafında kendi veri türlerimizi tanımlarken başvurduğumuz önemli tiplerden birisi struct. Bu örnekte tuple görünümlü struct yazılması, impl blokları ile struct veri yapısına kendi çalışma zamanı örneği ile çalışacak metotlar eklenmesi gibi konulara odaklanıyoruz.
/* OOP'taki gibi bir varlığı ve niteliklerini tanımlamanın yolu struct veri tipidir
*/
fn main() { // Product tipinde bir struct nesnesi örnekledik // Aksi belirtilmedikçe struct türleri de immutable'dır
// Sonradan içeriklerinde değişiklik yapacaksak mut ile mutable hale getirilmelidir let mouse = Product { title: String::from("El Ci Kablosuz Mouse"), company: String::from("Azon Manufacturing Company"), unit_price: 44.50, stock_level: 100, is_usable: false, }; write_to_console(mouse); //Ekrana bilgilerini yazıracağımı bir metot kullanayım dedim // println!("{}", mouse.title); // mouse.company = String::from("New Company"); // mouse değişkeni mutable tanımlanmadığı için mümkün değildir lakin mutable olsa da kod hata verecektir let monitor = create_product( String::from("Filips 24 inch monitor"), String::from("Northwind Enterteintmant"), 340.50, 45, ); // Bir struct'ı diğer bir struct içeriğinden yararlanarak oluşturmak da mümkün (struct update sytnax) let monitor2 = Product { title: String::from("Soni viewsonic monitor"), ..monitor // Dikkat! Bu noktada monitor oyun dışı kalıyor(scope dışında). Neden? }; write_to_console(monitor2); // Burada da tuple struct kullanımı söz konusu let persival = Player(String::from("Ready"), String::from("Player One"), 95); println!("{} {} {}", persival.0, persival.1, persival.2); /* Bir struct için tanımlanan metot kullanım örneği.
struct yapısından değişkenler tanımladıktan sonra o değişken kapsamına dahil olan ilgili metotları çağırabiliriz.
*/ let gudyonsen = Gamer { play_count: 17, penalty_point: 12, ability_rate: 3, }; println!("{}", gudyonsen.get_level()); println!("{}",gudyonsen.calc_reward());
}
struct Who {} // Yandaki gibi hiçbir alan içermeyen türden strcut ta tanımlanabiliyor. Trait konusunda önem kazanıyormuş. Henüz amacını anlayamadım
/* Birde tuple struct diye bir mevzu var. Alan adları(field names) yok dikkat edileceği üzere. Bu nedenle alan adlarına 0,1,2 gibi isimler üzerinden erişebiliyoruz.
*/
struct Player(String, String, i16);
// Parametrelerden yararlanarak geriye Product örneği döndüren fonksiyonumuz
fn create_product(title: String, company: String, unit_price: f32, stock_level: i16) -> Product { /* metot parametre adları ile struct alan adları aynı olduğu için aşağıdaki gibi bir kullanım mümkün. yani title:title, company:company gibi atamalar yapmak zorunda değiliz
*/ Product { title, company, unit_price, stock_level, is_usable: false, }
}
fn write_to_console(p: Product) { println!( "\n{} ({})\n{} dalır.\nStokta {} adet var.\nŞu an satışta mı? {}", p.title, p.company, p.unit_price, p.stock_level, if p.is_usable { "evet" } else { "hayır" } );
}
// Product isimli bir struct
struct Product { title: String, company: String, unit_price: f32, stock_level: i16, is_usable: bool,
}
/*
Struct veri yapısı için metotlarda tanımlanabilir.
Ancak tanımlanma şekilleri fonksiyonlardan biraz farklıdır.
Struct metotları, struct'ın kendi kapsamı içinde tanımlanır.
Aşağıda Gamer struct'ı için iki metodun nasıl tanımlandığı gösterilmekte.
*/
struct Gamer { play_count: i16, ability_rate: i16, penalty_point: i16,
}
impl Gamer { fn get_level(&self) -> i16 { // self ile metodu imlpemente ettiğimiz veri yapısının çalışma zamanındaki örneğini işaret ederiz ki struct metotları &self referansı ile başlamak zorundadır
return ((self.play_count * 10) - self.penalty_point) + self.ability_rate; // çalışma zamanındaki değişken değerlerine erişmek için de self. notasyonu üstünden ilerleriz. } fn calc_reward(&self) -> String { return String::from("Müthiş bir ödül kazandın");
}
}Enum Veri Türü
Pek çok programlama dilinde enum tipi mevcut. Sayısal olarak ifade edilen sabitleri isimlendirerek kullandığımız tipler olarak düşünebiliriz. Rust dilinde de enum desteği var ama bazen struct'lar yerine de tercih edilebiliyorlar. Öyle ki enum içindeki değişkenler başka veri türlerini ele alarak kullanılabiliyorlar. Enteresan değil mi? Yani bir başka deyişle enum türünü sadece sayılara isimler veren bir tür olarak değil bir veri yapısı şeklinde tanımlayıp kullanabiliyoruz. Pattern Matching ifadelerinden de enum değişkenlerinde pek bir güzel yararlanılabiliyor(Option ile match kullanımı)
// Önce örnek bir enum nasıl tanımlanıyor bakalım
enum TaskSize { Small, Medium, Large, Xlarge,
}
// Şimdi de yukarıdaki enum sabitini de kullanan bir struct tanımladık
struct Task { size: TaskSize, title: String,
}
// Lakin yukarıdaki gibi bir kullanım yerine struct verisini içeren bir enum tipi de tanımlanabiliyor
enum Job { Small(String, i32), // Parantez içerisindeki String kısımları Task struct'ı içerisindeki title yerine geçiyor. i32 ile de işin büyüklüğünü ifade edebiliriz Medium(String), Large(String), Xlarge(String),
}
// Hatta enum veri yapısındaki değişkenler primitive türler gibi bir struct'ı da kullanabilirler
struct Detail { title: String, business_value: i32,
}
enum Action { Small(Detail), //Action değişkenleri Detail isimli struct veri yapısını içerir Medium(Detail), Large(Detail),
}
// Enum veri yapısı her değişkeni farklı sayıda ve türle çalışacak şekilde de tanımlanabilir.
enum Status { Done, // Bir veri ile ilişkili değil. Standart enum sabiti. Error { reason: String, impact_size: i8 }, // Error değişkeni anonymous bir struct içerir Log(String), // Log değişkeni ise bir String içerecektir
}
// Yukarıdaki Status isimli veri yapısı struct'lar ile aşağıdaki şekilde de ifade edilebilirdi.
struct StatusDone;
struct StatusError { reason: String, impact_size: i8,
}
struct StatusLog(String); //Tuple Struct
/*
Aynen struct veri yapısında olduğu gibi, enum veri yapısı da kendi metotlarına sahip olabilir. Bunun için de impl bloğu kullanılır. Örneğin,
*/
impl Action { fn write_detail(&self) {}
}
/*
Pek tabii struct veri yapısını kullanırken büyük ihtimalle ortada bir duruma uyan vakalar vardır.
Hangi enum durumunda neler yapılacağına karar verirken pattern matching'den yardım alabiliriz. Aşağıdaki enum yapısını ve process fonksiyonunu ele alıp main içerisinde nasıl kullanıldığına bakalım.
*/
enum VehicleEvent { StartEngine, StopEngine, Fire { x: i32, y: i32 }, // Buna C stilinde veri yapısı deniyor (C-Style Structure)
}
fn process(event: VehicleEvent) { // pattern matchin ile VehicleEvent'in tüm durumlarını ele alıyoruz
match event { VehicleEvent::StartEngine => println!("Motor çalıştı"),
VehicleEvent::StopEngine => println!("Motor durdu"), VehicleEvent::Fire { x, y } => println!("Araç {}:{} konumuna ateş etti", x, y), }
}
/*
Option<T> enum veri yapısı ile etkili pattern matching kodları yazabiliriz. Aşağıdaki fonksiyon i16 türünden Option değişkeni alıyor. Option enum veri yapısı için değer vardır veya yoktur(None) durumu söz konusu. Buna göre herhangibir i16 için karesini alacak.
*/
fn square(number: Option<i16>) -> Option<i16> { match number { Some(n) => Some(n * n), None => None, }
}
fn main() { // Enum içindeki bir değişken aşağıdaki gibi atanabilir let small = TaskSize::Small; // Bir görevi büyüklüğü ile tanımladığımız struct değişkeninin örnek tanımı
let install_git = Task { size: TaskSize::Medium, title: String::from("Ubuntu ortamına git kurulacak"), }; // Job enum tipinden bir değişkeni de aşağıdaki gibi oluşturabiliriz
let install_docker = Job::Small( String::from("Heimdall üstünde Docker kurulumu yapılmalı."),
5, ); // Action veri yapısı(ki enum tipidir) değişklenleri Task isimli struct'ı kullanıyor.
let micro_service = Action::Large(Detail { title: String::from("Müşteri modülünün mikro servise dönüşümü."), business_value: 13, }); /* Rust dilinde null yoktur. Ancak bazı hallerde verinin o an geçersiz olduğu ifade edilmek de istenebilir. Rust standart kütüphanesinde yer alan Option<T> isimli enum yapısı bir değerin var olduğunu veya olmadığını belirtmek için kullanılır.
Standart kütüphanedeki tanımlanma şekli şöyledir.(T, generic türdür) enum Option<T> { Some(T), None, } Some herhangi bir türde veri tutabilir. None kullanacağımız zaman tür belirtmemiz gerekir. */ let one = Some(1); let not_yet_valid: Option<f32> = None; // None kullanırken (yani null bir şeyler olduğunu ifade ederken) Option<T> ile henüz olmayan ama beklediğimiz verinin türünü de ifade etmemiz gerekir /* Yukarıda tanımlı VehicleEvent struct yapısının kullanımına ait örnek kodlar. process fonksiyonu pattern matchin ile parametre olarak gelen enum değişkenine göre bir aksiyon alınmasını sağlar(Örnekte basit olarak ekrana yazdırdık)
*/ let engine_on = VehicleEvent::StartEngine; process(engine_on); let fire_somewhere = VehicleEvent::Fire { x: 10, y: 16 }; process(fire_somewhere); let engine_of = VehicleEvent::StopEngine; process(engine_of); /* Option<T> ile enum sabiti kullanımı örnekleri. */ let result = square(Some(10)); // Option<i16> türünden bir değer gönderdik let none_result = square(None); // Bu durumda square fonksiyonundaki match bloğundaki none koşulu icra olur let myNum = Some(5); is_your_luck_day(myNum); is_your_luck_day(Some(23)); is_your_luck_day(None);
}
/* Mesela kullanıcı 23 girerse şanslı günündedir. Diğer sayılar içinse değildir.
23 olma haline Some(23) ile kontrol edebiliriz. Diğer haller içinse _ operatörü kullanılır
*/
fn is_your_luck_day(number: Option<i16>) { // match number { // Some(23) => println!("Şanslı günündesin"), // _ => println!("{:?} Büyük talihsizlik", number), // Option ile gelen değeri yazdırmak için :? söz dizimini kullandım
// } // Bu arada yukarıdaki ifade şu şekilde de yazılabilir
if let Some(23) = number { println!("Şanslı günündesin") } else { println!("{:?} Büyük talihsizlik", number) }
}Koleksiyonlar
Her ne kadar Rust'ın built-in pek çok veri tipi stack bellek bölgesini kullanıyor olsa da koleksiyonlardaki gibi heap'de tutulan, dolayısıyla derleme zamanında ne kadar yer tutacağının bilinmesine gerek duyulmayan veri tipleri de mevcuttur. Koleksiyon türlerinin kabiliyetleri farklılık göstermekle birlikte duruma göre tercih edilirler. Rust dilinde en sık kullanılan koleksiyonlar belli türden değişkenlerden oluşan vector(minions'daki vector mü acaba :D ), karakter katarı koleksiyonu olan string ve key-value düzeninde çalışan hash map'tir.
use std::collections::HashMap; // HashMap kullanabilmek için eklendi
fn main() { /* vector tipi ile başlayalım.
İlk satırdaki tanımlanma şeklinden de anlaşılacağı üzere vector generic bir koleksiyondur. Sadece <T> ile belirtilen türde elemanlar barındırır.
Bir vector'ü new ile tanımlayabileceğimiz gibi macro ile de tanımlayabiliriz (! işareti olan fonksiyonlar) Tahmin edileceği üzere vector türü de varsayılan olarak immutable'dır.
Bu nedenle colors isimli vector'e push metodu ile yeni elemanlar ekleyebilmek için, mut ile mutable olarak işaretlenmesi gerekmiştir.
*/ let points: Vec<i32> = Vec::new(); // Şu anda i32 türünden elemanlar taşıyacak bir vector koleksiyonu tanımladık
{ // Elbette scope kanunları vector türü için de geçerlidir let mut colors = vec!["red", "green", "blue"]; // bu durumda vector'ün kullandığı tip sağ tarafa göre tahminlenir(infer) colors.push("purple"); //push sona eleman ekler colors.push("yellow"); colors.push("pink"); let last = colors.pop(); // pop ile son eklenen eleman elde edilir. aynı zamanda koleksiyondan da çıkartılır
println!("{:?}", last); } // şu andan itibaren colors ve içeriğindeki tüm veriler bellekten atılmıştır (drop) // iterator dizileri kolayca bir vector'e alınabilirler
let mut numbers: Vec<i32> = (10..20).collect(); let x = numbers[5]; // vector içindeki herhangi bir elemana indis değeri üstünden erişebiliriz
println!("{}\n", x); // iter fonksiyonundan yararlanarak vector elemanları kolayca dolaşılabilir
// for n in numbers.iter() { for n in &numbers { // & operatörü ile vector referansını elde edip for ile ilerleyebiliriz print!("{},", n); } println!("\n"); /* Eğer iterasyon sırasıdan koleksiyon elemanlarında değişiklik yapmak isterse iter_mut fonksiyonundan yararlanabiliriz Tabii aşağıdaki kodun çalışabilmesi için numbers isimli vector'ün değişikliğe izin vermesi de gerekir. Bu nedenle numbers mut ile mutable hale getirilmiştir
*/ for n in numbers.iter_mut() { *n += 10; // vector'de o an referans edilen değeri değiştirmek için *(dereference) operatörünü kullanıyoruz
} println!("{:?}", numbers); /* vector'leri pattern matching tadından aşağıdaki gibi değerlendirebiliriz.
get ile 1nci indisi ele alıyoruz.
get fonksiyonu Option<T> döndürdüğü için Some, None durumlarını ele alabiliriz. */ match numbers.get(1) { Some(21) => println!("1 indisine denk gelen eleman {}", numbers[1]), None => println!("Hayır değil"),
_ => println!("Diğerleri için bir şey yapmaya gerek yok"), // 21 olma ve olmama durumu haricinde diğer durumları da kontrol etmemiz beklenir. Buraya yazmazsak derleme zamanı hatası alırız.
}; /* vector türü tek tiple çalışacak şekilde tanımlanmıştır.
Eğer farklı veri türlerinden bir nesne koleksiyonu olarak kullanmak istersek enum veri yapısını kullanabiliriz. Product enum veri yapısını bu amaçlar ele alabiliriz. Eğer çalışma zamanında vector'ün tutacağı veri türleri belli değilse enum yerine trait nesneleri kullanabiliriz. */ let data_row = vec![ Product::Id(1001), Product::Title(String::from("12li Su Bardağı")),
Product::ListPrice(12.90), ]; /* Gelelim Rust standart kütüphanesi ile birlikte gelen diğer bir koleksiyon olan String'e. String'i aslında byte'lar koleksiyonu olarak düşünmek daha doğru olabilir. String'in birkaç oluşturulma şekli var. Örneğin new ile tanımlanıp literal bir string üstünden to_string çağrısı ile ya da from fonksiyonu ile üretilebililir. String veri türü UTF-8 formatında kodlanmış içerikleri kullanabilir. Bu sebepten whatsup değişkeninde olduğu gibi pek çok dili destekler. String'leri birleştirmek veya bir String'e başka bir String parçası eklemek için push_str ve tek bir karakter eklemek için push fonksiyonlarını kullanabiliriz. Tabii + operatörü de String'leri birleştirmek için kullanılabilir.
Çok fazla birleştirilecek String varsa + operatörü (ki add fonksiyonuna karşılık gelir) yerine, format! isimli macro'yu kullanmak daha uygundur. */ let mut aloha = String::new(); // aşağıda değerini değiştireceğimiz için mutable yaptık
let incoming_data = "Alofortanfane"; aloha = incoming_data.to_string(); println!("{}", aloha); let raining_day = String::from("Một ngày mưa.");
println!("{}", raining_day); let mut quote = String::from("Siz ne kadar veri üretirseniz"); quote.push_str(", organize suç örgütleri de o kadar tüketir"); quote.push('!'); println!("{}", quote); quote.push_str(" Marc Goodman - Geleceğin Suçları");
println!("{}", quote); /* + operatörünü kullandığımızda & ile referans adreslerine ulaşmamız gerekir. Bunun sebebi aslında + operatörünün işaret ettiği add metodunun (fn add(self, s: &str) -> String şeklinde yazılmıştır)
&str şeklinde referans istemesidir. */ let s1 = "Ne".to_string(); let s2 = String::from("güzel"); let s3 = String::from("bir"); let s4 = String::from("gün!"); let last_word = s1 + " " + &s2 + " " + &s3 + " " + &s4; //s1'e sırasıyla s2, s3 ve s4 değişkenlerinin referans adresleri eklendi println!("{}", last_word); let black = String::from("black"); let white = String::from("white"); let black_and_white = format!("{} {} {}", black, "or", white); println!("{}", black_and_white); /* String veri türünde uzunluk aslında kullanılan karakterlerin byte olarak kapladıkları yere göre değişir.
Eğer Unicode karakter varsa bu UTF-8 kodlaması sonucu 2 byte olarak ele alınır ve uzunluk değişir.
Belki de bu sebepten ötürü String türünde indis operatörü kullanılamaz.
*/ let siyah = "đen";
println!( "Siyah vietnamca `{}` olarak yazılır. Rust için uzunluğu {}. Halbu ki sen 3 karakter saydın :)", siyah, siyah.len() ); // let second = siyah[1]; // the type `str` cannot be indexed by `{integer}` hatası döner /* Bir String içinden belli bir dilimi almak (slice) mümkündür ancak dikkat etmek gerekir. Çünkü denk gelen byte bir karakter olarak ifade edilemeyebilir. Aşağıdaki kod parçası derlenecektir ama çalışma zamanında bir panic oluşacaktır.
thread 'main' panicked at 'byte index 1 is not a char boundary; it is inside 'đ' (bytes 0..2) of `đen`'
*/ // let a_bit_off_word = &siyah[0..1]; // println!("{}", a_bit_off_word); /* String içerisindeki karakterleri veya byte'ları dolaşmanın en güzel yolu chars ve bytes fonksiyonlarından yararlanmaktır
*/ println!(); let rusca_bir_seyler = String::from("Добрый день умереть.");
for c in rusca_bir_seyler.chars() { print!("{} ", c); } println!(); for b in rusca_bir_seyler.bytes() { print!("{} ", b); } println!(); /* String ile başka neler yapabiliriz bakalım.
Mesela String içindeki karakterleri bir vector'e indirebiliriz. */ let char_vector: Vec<char> = rusca_bir_seyler.chars().collect(); for c in char_vector { println!("`{}` ", c); } /* Biraz da key:value mantığında çalışan Hash Maps türüne bakalım.
HashMap<Key,Value> şeklinde bir generic tip olarak düşünebiliriz sanırım.
Yeni elemanlar eklemek için insert fonksiyonunu kullanabiliriz. Bir key'in karşılığı olan value içeriğini değiştirmek için de yine insert fonksiyonu kullanılabilir.
*/ let mut agent_codes = HashMap::new(); agent_codes.insert(7, String::from("James Bond")); agent_codes.insert(23, String::from("Jean Claude Van Damme")); agent_codes.insert(66, String::from("Lord Vather")); agent_codes.insert(32, String::from("Larry Bird")); agent_codes.insert(32, String::from("Ervin Magic Jhonson")); // Aynı key üstüne yeni değeri yazdık
// agent_codes.remove(&7); // key:7 olan satırı HashMap'ten çıkartmış olduk // key değeri 7 olan value içeriğini almak için aşağıdaki gibi ilerleyebiliriz let key7 = 7; let bond = agent_codes.get(&key7); // Option<T> döndürür println!("{:?}", bond); // HashMap içindeki key:value çiftlerine aşağıdaki gibi erişebiliriz
// Bu arada liste hashcode değerlerine göre sıralanır
for (k, v) in agent_codes { println!("{} {}", k, v); } /* Bir HashMap'in key:value değerleri vector'lerden de oluşturulabilir.
Aşağıdaki stat ve beğeni oranlarının tutulduğu HashMap nesnesi, iki farklı vector ile oluşturulmuştur.
*/ let stads = vec![ String::from("Jüseeppe Meyaza"), String::from("Vodafon Park"), String::from("Noy Kamp"), String::from("Stat dö fırans"),
]; let fun_scores = vec![58, 90, 95, 72]; let stad_fun_scores: HashMap<_, _> = stads.into_iter().zip(fun_scores.into_iter()).collect(); for (stad, score) in stad_fun_scores { println!("{}:{}", stad, score); } // println!("{:?}", stad_fun_scores); // Yukarıda for döngüsünde kullandığımız için stad_fun_scores artık scope dışında kaldı. Dolayısıyla bu satır derleme zamanı hatası verir
}
enum Product { Id(i32), Title(String), ListPrice(f32),
}Hata Yönetimi(Error Handling)
Rust yönetimli bir dil olmadığından aşina olduğumuz gibi bir Exception Manager sistemi bulunmuyor. Bir nevi tek başınayız diyelim. Ancak bu bir dezavantaj olarak görülmemeli. Lakin daha titiz ve dikkatli(defansif diyebiliriz belki) olmaya zorluyor.
use std::fs::File;
use std::io;
use std::io::Read;
/*
Hata yönetimi. Rust dili hataları iki kategoriye ayırıyor. Kurtarılabilir olanlar(recoverable) ve tabii ki kurtarılabilir olmayanlar(unrecoverable) Managed bir ortam olmadığını da biliyoruz. Dolayısıyla bir exception yönetim sistemi de bulunmuyor. Kurtarılabilir hatalarda kullanıcının uyarılması ve yeniden deneme yapılması mümkün. Kurtarılamayan hatalar ise tipik olarak çalışma zamanı bug'ları gibi düşünülüyor. Rust, kurtarılabilir hataların kontrolü için Result<T,E> tipini değerlendirmekte.
Kurtarılamayan hatalar ise aslında ortamda bir panik havasının esmesi ve programın çalışmasının durması demek. Bu noktada, panic! makrosu ile karşılaşıyoruz. Hiç beklenmeyen ve geliştiricinin öngöremediği bir hata oluştuğunda çalışan panic! makrosu stack'i de temizleyip programın bir hata mesajı ile sonlanmasını sağlıyor.
Winding: panic! makrosu çalıştığında rust ortamı çağırılan ne kadar fonksiyon varsa bunları takip ederek stack üzerinde bellek temizleme operasyonu icra eder. Tahmin edileceği üzere bu operasyon maliyetlidir. Eğer üretim ortamı dosyası hafifse winding devre dışı bırakılabilir ki buna Unwinding deniyor. Geliştirici olarak hangi durumda tekrar deneme yaptırılması yani hatadan dönülmeye çalışılması ve hangi durumda sürecin durdurulmasının kararını verebilmek gerekiyor.
*/
fn main() { // #1 Kendimiz de panik havası estirebiliriz // analyse_nickname(String::from("bam-bam")); // analyse_nickname(String::from("fck")); // #2 // a_little_bit_panic(); // Yukarıdaki ikinci çağrım nedeniyle zaten bir panic oluştu ve program sonlandı. Dolayısıyla bu satır işletilmez
// #3 // Aşağıdaki çağrı Propagating Error senaryosu için örnektir. let r = load_file(String::from("./Crgo.toml")); //./Cargo.toml ile de deneyin. Yani var olan metinsel bir dosyanın da okunabiliyor olması lazım
match r { Ok(content) => println!("{}", content), Err(e) => println!("Dosya okumada hata -> {}", e), } println!("\nYine biz işimize bakalım...\n");
// Şimdi burada ? operatörünün kullanıldığı çok daha kısa kod bloğu içeren fonksiyonu kullandık
let ct = load_file_content(String::from("nowhere.txt")); match ct { // Yine dönen içeriği ele aldık
Ok(s) => println!("{}", s), //Hata yoksa dosya içini ekrana basıyor
Err(e) => println!("Hata Bilgisi -> {}", e), // hata varsa error bilgisini yazdırıyoruz
} println!("\nHatayı kontrol altında tutuyoruz\n"); /* #4 Result<T,E> tipinin kullanışlı iki fonksiyonu vardır (unwrap ve except) unwrap, işlem başarılı ise Ok içinde ne dönmesi gerekiyorsa onu döner ve bir hata durumunda otomatik panic! makrosunu tetikletir. match deseni ile uğraşmaya gerek kalmaz. */ // let cargo_file = File::open("./Cargo.toml").unwrap(); // eğer dosya varsa File nesnesini döndürür. // let unknown_file = // File::open("olmayan.txt").expect("Bu dosya sistemde yok veya bozulmuş olabilir."); // // panic! makrosu çalışması halinde burada yazdığımız mesaj trace içeriğine alınacaktır.
// #5 Minik kod kırıntıları
let number = String::from("123"); // string değerin kullanıcıdan geldiğini düşünelim let numeric = number.parse::<i32>().unwrap(); // number i32'ye dönüştürülebiliyorsa numeric'e gelir, aksi durumda panic! çalıştırılır
println!("{}", numeric * 3); let levels = vec!["100", "200", "300", "Dörtyüz", "500", "Altıyüz"]; // Şimdi bu vector içeriğini i32'ye parse etmek istediğimizi düşünelim (Dörtyüze ve Altıyüze dikkat) // hataya neden olan kısımları dışarıda bırakıyoruz
let numeric_levels: Vec<_> = levels .into_iter() //vector için bir iterasyon çektik .map(|s| s.parse::<i32>()) // değerlerin her biri parser fonksiyonu ile i32'ye dönüştürülmeye çalışıyor
.filter_map(Result::ok) // bazı dönüşümler Error verecektir. Sadece Result<T,E> den Ok dönenleri .collect(); // topluyoruz println!("Results: {:?}", numeric_levels); // ve ekrana basıyoruz
}
/*
Fonksiyon, parametre olarak gelen dosyası açıp içeriğini geri döndürmek istemekte. Ancak sistemde olmayan bir dosya da söz konusu olabilir. Burada early return adı verilen hata kontrol senaryosu ele alınıyor. Yani bir hata oluştuğunda bunun bilgisi çağıran yere döndürülüyor. panic! çağrısı yerine hata mesajını object user'a veriyoruz.
*/
fn load_file(file_name: String) -> Result<String, io::Error> { let f = File::open(file_name); // dosyayı açmaya çalışıyoruz
// Pattern Matching ile Result<T,E> sonucuna bakıyoruz.
let mut f = match f { Ok(file) => file, // Dosya açılabildi, her şey yolunda. Aşağıda içeriğini okuyacağız
Err(error) => return Err(error), // Error oluştu ve bunu fonksiyonu çağırdığımız yerde ele alabiliriz }; let mut content = String::new(); // şimdi dosya içeriğini okumaya çalışıyoruz ve yine hata olma durumunu ele alıyoruz
match f.read_to_string(&mut content) { Ok(_) => Ok(content), // sorun yok ve Ok ile dosya içeriğini geriye dönüyoruz Err(error) => return Err(error), // sorun var geriye hata bilgisini verelim }
}
/*
Yukarıdaki dosya okuma ve içeriğini döndürme fonksiyonunun çok daha kısa hali aşağıdaki gibi. Ama tabii burada olmayan veya içeriği okunamayacak dosyalar Error dönecektir ? operatörünün kullanımına dikkat.
*/
fn load_file_content(file_name: String) -> Result<String, io::Error> { let mut content = String::new(); File::open(file_name)?.read_to_string(&mut content)?; Ok(content)
}
fn analyse_nickname(message: String) { if message == "fck" { panic!("Hey dostum, ne dediğinin farkında mısın?"); // Programı burada sonlandırıyoruz.
} else { println!("Bana `{}` dedin", message); }
}
fn a_little_bit_panic() { let points = vec![0..10]; // burada bir vector dizisi oluşturduk
println!("{:?}", points[11]); //ve burada da 11nci elemana ulaşmak istedik ki yok. Bu satırda panic! makrosu devreye girecektir
}ve çalışma zamanı. Önce bir kuple panic! havası,
![]() ardından Result<T,E> ile olayı kontrol altında tutma çabası.
ardından Result<T,E> ile olayı kontrol altında tutma çabası.
![]()
Generics
<T> .Net dünyasından aşina olduğumuz bir konu. Generic veri türleri özellikle kod tekrarının azaltılması noktasında çok işe yarıyor. Rust dilinde ağırlıklı olarak bu amaçla kullanılmakta.
/* sum_of_two isimli fonksiyonu ele alarak konuyu irdeleyelim. fonksiyon i16 tipinden iki sayıyı alıp toplamını geriye döndürüyor.
*/
use std::ops::Add;
fn sum_of_two(x: i16, y: i16) -> i16 { return x + y;
}
fn main() { // #1 let r1 = sum_of_two(1, 6); println!("{}", r1); /* Şimdi bu fonksiyonu aşağıdaki gibi çağırmayı denersek i16 türünden parametre beklediğine dair derleme zamanı hatası ile karşılaşırız.
Çözüm olarak sum_of_two'nun f32 türü ile çalışacak bir versiyonunu yazabiliriz ama bu kod tekrarının en canlı örneği olur. Bunun yerine generic bir fonksiyon da geliştirebiliriz (yani sum fonksiyonu) */ //let r2 = sum_of_two(1.2, 6.4); let r3 = sum(19, 4); let r4 = sum(3.14, 2.56); println!("{}\n{}", r3, r4); // Generic strcut kullanımı örneği
let cmp1 = Complex { r: 18, v: 1.56 }; println!("{}+{}i", cmp1.r, cmp1.v); let cmp1 = cmp1.change(); // let ile yapılan atamayı kaldırdığınızda aşağıdaki satır için bir hata alacaksınız. Sizce sebebi ne olabilir? println!("{}+{}i", cmp1.r, cmp1.v);
}
/*
Generic fonksiyon örneği.
sum fonksiyonu T türünden parametreler ile çalışıp yine T türünden sonuç döndürecek şekilde yazıldı.
Ancak dikkat edilmesi gereken bir nokta var. T'nin tanımlanmasında Add şeklinde başka bir ifade daha yer almaktadır. Buradaki Add bir Trait'tir. T tipinin sahip olması gereken bir davranışı(iki T nin toplanabilmesi özelliğini) belirtiyoruz. Eğer Add Trait'ini kullanmazsak T'nin T'ye eklenemeyeceğine dair bir hata mesajı alırız.
Trait'leri traits isimli örnekte ele alıyoruz.
*/
fn sum<T: Add<Output = T>>(x: T, y: T) -> T { return x + y;
}
/*
#2 Pek tabii bir struct içinde de ve hatta struct'a ait metotlarda da generic yaklaşımı kullanılabilir.
Aşağıdaki Complex isimli struct'ın alanları T ve U türündendir. Ne atarsak o. Complex sınıfına entegre edilen change metodu kompleks sayının gerçel ve sanal köklerinin yerini değiştirip yeni bir Complex türünü geriye döndürmektedir
*/
struct Complex<T, K> { r: T, v: K,
}
impl<T, K> Complex<T, K> { fn change(self) -> Complex<K, T> { Complex { r: self.v, v: self.r, } }
}Görüldüğü üzere generic türler kod tekrarının önüne geçmekte sıklıkla kullanılabilir. Struct ve ona uygulanan metotlar generic tasarlanabilir. Örnekte kompleks sayıların toplamı için bir trait bildirimine yer verilmiştir. Aslında var olan Add isimli trait(ki bir sözleşme tanımlar) generic Complex veri türü için yeniden programlanmıştır. Bir trait ile struct türleri için ortak davranış sözleşmeleri bildirebiliriz(tam olarak interface değil, tam olarak abstract sınıf da değil. Değişik bir şey :D )
Trait
Yeri gelmişken trait konusuna da kısaca bir deyinelim. Nesne yönelimli programlama tarafından gelen birisi için interface tipine benzetilebilir. Esasında struct türlerinin sahip olması istenen davranışları belirten metotların tanımlandığı bir sözleşmedir. Yani metotların neye benzeyeceğini tanımlar ve ortak bir deklarasyon sunar. Diğer yandan iş yapan fonksiyonlar da içerebilir. Bu açıdan da abstract sınıflarla benzerlik gösterir. Rust standart kütüphanesi birçok trait tanımı içerir. Add, Copy, Clone, Eq vb Bu davranışlar tahmin edileceği üzere kendi veri yapılarımız için yeniden programlanabilir(Üstteki kompleks sayı aritmetiğini hatırlayın) Konuyu aşağıdaki kod parçası ile biraz daha detaylı analiz edebiliriz.
use std::ops; // + operatörünü tekrardan programlamak için eklendi (#4ncü örnek)
/*
#1 Action isimli bir trait. İçinde iki fonksiyon tanımı yer alıyor.
Takip eden iki struct bu trait içerisindeki fonksiyonları kendilerine göre uyarlıyorlar.
*/
trait Action { fn initialize(&self, x: i32, y: i32); // Trait fonksiyonları &self parametresine sahip olmalıdırlar. Elbette, başka parametreler de içerebilirler ve geriye döndürebilirler. fn click(&self) { println!("varsayılan bir click davranışı olsun diyelim"); // Varsayılan bir davranış icra ettik. Eğer click ezilirse(override) burası devreye girmez }
}
struct Button { name: String,
}
struct Hyperlink { url: String,
}
impl Action for Button { // Button struct'ı için Action trait'inin uygulanacağını söylüyoruz ancak sadece initialize metodunu ezdik. // Tabii click fonksiyonunun varsayılan bir kod bloğu olmasaydı onu da burada ezmek zorundaydık
fn initialize(&self, x: i32, y: i32) { println!( "{} isimli düğme {}:{} noktasında oluşturuldu",
&self.name, x, y ); }
}
impl Action for Hyperlink { // Benzer şekilde Hyperlink struct'ı için de Action trait'inde belirtilen metotların uygulanacağının söylüyoruz fn initialize(&self, x: i32, y: i32) { println!("{} link kontrolü {}:{} noktasına eklendi", &self.url, x, y); } fn click(&self) { println!("Linke basılırsa {} adresine gidilir", &self.url); }
}
fn main() { let submit = Button { name: String::from("btnSubmit"), }; let go_home = Hyperlink { url: String::from("https://www.buraksenyurt.com"), }; submit.initialize(10, 20); submit.click(); go_home.initialize(15, 30); go_home.click(); /* #2 Şimdi gelelim trait'lerin güzel kullanımlarından birine. Yukarıdaki kullanım çok anlam ifade etmiyor çünkü. Bu nedenle on_load fonksiyonuna odaklanalım. Parametre olarak Action trait'ini uygulayan tipleri kabul etmekte. Dolayısıyla Action trait'ini implement eden struct değişkenlerini aynı fonksiyonu içinde ele almamız mümkün. */ on_load(&submit, 10, 20); on_load(&go_home, 20, 20); /* #3 Tabii bunun üzerine akla, "e o zaman trait türünü kullanan vector tanımlayıp n adet struct için aynı operasyonu tetikleyelim" düşüncesi gelir Lakin trait'lerin boyutu yoktur ve bu nedenle bellekte ne kadar yer tutacakları bilinemez. Dolayısıyla düşündüğümüzü yapmak biraz beyin yakar. */ println!(""); let main_page = Hyperlink { url: String::from("azondot.com"), }; let controls: Vec<Box<dyn Action>> = vec![ Box::new(Button { name: String::from("help_me"), }), Box::new(main_page), Box::new(Button { name: String::from("next_page"), }), ]; // Box struct'ı heap'teki yer ayırımları için bir referans sunar. prepare(controls); /* #4 Operator Overloading C# taki gibi Rust dilinde de bilinen operatörleri yeniden programlayabiliriz. Örneğin kompleks sayıları temsil eden bir struct için + operatörünü yeniden programlamak istediğimizi düşünelim. + operatörünün karşılığı olan trait'i (Add) bu struct için yeniden programlamak yeterli olacaktır.
*/ let cx1 = Complex { x: 1.23, y: 2.56 }; let cx2 = Complex { x: 0.45, y: -4.89 }; let cx3 = cx1 + cx2; println!("{} + ({})i", cx3.x, cx3.y); /* #5 Operator Overloading(drop) Bu arada değişkenlerin scope dışına çıktıları zaman devreye giren ve bellek boşaltma işini üstlenen drop'da bir trait'tir ve yeniden programlanabilir. */ let london = MongoConnection { server: String::from("localhost"), port: String::from("3001"), }; println!("{}:{}...", london.server, london.port); // london değişkenini kullandık ve scope dışında kaldı. Yazdığımız drop metodu devreye girecek
}
/*
prepare fonksiyonu Action trait'ini uyarlayan yapılardan oluşan bir vector kabul eder. Bu sebeple Button ve Hyperlink nesnelerini içeren bir vector dizisini parametre olarak verip herbiri için aynı fonksiyonun çalıştırılmasını sağlayabiliriz.
(Polymorphsym olabilir mi? Bir düşünelim)
*/
fn prepare(controls: Vec<Box<dyn Action>>) { let mut x = 5; let y = 10; for c in controls.iter() { // parametre ile gelen nesnelerin initialize fonksiyonu çalışır. Override edilmiş sürümleri c.initialize(x, y); x += 5; }
}
fn on_load<T: Action>(control: &T, x: i32, y: i32) { control.initialize(x, y);
}
/* Aşağıda on_load'un ilk versiyonu var. Yukarıdaki ise Trait Bound Syntax adı verilen sürümü. Bu versiyon tercih edilirse on_load'u çağırdığımız yerlerde Action değişkenleri için & kullanmamız gerekir.
*/
// fn on_load(control: impl Action, x: i32, y: i32) {
// control.initialize(x, y);
// }
struct Complex { x: f32, y: f32,
}
// Complex struct'ı için Add operatörünü yeniden programlıyoruz
impl ops::Add for Complex { type Output = Self; // Kendi türünü döndüreceğini söylüyoruz ki bu Complex tip oluyor // add operasyonunu yeniden tanımlıyoruz
fn add(self, c2: Complex) -> Self { Self { x: self.x + c2.x, y: self.y + c2.y, } }
}
/*
#5 için kullanılan kobay struct ve drop uyarlaması.
Mesela oluşturduğumuz MongoConnection nesnesi scope dışına çıktığında yapılmasını istediğimiz özel bir şeyler varsa, drop trait'inin yeniden programlayarak gerçekleştirebiliriz.
*/
struct MongoConnection { server: String, port: String,
}
impl Drop for MongoConnection { fn drop(&mut self) { println!( "{}:{} için belki bağlantı sonlandırma işini üstlenebiliriz.", self.server, self.port ); }
}İşte çalışma zamanından bir görüntü.
![]()
Lifetimes
Rust dilinde tüm referans türlerinin bir yaşam ömrü(lifetime) vardır. Değişkenlerde sıklıkla gündeme gelen scope kavramı ile lifetime birbirlerine benzer ama aynı şey değildirler. Bir fonksiyon lifetime referans ile dönüyorsa parametrelerinden en az birisinin de lifetime referans olması gerekir ve struct yapılarında referans türlü alanlar varsa lifetime annotation kullanmak gerekir. Konuyu aşağıdaki üç farklı örnekle inceleyeceğiz.
fn main() { /* #1 Önce lifetime nerede devreye girer anlamak lazım.
Aşağıdaki kod parçasını ele alalım. İç içe iki scope var. Bu kod derlenmeyecektir. */ { // ana scope let number; // henüz hiçbir şey atamadığımız bir değişken
{ // iç scope let stranger_thing = 1; number = &stranger_thing; // ve number değişkenine iç scope'daki stranger_thing değişkeninin referansını atadık
} // sorun şu ki tam bu noktada stranger_thing'in ömrü doldu. println!("{}", number); // ve bu nedenle number'ı kullanmak istediğimizde(ki halen ana scope içinde olduğu için kullanılabilir) `stranger_thing` does not live long enough şeklinde derleme zamanı hatası alırız
// bu derleme hatasının sebebi basittir. number, artık serbest kalmış bir bellek adresini kullanmaya çalışmaktadır
// Rust derleyicisi yukarıdaki senaryoda kapsamları kontrol ederken Borrow Checker isimli bir tekniğe başvurur
}
}Yukarıdaki örnek derlenmeyecektir ve aşağıdaki görüntüde yer alan hata mesajını verecektir.
![]()
Lifetime noktalarını daha iyi anlamak için aşağıdaki düzeni göz önüne alabiliriz.
fn main() { /* lifetime noktalarını daha iyi anlamak için şu kod parçasına bakalım.
x ve y, en fazla yaşam ömrü olan number değişkeninin referansını kendi yaşam süreleri boyunca ödünç alıp kullanıyorlar.
*/ let number = 3.14; //------------------------------------> number lifetime start { let x=&number; //--------------------> x lifetime start println!("{}",x); }//--------------------------------------> x lifetime end { let y=&number; //--------------------> y lifetime start println!("{}",y); }//--------------------------------------> y lifetime end
} //----------------------------------------------------------> number lifetime endŞimdi biraz daha zihnimizi yakalım ve generic lifetime parametreleri konusuna bakalım. İzleyen kod parçasında yer alan find_winner isimli fonksiyon Player tipinden iki referansı parametre olarak alır ve geriye yine bir Player referansı döndürür.
find_winner fonksiyonunun parametre olarak gelen Player değişkenlerini sahiplenmesini istemediğimizi düşünelim. Bu nedenle referans olarak geçmekteyiz. Lakin Rust derleyicisi ve özellikle Borrow Checker mekanizması bir kafa karışıklığı yaşayacaktır. p1'in mi yoksa p2'nin mi geriye döneceği belli değildir. Bu durumda find_winner'dan dönecek Player referansının(p1 veya p2 olabilir) ne kadar süre yaşaması gerektiği de belli değildir. p1'inki kadar mı ömrü olmalıdır, yoksa p2'ninki kadar mı? Bu durum derleyicinin "explicit lifetime required in the type of `p2`" benzeri bir hata uyarısı vermesi ile devam eder. Olayın önüne geçmek için generic lifetime parametrelerini kullanmak gereki. Böylece referanslar arası yaşam süreleri için bir ilişki kurulabilir.
struct Player { nick_name: String, total_point: i32,
}
// // lifetime hatası veren versiyon
// fn find_winner(p1: &Player, p2: &Player) -> &Player {
// if p1.total_point > p2.total_point {
// return p1;
// } else {
// return p2;
// }
// }
/*
'l lifetime'ın adıdır ve &'l Player, Player referansı için 'l kadarlık bir yaşam ömrü belirttiğimizi ifade eder. Bir başka deyişle referansın yaşam ömrünü açık bir şekilde belirtmiş oluruz. Bu yeni sürümde p1, p2 ve geriye dönen Player dahil olmak üzere 3 referansta aynı yaşam sürelerine sahiptir.
*/
fn find_winner<'l>(p1: &'l Player, p2: &'l Player) -> &'l Player { if p1.total_point > p2.total_point { return p1; } else { return p2; }
}
fn main() { let gustavo = Player { nick_name: String::from("Gustavo"), total_point: 18, }; let mikel = Player { nick_name: String::from("Mikel"), total_point: 17, }; let winner = find_winner(&gustavo, &mikel); println!("Kazanan `{}`", winner.nick_name); /* #2 Aşağıda yine enteresan bir yaşam ömrü sorunsalı yer almaktadır.
schumi ve race_winner iç scope dışında tanımlıdır. Toplam puanlara baktığımızda kazanan schumi'dir ve dolayısıyla,
#İlginç yazan yerde race_winner, schumi'nin referansını taşıyacağı için bir sorun olmaması beklenmektedir. Ne var ki find_winner fonksiyonu parametreleri ve geriye dönen Player referansı için aynı yaşam süresini beklemektedir. Koda göre #İlkÇıkış noktasında hakinen'in ömrü dolmaktadır. Yani schumi, hakinen ve kazanan için aynı yaşam döngüsü kuralı bozulmuştur.
Bu nedenle derleyici aşağıdaki kod parçası için `hakinen` does not live long enough diyecektir. */ let schumi = Player { nick_name: String::from("Schumi"), total_point: 77, }; let race_winner; { let hakinen = Player { nick_name: String::from("hakinen"), total_point: 60, }; race_winner = find_winner(&schumi, &hakinen); } // #İlkÇıkış
println!("Yarışın kazananı {}", race_winner.nick_name); // #İlginç
}
struct Game<'l> { // color_name: &str, // struct türünde referans türlü alanlarda kullanabiliriz ancak bu şekilde değil. lifetime bildirimi ile kullanabiliriz color_name: &'l str, max_player: i32,
}Birim Test
Aslında en başında her şeye test ile başlamamız gerekirdi. Çalışmakta olduğum Claus Matzinger'in Packt çıkışlı Rust Programming Cookbook kitabı daha ilk bölümden itibaren her şeyi test fonksiyonları ile birlikte ele alıyor. Hatta main fonksiyonu hiç yok diyebilirim. Sadece kütüphaneler ve birim testler var. Rust tarafında yeni bir kütüphane oluşturulduğunda otomatik olarak tests isimli bir modül de oluşturulur. Tüm birim testlerini bu modül içerisinde oluşturabiliriz. Zaten geliştireceğimiz kütüphanelerin beraberinde test modülü ve birim testleri ile birlikte yazılması kod kalitesi, temiz kod ve kod güvenilirliği açısından çok önemlidir.
/* Basit Unit Test yazmak cargo new testing --lib terminal komutu ile bir kütüphane açtığımızda içerisine otomatik olarak tests isimli bir modül açılır.
test etmek için terminalden cargo test komutunu çalıştırmak yeterlidir. Test fonksiyonları fail durumuna düştüğünde Rust çalışma zamanı bir panik havası estirir.
*/
#[derive(Debug)]
struct Player { nick_name: String, current_point: i32, attendance: i32,
}
impl Player { #[allow(dead_code)] fn calculate_score(&self, _median: f32) -> f32 { // 0.0 // Birinci durum ((self.current_point * self.attendance) as f32) * _median }
}
/*
İçinde bilinçli olarak exception fırlattığımız(pardon panic ürettiğimiz) fonksiyonlara ait testlerde, "ben zaten böyle bir exception olmasını istiyorum" diyebiliriz. #[should_panic] niteliği bunun için kullanılmaktadır.
Person struct'ı için yazdığımız new isimli metoda ait test fonksiyonunda bu durum irdelenmektedir. age alanının değerinin 13 ile 18 arasında olması istenmektedir. Eğer böyle değilse ortamda panik havası estirilir.
*/
#[derive(Debug)]
struct Person { name: String, age: i8,
}
impl Person { /// Person nesnesi üretme fonksiyonu /// /// Bir Person değişkenini, parametre olarak verilen /// isim ve yaş bilgileri ile oluşturur.
/// /// ## Examples /// /// ``` /// let p = Person::new(String::from("ben hur"), 19); /// assert_eq!(p._name, "ben hur"); /// ``` /// /// ## Panics /// /// Fonksiyona gelen _age parametresi 13 ile 18 aralığında değilse panic fırlatılır.
/// fn new(_name: String, _age: i8) -> Person { /* Aşağıdaki println çıktısı, cargo test ile testleri koşturduğumuzda ekrana çıktı olarak gelmez. Fonksiyonlardan terminale basılan çıktıları test sırasında da görmek istiyorsak, cargo test -- --show-output şeklinde bir terminal komutu kullanmamız gerekir. */ println!("Yeni bir personel oluşturulacak");
if _age > 18 || _age < 13 { panic!( "Bu oyun eğitim 13-18 yaş arası talebeler içindir. Girilen yaş `{}`", _age ); } else { Person { name: _name, age: _age, } } }
}
#[cfg(test)] // test modülü olduğunu belirttiğimiz nitelik (attribute)
mod tests { use super::*; // bu iç modülden diğerlerine erişebilmek için konuldu. Aksi durumda Player verisine erişemeyiz
#[test] // test fonksiyonu olduğunu belirttiğimiz nitelik fn should_calculated_player_score_positive() { let median_value = 0.08; let cai = Player { nick_name: String::from("cobra kai"), current_point: 44, attendance: 102, }; let expected_value = cai.calculate_score(median_value); assert!(expected_value > 0.0); // assert! makrosu ile kabul kriterimizi yazdık
} #[test] fn should_player_nick_name_length_grater_than_three() { let gretel = Player { nick_name: String::from("han"), attendance: 3, current_point: 1, }; let result = gretel.nick_name.len() > 3; /* assert! makrosunu aşağıdaki gibi de kullanabiliriz. Bu durumda test sonuçlarına belirttiğimiz metinsel içerik de yansıyacaktır.
Teste konu olan alanların ve hata sebebinin sonuçlarda görünmesini istediğimiz hallerde işe yarabilir. */ assert!( result, "Nickname 3 karakterden fazla olmalı. Girilen `{}`", gretel.nick_name ); } #[test] #[should_panic] // Beklediğimiz gibi panik ürettirirsek bu test OK cevabı alır. Aksine test panik ürettirmiyorsa Fail cevabını basar fn should_age_available_for_child() { let ben_hur = Person::new(String::from("ben hur"), 19); // editörde mouse imlecini new fonksiyonu üstünde tutun } /* Test fonksiyonlarının, kriterin ihlali sonucu panic oluşturması yerine Err döndürmesi de sağlanabilir.
*/ #[test] fn should_total_greater_than_ten() -> Result<(), String> { if 3 + 6 == 10 { Ok(()) } else { Err(String::from("Testi geçemedi. Abicim 3+6 10 olur mu?")) } } #[test] #[ignore] // ignore niteliği ile bir testi atladığımızı belirtiriz fn should_div_work() -> Result<(), String> { let x = 10.0; let y = 0.0; assert_eq!(div(x, y)?, 1.0); Ok(()) }
}
/*
kobay fonksiyonumuz geriye Ok veya Err döndürmekte. should_div_work isimli test fonksiyonunda bu fonksiyonun ? ile kullanıldığına dikkat edelim.
*/
fn div(x: f32, y: f32) -> Result<f32, String> { if y == 0.0 { Ok(x / y) } else { Err("Sıfıra bölme hatası".to_owned())
}
}Uygulamanın çalışma zamanı görüntülerini aşağıda bulabilirsiniz.
![]()
Testlerden biri başarılı diğeri değil durumuna ait bir görüntü.
![]()
Belli bir test maddesini çalıştırdığımız durumdaki görüntü.
![]()
/// ile kullanım talimatlarını eklediğimizde VS Code'daki yardım kutucuğunun içeriği.
![]()
Kendi Küfelerimizi Geliştirmek(Crate)
Birim test yazdığımız örnekte bir kütüphane kullandık. Aslında küfe veya sandık anlamına gelen ve Crate olarak isimlendirilen bu yapılarda erişilebilirlik, modül yerleşimi de önemlidir. mercury isimli kütüphanede bu konular ele alınmaktadır.
Örnek kütüphane kendi içinde entity, flight_opt ve reports isimli modüller içermektedir. mercury library içerisinde yer alan src/lib.rs aynı zamanda kök sandık(Crate root) olarak da adlandırılır. Yani crate anahtar kelimesi ile root'a erişip :: operatörü ile iç elementlere inebiliriz. flight_opt modülünde visitor_manager modülünde tanımlı Visitor struct'ını kullanmak için nasıl bir yol izlediğimize dikkat edin. Bunlardan birisi absolute path formatıdır ve Crate ile başlar.
Absolute path metodunda crate ile bulunduğumuz sandığı işaret etmekteyiz. :: sonrası bu sandık içerisindeki visitor_manager modülüne ve ardından gelen :: ile de Visitor isimli struct veri tipine ulaşıyoruz. Bu arada entity modülü içinde kullanılan pub anahtar kelimelerine de dikkat edelim. Normalde Visitor isimli struct ve alanları private niteliklidir ve flight_opt içerisinden erişilemezler. Bu nedenle pub ile genel kullanıma açık hale getirilmişlerdir. Bu arada flight_opt modülündeki save_visitor metodu içinden entity modülündeki Visitor struct'ına erişmek için super::entity:Visitor şeklindeki yazım notasyonu da kullanılabilir. super, aslında dosya sistemini düşünürsek ..'yı yani bir üst klasörü referans etmektedir.
cargo new --lib mercury
ve kodlarımız.
mod visitor_manager { pub mod entity { pub struct Visitor { pub fullname: String, pub ticket_no: String, } pub struct Spaceship { pub name: String, pub flight_no: i32, pub passenger_capacity: i8, } pub struct SpaceLocation(i32, i32, i32); } mod flight_opt { /* use ile flight_opt içerisinde kullanmak istediğimiz modül elemanlarını bir kere tanımlayıp
yola devam edebiliriz. Yani SpaceLOcation kullanmak istediğimiz her yerde Absoulte path veya relative path ya da super kullanarak uzun formatta bildirim yapmak zorunda değiliz.
Hatta as ile takma ad(alias) da verebiliriz. Mesela send_spaceship metodundaki target parametresi için SpaceLocation yerine location ifadesi kullanılabilir.
*/ use crate::visitor_manager::entity::SpaceLocation as location; fn save_visitor(name: String, ticket: String) { let v = super::entity::Visitor { fullname: name, ticket_no: ticket, }; // let v = crate::visitor_manager::entity::Visitor { // //absoulute path tekniği
// fullname: name, // ticket_no: ticket, // }; println!( "{} isimli ziyaretçi için merkür yolculuk kaydı açıldı. Bilet numarası {}", v.fullname, v.ticket_no ) } fn send_spaceship(name: String, no: i32, capacity: i8, target: location) {} } mod reports { fn get_total_visitor(region: String) -> i32 { // Merkürdeki üs bazında yolcu sayısını döndürüyor. Mesela :) return 1000; } }
}Bu örnekte tek bir Crate söz konusu ancak içerisinde dikkat edileceği üzere çeşitli seviylerde modüller var. Geliştirdiğimiz kütüphaneleri başka Rust uygulamalarımızda kullanmak isteyebiliriz.Şimdi process-management isimli bir kütüphane geliştirelim ve onu nortrop-client isimli başka bir Rust uygulamasında kullanmaya çalışalım.
/* Oluşturmak için: cargo new process-management --lib Çalıştırmak için cargo test Bir Rust uygulamasının başka bir rust kütüphanesini nasıl kullanır?
nortrop-client bu caret olarak isimlendirilen kütüphaneyi kullanmaya çalışacak.
pub, yani genele erişime açık yapıları diğer uygulamadan kullanmaya çalışacağız.
*/
/*
Rastgele sayı üretmek için kullanacağımız harici sandık (external caret) Bunun için bu kütüphanin Cargo.toml dosyasına gerekli dependency tanımını eklemeliyiz. cargo test ile kodu test etmek üzere çalıştırdığımızda bu bağımlılık paket önbelleğine indirilir ve kullanılır hale gelir.
*/
use rand::Rng;
#[derive(Debug, PartialEq)] //Soru: Neden Debug ve PartialEq trait'leri eklendi?
pub enum ProcessType { Small, High,
}
/*
Kobay find_process _type fonksiyonu level değerine göre geriye ProcessType enum türünden bir değer dönmekte.
*/
pub fn find_process_type(level: u32) -> ProcessType { if level < 500 { ProcessType::Small } else { ProcessType::High }
}
/*
Bu da süreç tipi ve parametre sayısına göre tahmini işlem süresini hesaplayan bir fonksiyon. Hayali olarak tabii... Fonksiyonda match ile p_type'ın değeri kontrol ediliyor ve buna göre bir ağırlık puanı belirleniyor. İlgili ağırlık puanı 0 ile 10 arasında olan rastgele bir sayı ile işleme tabi tutulup geriye bir değer döndürüyor.
*/
pub fn calc_estimated_time(p_type: ProcessType, parameter_count: u8) -> u16 { let weight = match p_type { ProcessType::High => 5_u8, ProcessType::Small => 1_u8, }; let mut randomizer = rand::thread_rng(); let result = (randomizer.gen_range(0, 10) * parameter_count) + weight; u16::from(result) //Soru: Neden burada result değerini u16 türüne dönüştürdük?
}
#[cfg(test)]
mod tests { use super::*; //tests modülünün üstünde bulunan get_process ve benzer fonksiyonlara erişebilmek için eklenmiştir
/* 500 altı değerler için ufak süreç olduğu dönmeli testi */ #[test] fn should_return_small_less_than_500() { let result = find_process_type(459); assert_eq!(result, ProcessType::Small); } /* 500 üstü değerler içinse yüksek hesaplamalı bir süreç olduğunu öğrenme testi */ #[test] fn should_return_high_greater_than_500() { assert_eq!(find_process_type(501), ProcessType::High); } #[test] fn should_estimated_time_be_positive() { // Bu kez kabul kriterimiz eşitlik değil bir boolean işlem sonucu assert!(calc_estimated_time(ProcessType::Small, 3) >= 1) }
}Şimdi de bunu kullanacak olan nortrop-client isimli bir rust client projesi oluşturalım. Toml dosyasındaki dependencies kısmında, kullanacağımız harici kütüphaneyi işaret etmemiz gerektiğine dikkat edelim.
[package]
name = "nortrop-client"
version = "0.1.0"
authors = ["buraksenyurt "]
edition = "2018"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
process-management = {path='../process-management',version='*'}Buradaki bildirime göre process-management fiziki konum olarak nortrop-client ile aynı klasör seviyesindedir. nortrop-client içerisinde kullanılan kobay türünde bir Crate'imiz de var. Kobay task_manager modülünün amacı crate prefix'i ile dahili bir modülün nasıl kullanılabildiğini göstermektir. Modülün main.rs içerisindeki manager modülü tarafında nasıl kullanıldığına dikkat edelim.
pub fn start(id: i32) -> i32 { println!("{} numaralı görev çalıştırıldı", id); id
}
#[cfg(test)]
mod tests { use super::start; #[test] fn run_task_should_return_ten_for_ten() { assert_eq!(start(1), 1); }
}main içeriğini ise şu şekilde kodlayabiliriz.
/* Oluşturmak için: cargo new nortrop-client Çalıştırmak için: cargo run Testleri için: cargo test Bulunulan yer(main.rs in olduğu) root module olarak adlandırlır.
nortrop-client uygulaması yine bizim yazdığımız process-management isimli caret'ı kullanmaktadır.
Bunun için Cargo.toml dosyasında bir dependency tanımı mevcuttur. Ana fonksiyondaki invoice_process çağrısı manager isimli dahili modüle yapılmaktadır.
manager modülü de dikkat edileceği üzere process-management(caret/sandık) içerisindeki tüm public enstrümanları kullanabilmektedir. manager modülü aynı zamanda main.rs ile aynı klasörde yer alan task_manager.rs içindeki modülü de kullanmaktadır.
*/
mod task_manager; // internal modülü kullanabilmek için gereken bildirim
//Soru: Yukarıdaki modül bildirimini yapmazsak ne olur?
use manager::invoice_process;
fn main() { invoice_process(450); invoice_process(650);
}
mod manager { use process_management::*; /* internal task_manager içerisindeki start fonksiyonunun kullanılacağını belirtir crate üstünden internal modüllere kolaylıkla erişilebilinir
*/ use crate::task_manager::start; pub fn invoice_process(level: u32) { let process_type = find_process_type(level); let estimated_time = calc_estimated_time(process_type, 10); println!( "{} puanlı süreç için tahmini tamamlanma süresi {} uzay zamanıdır.",
level, estimated_time //Soru: point yerine process_type değişkenini kullanabilir miyiz? ); start(192); start(204); }
}Basit Bir Komut Satırı Programı
Buraya kadar epey kavram biriktirdik. Şimdi işe yarar bir uygulama kodu geliştirmeye ne dersiniz? Amacımız aşağıdaki içeriğe sahip bir dosyayı parse edecek komut satırı aracını geliştirmek.
1000|A3 Kağıt (1000 Adet)|100|45
1001|Sıtabilo 12li renkli kalem|150|50
1002|Kareli bloknot|15|20
Bunun için reader isimli bir Rust uygulaması oluşturalım ve aşağıdaki gibi kodlayalım.
// Gerekli ortam kütüphaneleri
use std::env; // argümanları okurken
use std::error::Error;
use std::fmt;
use std::fs;
use std::process;
fn main() { let args: Vec<String> = env::args().collect(); // ekrandan girilen argümanları String türünden bir vector dizisine aldık
/* unwrap_or_else fonksiyonu Non-Panic stilde çalışır.
Aslında burada bir closure kullanımı da söz konusu. Dikkat edileceği üzere unwrap_or_else isimsiz bir fonksiyon çağırıyor ve bunu new'dan Err dönmesi halinde çalıştırıyor.
Eğer new Ok dönerse kod akışı devam edecektir */ let prmtr = Parameter::new(&args).unwrap_or_else(|err| { println!("{}", err); process::exit(1); // Uygulamadan çıkartır
}); println!( "`{}` dosya içeriği için `{}` işlemi yapılacak\n",
prmtr.filename, prmtr.command ); // ürün listesini çekiyoruz let products = read_product_lines(prmtr).unwrap_or_else(|e| { println!("Kritik hata: {}", e); process::exit(1); }); for p in products { println!("{}", p); // Product struct'ına Display trait'ini implemente ettiğimiz için bu ifade geçerlidir. }
}
/*
Terminalden gelen agrümanları Parameter isimli bir struct'ta toplayabiliriz. Ayrıca doldurulması için de bir constructor kullanabiliriz. (new metodu)
*/
struct Parameter { command: String, filename: String,
}
impl Parameter { // Constructor fn new(args: &[String]) -> Result<Parameter, &'static str> { /* Ekrandan girilen argüman sayısını kontrol edelim. Aslında iki parametre isterken 3 tane kontrol etmemiz tuhaf değil mi? Nitekim cargo kelimesinden sonra gelen run komutu da terminal argümanı sayılıyor.
Yani run komutundan sonra gelen argümanları ele alacağız.
*/ if args.len() != 3 { return Err("Argüman sayısı 2 olabilir"); // Panic yerine Error mesajı döner } let command = args[1].clone(); let filename = args[2].clone(); Ok(Parameter { command, filename }) // Sorun yoksa Parametre örneği döner }
}
/*
read_lines fonksiyonu argümanların toplandığı Parameter struct'ını kullanır ve dosya içeriğini satır satır okur. Bu fonksiyonda non-panic stilde yazılmıştır.
Geriye Ok veya hata durumuna göre Error trait'ini uygulayan hata referansları dönebilir. Ne tür bir hata döneceğini bilemediğimiz için dynamic trait kullanılmıştır.
?'te panic yerine Ok veya Error durumlarını döndürmektedir.
*/
fn read_product_lines(prmtr: Parameter) -> Result<Vec<Product>, Box<dyn Error>> { let content = fs::read_to_string(prmtr.filename)?; let mut products: Vec<Product> = Vec::new(); // doğrudan content içeriğini lines fonksiyonu ile okuyoruz ve satır satır dolaşabiliyoruz
for row in content.lines() { // pipe işaretine göre satırı parse edip sütunları bir vector içinde topluyoruz let columns: Vec<&str> = row.split("|").collect(); // yeni bir Product değişkeni oluşturup alanlarını atıyoruz
let prd = Product { id: columns[0].parse::<i32>().unwrap(), description: String::from(columns[1]), price: columns[2].parse::<f32>().unwrap(), quantity: columns[3].parse::<i32>().unwrap(), }; // ve products isimli vector dizisine ekliyoruz products.push(prd); } Ok(products) // Buraya kadar sorunsuz geldiysek ürün listesini tutan vector'ü geriye dönüyoruz
}
struct Product { id: i32, description: String, price: f32, quantity: i32,
}
/* Display trait'ini Product struct'ımız için uyguluyoruz. Böylece println! makrosunda buradaki formatta ekrana bilgi yazdırılması mümkün.
*/
impl fmt::Display for Product { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!( f, "[{}] - {}. Birim Fiyat {}. Stokta {} adet var.", self.id, self.description, self.price, self.quantity ) }
}İşte çalışma zamanı çıktımız.
![]()
Kapamalar(Closures)
Rust fonksiyonları değişkene atama, başka fonksiyonlara parametre olarak geçme, fonksiyondan fonksiyon döndürme ve benzeri birçok fonksiyonel dil özelliğini bünyesinde barındırır. Özellikle closure, iterator, pattern matching Rust'ın öne çıkan fonksiyonel dil yetenekleridir. Sıradaki kodlarda Closure konusunu anlamaya çalışacağız. Closures isimsiz fonksiyon olarak düşünülebilir. Parametre olarak fonksiyonlara aktarılabilirler veya bir değişkende tutulabilirler. Değişkenlere atanabilmeleri bir yerde tanımlanıp tamamen farklı bir context içerisinde kullanılabilmelerine olanak sağlar.
fn main() { /* #1 Basit Closure örnekleri ile başlayalım.
*/ // Örneğin isimsiz bir fonksiyonu bir değişkende tutabilir ve kod akışına göre çağırılmasını sağlayabiliriz
let div = |x: f32, y: f32| -> f32 { if y == 0.0 { panic!("SIfıra bölme sorunu") } x / y }; println!("10/2.4={}", div(10.0, 2.4)); // div değişkenine atanmış fonksiyonu çağırdık
/* Tabii yukarıdaki kullanımın bir fonksiyon çağırımı ile neredeyse aynı olduğunu ifade edebiliriz. Ancak closure'ları fonksiyonlara parametre olarak geçebilmek veya döndürebilmek önemli bir avantajdır.
Şimdi buna bakalım.
call fonksiyonu generic tanımlanmıştır ve F için Fn trait'i ile ifade edilmiştir. Buna göre f32 tipinden parametre alan ve yine f32 türünden değer döndüren closure'lar call fonksiyonuna yollanabilir. closure'ları parametre olarak geçerken FnOnce, FnMut ve Fn trait'lerine ihtiyacımız vardır nitekim bir closure bunlardan en az birini uyarlamak zorundadır(Generic kullanımlarda bu önem kazanıyor)
*/ call(div, 3.2, 9.4); /* Closure tanımlarken dönen türü belirtmek zorunda değilizdir.
Rust derleyici bunu tahmin eder. Ancak burada dikkat edilmesi gereken bir durum vardır.
Aşağıdaki tanımlamaya dikkat edelim. do_something türü belli olmayan value isimli bir parametre alıyor ve bunu aynen geriye döndürüyor. */ let do_something = |value| value; let summary = do_something(3); // Burada tipi tahmin etti ve artık i32 ile çalışacağı belli oldu println!("{}", summary); //let other_summary = do_something(3.1415); // Bu satırda ise kod derlenmeyecektir. "expected integer, found floating-point numberrustc(E0308)" // Çünkü ilk kullanımla birlikte do_something fonksiyonunun çalışacağı tür i32 olarak belirlenmiştir
/* Game struct'ının closure ile birlikte kullanımı.
new(constructor)'a bir fonksiyon aktardık. Artık içerideki find_medal fonksiyonu bu fonksiyonu baz alarak çalışacak
*/ let mut blizard = Game::new(|point| point + 1); println!("{:?}", blizard.find_medal(18)); println!("{:?}", blizard.find_medal(32)); // blizard.medal_calculator = |p| (p + 10 / 2); // println!("{:?}", blizard.find_medal(16)); /* Closure'ları fonksiyonlardan ayıran bir özellik de, bulundukları kapsamdaki değişkenlere erişebiliyor olmalarıdır.
Aynen aşağıdaki örnekte olduğu gibi. Tabii bu durumda closure'un çevreden çektiği değişkeni sahiplenmesi söz konusudur ki bu da bellekte bu değişkenler için yer ayırdığı anlamına gelir. Performans açısından dikkat edilmesi gereken bir durum. */ let some_number = 10; let process_function = |n: i32| n + some_number; // isimsiz fonksiyon içerisinde yukarıda tanımlı (main scope'una dahil) some_number değişkenine erişilmiştir
let processed = process_function(5); println!("{},{}", processed, some_number); /* Yukarıda closure ile yaptığımız şeyi aşağıdaki gibi yapamayız.
Derleyici "can't capture dynamic environment in a fn item" şeklinde hata verecektir */ // let another_number=11; // fn add(nbr: i32) -> i32 { // nbr + another_number // }; /* Bu arada process_function kullanımı ile ilgili olarak şunu da öğrendim gibi. Closure'un çevre değişkenleri sahiplenmesi 3 Trait ile mümkün oluyor. Fn, FnMut ve FnOnce process_function, some_number'ı sadece okuduğu için Fn Trait'ini uygular. Ama kod bloğunda some_number'ı değiştirip kullanmak istersek aşağıdaki gibi bir yol izlememiz gerekir ki bu durumda FnMut Trait'i devreye girer.(mut kullanımlarına dikkat) */ let mut some_number2 = 10; let mut process_function2 = |n: i32| { some_number2 += 1; n + some_number2 }; let processed2 = process_function2(5); println!("{},{}", processed2, some_number2); /* Bir closure farklı bir thread'e alınırken sahiplendiği verinin de mutlak suretle taşınmasını istersek move komutunu kullanabiliriz. Bu durum Concurrency konusunda değer kazanacak. */ /* Fonksiyonlardan fonksiyon dönebileceğimizden de bahsetmiştik.
Aşağıda örnek bir kod yer alıyor.
get_fn fonksiyonu, parametre olarak gelen Enum türüne göre geriye Fn(i32,i32)->i32 türünden uygun fonksiyonu döndürüyor. Eğer toplama işlemi yaptırmak istersek toplama, çarpma yaptırmak istersek de çarpma fonksiyonu gibi... */ let now_what = get_fn(Process::Division); println!("Division {}", now_what(16, 4)); let now_what = get_fn(Process::Extraction); println!("Extraction {}", now_what(12, 6));
}
// Geriye fonksiyon döndüreceğimiz için impl Fn gibi tanım yaptık (FnMut, FnOnce da söz konusu olabilir tabii)
fn get_fn(process: Process) -> impl Fn(i32, i32) -> i32 { // match ile process enum durumlarına bakıyoruz
// ve uygun bir fonksiyonu geriye döndürüyoruz. Süper değil mi? match process { Process::Addition => |x, y| x + y, Process::Multiplication => |x, y| x * y, Process::Division => |x, y| { if y == 0 { panic!("Sıfıra bölme durumu"); } else { x / y } }, Process::Extraction => |x, y| x - y, }
}
enum Process { Addition, Multiplication, Extraction, Division,
}
fn call<F>(closure: F, a: f32, b: f32)
where F: Fn(f32, f32) -> f32,
{ let result = closure(a, b); println!("{}", result);
}
/*
Closure'ları parametre olarak geçebildiğimizden bahsediyoruz. Örneğin bir Struct'ın bir alanını da closure olarak tanımlayabiliriz.
Game isimli generic struct i32 tipinden değer alıp yine i32 türünden değer döndüren bir fonksiyonu medal_calculator alanında taşıyacak şekilde tanımlandı.
new(constructor) fonksiyon parametre olarak gelen fonksiyonu medal_calculator alanına atıyor.
find_medal fonksiyonunda ise gelen argüman değeriner göre closure fonksiyonunu çağırıyor.
Struct'a atanan hesaplama fonksiyonu ne ise (medal_calculator'a atanan fonksiyon) o icra ediliyor.
*/
struct Game<T>
where T: Fn(i32) -> i32,
{ medal_calculator: T, current_point: i32,
}
impl<T> Game<T>
where T: Fn(i32) -> i32,
{ fn new(calc: T) -> Game<T> { Game { medal_calculator: calc, current_point: 0, } } fn find_medal(&mut self, arg: i32) -> i32 { let value = (self.medal_calculator)(arg); self.current_point = value; value }
}Kapama ifadelerini kullanarak .Net dünyasındaki LINQ(Language INtegrated Query) benzeri bir çatı bile geliştirilebilir. Aşağıdaki senaryoda Person struct dizisi taşıyan bir vector tipi bulunuyor. Bu vector üzerinde search isimli fonksiyon ile arama yapıyoruz. İşin sihri, arama fonksiyonunu kodu yazarken biz söylüyoruz ve bunu isimsiz fonksiyon kullanarak gerçekleştiriyoruz.
fn main() { let team = fill_players(); println!("***Seviyesi 300 üstünde olan oyuncular***"); let level_grater_than_300 = search(&team, |p: &Player| { return p.level >= 300; }); for p in level_grater_than_300 { println!("{}[{}] (Avg:{})", p.nickname, p.level, p.average_point); } println!("\n***Sayı ortalaması 16 altında olan oyuncular***"); let point_high = search(&team, |p: &Player| { return p.average_point < 16.0; }); for p in point_high { println!("{}[{}] (Avg:{})", p.nickname, p.level, p.average_point); } println!("\n***Leykırs takımında olan oyuncular***"); let point_high = search(&team, |p: &Player| { return p.team == "Leykırs";
}); for p in point_high { println!("{}[{}] (Avg:{})", p.nickname, p.level, p.average_point); }
}
// Oyuncu bilgilerini taşıyan struct
#[derive(Clone)] // search fonksiyonundaki for döngüsünde o anki player örneğinin bir klonunun oluşturulabilmesi için kullandığımız nitelik
struct Player { nickname: String, average_point: f32, level: i32, team: String,
}
/*
generic search fonksiyonumuz. İlk parametrede Person tipinden bir vector alıyor ve ikinci parametre de F tipinden bir closure. Fn trait'i ile ifade edilen closure'un Person referansı aldığı ve geriye true veya false döndürmesi gerektiğini belirtiyoruz (where kısmı)
Fonksiyon kendi içinde yeni bir vector oluşturuyor ve bunu geriye döndürüyor. Bu yeni vector içindeki Person nesnelerinin eklenme kriteri ise f fonksiyonu ile icra edilen koşul. Örneğin level'ı 300'den büyük olan oyuncuların çekilmesi gibi.
*/
fn search<F>(person_list: &Vec<Player>, f: F) -> Vec<Player>
where F: Fn(&Player) -> bool,
{ let mut result: Vec<Player> = Vec::new(); for p in person_list { if f(&p) { let plyr = p.clone(); result.push(plyr); } } result
}
fn fill_players() -> Vec<Player> { let mut team: Vec<Player> = Vec::new(); let mj = Player { nickname: String::from("M.J."), average_point: 32.50, level: 310, team: String::from("Şikago"),
}; let scoti = Player { nickname: String::from("Scoti pipin"), average_point: 15.5, level: 250, team: String::from("Şikago"),
}; let bird = Player { nickname: String::from("Leri börd"), average_point: 21.5, level: 320, team: String::from("Boston"), }; let longle = Player { nickname: String::from("Luk longley"), average_point: 10.5, level: 100, team: String::from("Şikago"),
}; let conson = Player { nickname: String::from("Mecik Conson"), average_point: 28.95, level: 350, team: String::from("Leykırs"),
}; let doncic = Player { nickname: String::from("Luka doncic"), average_point: 22.34, level: 310, team: String::from("Dallas"), }; let detler = Player { nickname: String::from("detler şiremğ"),
average_point: 15.99, level: 280, team: String::from("Dallas"), }; let karim = Player { nickname: String::from("karim abdul cabbar"), average_point: 21.99, level: 350, team: String::from("Leykırs"),
}; team.push(mj); team.push(scoti); team.push(bird); team.push(longle); team.push(conson); team.push(doncic); team.push(detler); team.push(karim); team
}ve bu örneğe ait çalışma zamanı çıktısı da aşağıdaki gibi olacaktır.
![]()
Iterators
Bir başka fonksiyonel dil kabiliyeti iterator kullanımıdır. Esasında Itereator kalıbı bir nesne dizisinde ileri yönlü hareket ederken her bir dizi öğesi için belli bir fonksiyonelliği çalıştırmak gibi işlemlerde kullanılır. Rust dilinde kendi veri yapılarımızı tasarlayabildiğimizi düşünecek olursak bu oldukça önemli bir kabiliyettir. iterator fonksiyonları ile sıralı veri yapıları üzerinde dönüştürme, arama, tekil elemena indirgeme vb işlevsellikler de kullanılır. Bu fonksiyonlar birden fazla adımı tek bir iterasyon içerisinde ele almayı kolaylaştırır. Iterator'lar standart kütüphanedeki Iterator isimli Trait'i uygularlar ve iter() arkasından gelen map, filter, for_each, find vb pek çok fonksiyon(ki bunlara iterator adaptor deniliyor) parametre olarak closure'lara başvurur. Uygulamamızı cargo new iteration-practices --lib ile oluşturabiliriz.
#[cfg(test)]
mod tests { use super::*; #[test] fn should_find_qualifiers_works_with_old_fashion() { /* Önce bilinen yollarlar bir kod parçası yazalım.
Amaç oyuncu listesinde ortalama puanına göre kimleri elemelere kaldığını bulup bir vector'de toplamak. test veri kümesini yükledikten sonra vector listesini döngü ile dolaşıyoruz.
Her bir oyuncunun average_point değerine bakıp 70 barajının üstünde ise ("Yes",oyuncu id) değilse ("No",oyuncu id) şeklinde
tuple değişkenleri oluşturup qualifiers vectöründe topluyoruz. Kabul kriterleri de bu ikili içeriklerine göre oluşturuluyor.
*/ let players = load_players_data(); let mut qualifiers: Vec<(String, u16)> = vec![]; //Soru: Neden mutable tanımlanmıştır?
for p in players { if p.average_point > 70 { qualifiers.push(("Yes".to_string(), p.id)); } else { qualifiers.push(("No".to_string(), p.id)); } } let mut iter = qualifiers.iter(); assert_eq!(iter.next(), Some(&("No".to_string(), 1001))); //Soru: Neden Some kullanılmıştır?
assert_eq!(iter.next(), Some(&("No".to_string(), 1002))); //Soru: Neden & ile referans noktası alınmıştır?
assert_eq!(iter.next(), Some(&("No".to_string(), 1003))); assert_eq!(iter.next(), Some(&("Yes".to_string(), 1004))); assert_eq!(iter.next(), Some(&("No".to_string(), 1005))); assert_eq!(iter.next(), Some(&("Yes".to_string(), 1006))); } #[test] fn should_get_qualitifed_players_as_binary_array() { let players = load_players_data(); // map parametresi olarak dış fonksiyon yerine kod bloduğu da (closure) kullanılabilir.
let qualified_iterator = players .iter() .map(|p| if p.average_point > 70 { 1 } else { 0 }); // p olarak ifade edilen Player değişkenidir. Nitekim map, players vektörüne ait iterator üzerinde uygulanmaktadır
let qualified: Vec<u16> = qualified_iterator.collect::<Vec<u16>>(); assert_eq!(qualified, vec![0, 0, 0, 1, 0, 1, 0, 0, 1, 1]); } #[test] fn should_get_players_qualification_state_in_yes_or_no() { let players = load_players_data(); /* map, bir closure'u parametre olarak alır. Örnekte closure is_qualified isimli fonksiyondur. Uygulandığı players koleksiyonundaki her Player değişkeni için çalışacak is_qualified fonksiyonunu kullanan yeni bir iterator değişkeni üretir. zip fonksiyonu iki iterator üzerinde dolaşan tek bir iterator üretilmesini sağlar.
parametre olarak aldığı qualify_counter iterasyonunu kullanadırarak players koleksiyonu üzerinde is_qualified uygulanmasını sağlar.
Sonuçlar ilk iterasyondaki Player değişkenleri ile parametre olarak gelen iterasyondan elde edilen sonuçların tuple olarak birleştiği veri dizisini dolaşacak yeni bir iterator nesnesidir. Elde edilen iterator, collect fonksiyonu çağırılarak bir koleksiyona indirgenir(Örnekte bu bir vector'dür) */ //Soru: Elemeye kalanları başka bir built-in fonksiyon ile daha kolay elde edebilir miyiz? let qualify_iterator = players.iter().map(is_qualified); let qualifiers: Vec<(&Player, String)> = players.iter().zip(qualify_iterator).collect(); // Temsili olarak finale kalan ve kalmayan birer örnek Player değişkeni kabülü assert_eq!( qualifiers[0], ( &Player::new( 1001, "niko rosberg".to_string(), 100, 56, "West".to_string() ), "No".to_string() ) ); assert_eq!( qualifiers[3], ( &Player::new( 1004, "engila beatriys".to_string(), 500, 71, "West".to_string() ), "Yes".to_string() ) ); } #[test] fn should_get_total_score_with_map_and_fold() { let players = load_players_data(); /* fold, map-reduce'taki reduce fonksiyonuna benzetilebilir. iterasyon üzerinden tek bir değerin hesaplanmasında kullanılır.
Örnekte map ile oyuncuların ortalama skorlarını dolaşacak bir iterasyon yakalanır.
fold, ilk parametre olarak bir başlangıç değeri alır.
İkinci parametre bir fonksiyon çağrısıdır. point o anki oyuncunun average_point değerini tutar. Accumulator bir inceki hesaplamanın sonucudur. Her ikisi closure'a girmektedir. Yani map,fold ile oyuncularının ortalama skorları toplamı bulunmuştur. Klasik yol dışında fonksiyonel bir yaklaşımla bu hesap edilmiştir.
*/ let total = players .iter() .map(|p| p.average_point) .fold(0, |point, accumulator| point + accumulator); assert_eq!(total, 127); } //Soru: Aşağıdaki testin FAIL etmesini sağlayın
#[test] fn should_get_only_west_sides_players() { let players = load_players_data(); /* filter fonksiyonu da bir closure kabul eder ve geriye bir iterasyon nesnesi döndürür. parametre olarak kullanılan closure'un true veya false döndürmesi gerekir */ let filtered = players.iter().filter(|&p| p.region == "West"); for f in filtered { assert_eq!(f.region, "West"); } } #[test] fn should_get_first_three_players_with_id_and_region() { let players = load_players_data(); /* Önce map ile id(region) formatında bir string koleksiyonunu elde ettik. Bu listeyi dönecek iterasyon üzerinden take ile ilk 3 elemanı dolaşacak başka bir iterator örnekledik. */ let mut mapped = players .iter() .map(|p| format!("{}({})", p.id, p.region)) .take(3); assert_eq!(mapped.next(), Some("1001(West)".to_string())); assert_eq!(mapped.next(), Some("1002(West)".to_string())); assert_eq!(mapped.next(), Some("1003(East)".to_string())); assert_eq!(mapped.next(), None); } #[test] fn should_engila_beatriys_in_players_but_noname_is_not() { let players = load_players_data(); /* find, true veya false dönen bir closure ile çalışır. Kriter sağlanırsa Some(Player), sağlanmazsa None döner */ //Soru: map fonksiyonundaki _ operatörü neyi temsil eder ve niçin kullanılmıştır? Kullanılmak zorunda mıdır?
assert_eq!( players .iter() .find(|p| p.name == "engila beatriys") .map(|_| "Yes"), Some("Yes") ); assert_eq!( players.iter().find(|p| p.name == "No name").map(|_| "Yes"), None ); } #[test] fn aggregation_tests() { let players = load_players_data(); /* max, min ve sum gibi fonksiyonlar aggregation işlemlerinde kullanılırlar.
Yani tek bir sonuç üretilmesinde ele alınırlar.
Player bir struct olduğundan max,min,sum ile hangi alanı ele alacağımızı söylememiz gerekir. map burada işimizi kolaylaştırmaktadır.
*/ let average_point_iterator = players.iter().map(|p| p.average_point); let biggest = average_point_iterator.max(); assert_eq!(biggest, Some(90)); let smallest = players.iter().map(|p| p.average_point).min(); assert_eq!(smallest, Some(-110)); let sum_of_avg_points: i16 = players.iter().map(|p| p.average_point).sum(); assert_eq!(sum_of_avg_points, 127); } #[test] fn chain_test() { /* chain fonksiyonu ile iki iterasyon zincirleme birbirine bağlanabilir.
Örnekte blue_team_points ile red_team_points vektorlerine ait iki iterasyon uç uca bağlanmıştır.
Kendi iteratörleri 70ten büyük puanlar almakta, chain ile birleştirilen zincirle elde edilen iteratör ise 90'dan büyük olanları kullanmaktadır.
Yeni iteratör üzerinden çağırılan count ile 90 her iki gruptan 90 üstü alan toplam kaç kişi olduğu bulunur. */ //Soru: İkiden fazla iteratör chain ile birbirlerine bağlanabilir mi? let blue_team_points = vec![32, 55, 78, 91, 88, 90, 0, 15]; let red_team_points = vec![44, 50, 98, 60, 99, 40, 72, 77, 79]; let iter_a = blue_team_points.iter().filter(|&n| n > &70); let iter_b = red_team_points.iter().filter(|&n| n > &70); let total = iter_a.chain(iter_b).filter(|&n| n >= &90).count(); assert_eq!(total, 4); } fn is_qualified(p: &Player) -> String { if p.average_point > 70 { "Yes".to_string() } else { "No".to_string() } }
}
///
/// Test amaçlı oyuncu verisi yükleyen fonksiyondur
///
fn load_players_data() -> Vec<Player> { vec![ Player::new( 1001, "niko rosberg".to_string(), 100, 56, "West".to_string(), ), Player::new( 1002, "raiyukunen du".to_string(), 600, -89, "West".to_string(), ), Player::new( 1003, "di tomassi no".to_string(), 200, -25, "East".to_string(), ), Player::new( 1004, "engila beatriys".to_string(), 500, 71, "West".to_string(), ), Player::new( 1005, "barbıra".to_string(),
200, -78, "Dangen Zone".to_string(), ), Player::new( 1006, "morata".to_string(), 300, 90, "Blue Lagon".to_string(), ), Player::new( 1007, "fat-ma".to_string(), 300, 50, "Blue Lagon".to_string(), ), Player::new( 1008, "bloumquvits".to_string(), 400, -110, "Wild Wild West".to_string(), ), Player::new( 1009, "indi yama guşi".to_string(),
100, 77, "Mordor".to_string(), ), Player::new( 1010, "raçel ways".to_string(), 500, 85, "Gondor".to_string(), ), ]
}
///
/// Bir oyucunun numarası, seviyesi ve ortalama skorunun tutulduğu veri yapısıdır
///
#[derive(Debug, PartialEq)]
pub struct Player { id: u16, name: String, level: i16, average_point: i16, region: String,
}
///
/// Player veri yapısı için yardımcı fonksiyonlar içerir
impl Player { /// /// Parametrelerden yararlanarak yeni bir Player değişkeni örnekler /// fn new(no: u16, nm: String, lvl: i16, avg: i16, rg: String) -> Self { Player { id: no, name: nm, level: lvl, average_point: avg, region: rg, } }
}Bir iterator örneği daha yazalım. Pratik olsun.
/* bir iterator kullanım örneği daha. Bu kez kendi veri yapımızın alanları üzerinde filtreleme işlemi gerçekleştiriyoruz.
*/
/*
Birkaç klasik oyun bilgisini tutacak bir struct.
*/
#[derive(PartialEq, Debug)]
struct Game { name: String, year: u16, publisher: String, value: f32, platform: Platform,
}
/*
Oyunun hangi console'da oynandığı bilgisini de bir enum ile tutalım.
Bu arada game_by_platform fonksiyonundaki == operatörünü kullanabilmek için PartialEq niteliğini kullanıyoruz
*/
#[derive(PartialEq, Debug)]
enum Platform { Commodore64, Atari2600, Atari5200,
}
/*
Belli bir yıldan önceki oyunları döndüren bir fonksiyon. Game türünden vector parametre olarak gelir, _year değerine göre filtreleme yapılır
ve bu kritere uyan oyunlar geriye dönülür. Tüm arama fonksiyonlarında into_iter iterator'u kullanılıyor. Bu vector'ün sahipliğini üstlenen bir iterator oluşturmak için kullanılıyor.
Sahipliği almadığımız takdirde collect fonksiyonu derleme hatası verecektir.
*/
fn before_year(games: Vec<Game>, _year: u16) -> Vec<Game> { games.into_iter().filter(|g| g.year <= _year).collect()
}
/*
Belli bir platform için yazılmış oyunların bulunması
*/
fn games_by_platform(games: Vec<Game>, _platform: Platform) -> Vec<Game> { games .into_iter() .filter(|g| g.platform == _platform) .collect()
}
/*
İçinde parametre olarak gelen kelimeyi içeren oyunlar
*/
fn games_include_this(games: Vec<Game>, _word: String) -> Vec<Game> { games .into_iter() .filter(|g| g.name.contains(&_word)) .collect()
}
/*
Örnek birkaç oyun bilgisi yüklediğimiz fonksiyon
*/
fn load_samples() -> Vec<Game> { vec![ Game { name: String::from("Crazy Cars II"), year: 1988, publisher: String::from("Titus"), value: 1.5, platform: Platform::Commodore64, }, Game { name: String::from("1942"), year: 1986, publisher: String::from("Elit"), value: 2.85, platform: Platform::Commodore64, }, Game { name: String::from("Pitstop II"), year: 1984, publisher: String::from("Epyx"), value: 0.55, platform: Platform::Commodore64, }, Game { name: String::from("The Last Ninja"), year: 1987, publisher: String::from("System 3"), value: 1.49, platform: Platform::Commodore64, }, Game { name: String::from("Spy Hunter"), year: 1983, publisher: String::from("US Gold"), value: 2.40, platform: Platform::Commodore64, }, Game { name: String::from("3-D Tic Tac Toe"), year: 1980, publisher: String::from("Atari"), value: 6.75, platform: Platform::Atari2600, }, Game { name: String::from("Asteroids"), year: 1981, publisher: String::from("Atari"), value: 6.70, platform: Platform::Atari2600, }, Game { name: String::from("Gremlins"), year: 1986, publisher: String::from("Atari"), value: 2.75, platform: Platform::Atari5200, }, Game { name: String::from("Mario Bros."), year: 1988, publisher: String::from("Nintendo"), value: 9.85, platform: Platform::Atari5200, }, ]
}
/*
Test modülümüzü de ekleyelim. Eklenen fonksiyonları test ederek ilerleriz
*/
#[cfg(test)]
mod tests { use super::*; /* Mesela veri setimize göre Atari5200 platformundan iki oyunun olduğu bir vector dizisi dönmeli */ #[test] fn should_games_include_two_atari5200_games() { let retro_games = load_samples(); let finding = games_by_platform(retro_games, Platform::Atari5200); assert_eq!( finding, vec![ Game { name: String::from("Gremlins"), year: 1986, publisher: String::from("Atari"), value: 2.75, platform: Platform::Atari5200, }, Game { name: String::from("Mario Bros."), year: 1988, publisher: String::from("Nintendo"), value: 9.85, platform: Platform::Atari5200, }, ] ) } /* 1986 dahil öncesinde geliştirilen de 6 oyun olmalı
*/ #[test] fn should_return_six_for_games_before_1986() { let retro_games = load_samples(); let finding = before_year(retro_games, 1986); assert_eq!(finding.len(), 6); } /* Adında II geçen oyunların testi. */ #[test] fn should_return_games_for_name_contains_two() { let retro_games = load_samples(); let finding = games_include_this(retro_games, String::from("II")); assert_eq!( finding, vec![ Game { name: String::from("Crazy Cars II"), year: 1988, publisher: String::from("Titus"), value: 1.5, platform: Platform::Commodore64, }, Game { name: String::from("Pitstop II"), year: 1984, publisher: String::from("Epyx"), value: 0.55, platform: Platform::Commodore64, }, ] ); }
}
fn main() {}Test sonuçlarını aşağıda görebilirsiniz.
![]()
Tahmin edeceğiniz üzere kendi geliştirdiğimiz türler veya hash map gibi diğer koleksiyonlar için kendi iterator fonksiyonlarımızı da yazabiliriz. Tek yapmamız gereken Iterator trait'ini uygulamaktır. Ancak bunun için uygun senaryolara da ihtiyacımız vardır. Şunu da bir açıklığa kavuşturalım; Iterator demek veri için bir sonraki veriyi döndüren ve nerde durması gerektiğini bilen bir next fonksiyonu demektir.
Ben dili öğrenmeye çalıştığım sırada bu konuyla ilgili olarak iki örnek üzerinde çalışmıştım. Sizde bunları sırasıyla kodlayarak ilerleyebilirsiniz. Önce bir öğrencinin notları üzerinde for döngüsü ile dolaşabilmemizi sağlayacak uyarlamaya bakalım(Birim Testsiz sürüm)
// Öğrencinin ders ortalamalarını tutan bir veri yapısı düşünelim
struct Point { math: f32, lang: f32, phys: f32, chem: f32, vart: f32,
}
/*
Şimdi de bunu kullanan bir öğrenci veri yapısı tasarlayalım.
Sanırım amaç anlaşıldı. Bir öğrenicinin notlarını for döngüsü ile dönebilmek istiyorum. Bu iterasyon sırasında verinin haricinde verinin durumunu ve hangi konumda olduğumu da bilmem lazım.
O nedenle position ve data isimli iki alanımız var. İlk versiyonda points verisini olduğu gibi tutmuştuk. Lakin verinin referansını tutmamız yeterli. Tabii Point referansını tutacağız ama Rust, Student veri yapısının taşıyacağı bu referans ile olan ilişkinin ömrünü bilemeyecek. O nedenle <'a> ile lifetime ilişkisini eşitliyoruz.
*/
struct Student<'a> { fullname: String, school: String, position: i32, points: &'a Point,
}
/*
iterator trait'inin uygulanması.
Eğer <'_> şeklinde isimsiz lifetime bildirimi yapmazsak 'implicit elided lifetime not allowed here' şeklinde hata alırız.
Bu nedenle <'_> şeklinde bir bildirim yapıp Rust derleyicisinden bu hatayı göz ardı etmesini rica ediyoruz.
*/
impl Iterator for Student<'_> { type Item = f32; // Point struct'tındaki türden olduğunda dikkat edelim /* next sıradaki Item'ı yani puanı yani f32 türünden öğeyi döndürür. Kiminkini peki? Self ile ifade ettiğimize göre o anki Student nesnesininkini. */ fn next(&mut self) -> Option<Self::Item> { match self.position { 0 => { self.position += 1; Some(self.points.math) } 1 => { self.position += 1; Some(self.points.lang) } 2 => { self.position += 1; Some(self.points.phys) } 3 => { self.position += 1; Some(self.points.chem) } 4 => { self.position += 1; Some(self.points.vart) } _ => None, } }
}
fn main() { // ant_man'ın ders not ortalamalarını girdik let some_points = Point { math: 78.0, chem: 55.0, phys: 80.0, lang: 90.0, vart: 67.5, }; let ant_man = Student { fullname: String::from("Ant-Man"), school: String::from("Mystery Forrest High School"), points: &some_points, // referans adresi verdiğimize dikkat edelim position: 0, // Aslında bu atama ile iterator'un 0ncı konuma inmesini sağlıyoruz.
}; println!("{} ({})", ant_man.fullname, ant_man.school); // bu for döngüsü ant_man'ın tüm ders notlarını dolaşabiliyor.
// Iterator implementasyonu sayesinde for p in ant_man { println!("{}", p); }
}![]()
Bir programlama dili çeşitli türde veri yapıları sağlar. Geliştiriciler bunları kombine ederek bir eco system inşa edebilirler.
İyi programlama dilleri bu ekosistemin inşasını kolaylaştırır. Iterator deseni GoF'un belirttiği tasarım prensiplerinden birisidir ve Rust dilinde de trait'leri üzerinden kurgulanabilir. Böylece kendi veri yapılarımız içerisinde ileri yönlü hareket edebiliriz.
Örnek kod parçasında TeamSquad veri yapısı için bir iterasyon tasarlanmaya çalışılmaktadır. Buna göre for döngüsü veya next fonksiyonları ile takım üyeleri üstünde ileri yönlü hareket edilmesi sağlanır. cargo new custom-iterators --lib ile uygulamamızı oluşturup kodlayalım.
#[cfg(test)]
mod tests { use super::*; #[test] fn should_next_over_team_squad_works() { let mut blue_team = TeamSquad::new(); blue_team.game_color = Some(Color::Blue); blue_team.push(Player::new("börd".to_string(), 79)); blue_team.push(Player::new("bıraynt".to_string(), 88)); blue_team.push(Player::new("barkli".to_string(), 76)); blue_team.push(Player::new("cordın".to_string(), 93)); let mut iter = blue_team.into_iter(); // next fonksiyonu ile TeamSquad nesnesinden hareket etmemizi sağlar
assert_eq!(iter.next(), Some(Player::new("cordın".to_string(), 93))); assert_eq!(iter.next(), Some(Player::new("barkli".to_string(), 76))); assert_eq!(iter.next(), Some(Player::new("bıraynt".to_string(), 88))); assert_eq!(iter.next(), Some(Player::new("börd".to_string(), 79))); assert_eq!(iter.next(), None); } #[test] fn should_for_loop_over_team_squad_works() { let mut red_team = TeamSquad::new(); red_team.game_color = Some(Color::Red); red_team.push(Player::new("poo".to_string(), 65)); red_team.push(Player::new("obi van".to_string(), 85)); red_team.push(Player::new("leya".to_string(), 76)); red_team.push(Player::new("rey".to_string(), 92)); red_team.push(Player::new("kaylo ren".to_string(), 84)); red_team.push(Player::new("han solo".to_string(), 71)); let mut total_team_power: i32 = 0; for plyr in red_team { total_team_power += plyr.level; } assert_eq!(total_team_power, 473); }
}
/*
Amaç TeamSquad nesnesi üzerinde ileri yönlü hareket ederken içerdiği oyuncuları dolaşabilmek
Iterator'ları ayrı birer struct olarak tanımlamak değerleri sahiplenmek yerine referanslarını kullandırabilmek açısından önemlidir. Soru: Generic veri yapıları için iterator kalıbı uygulanabilir mi?
*/
pub struct TeamSquadIterator { squad: TeamSquad,
}
impl TeamSquadIterator { fn new(team: TeamSquad) -> TeamSquadIterator { TeamSquadIterator { squad: team } }
}
/*
Türlere iterator yeteneğini kazandırmak için Iterator ve IntoIterator trait'lerini uygulamak gerekir.
*/
impl Iterator for TeamSquadIterator { type Item = Player; fn next(&mut self) -> Option<Player> { self.squad.pop() }
}
impl IntoIterator for TeamSquad { type Item = Player; type IntoIter = TeamSquadIterator; fn into_iter(self) -> Self::IntoIter { TeamSquadIterator::new(self) }
}
///
/// Takım veri yapısı.
/// İçinde takım rengi ve oyuncular dizisi yer alır
pub struct TeamSquad { game_color: Option<Color>, players: Vec<Player>,
}
///
/// TeamSquad veri yapısın için uygulanan fonksiyonları içerir
///
impl TeamSquad { /// /// Yeni bir TeamSquad nesnesi örnekler /// pub fn new() -> Self { TeamSquad { players: Vec::new(), game_color: None, // Option<Color> türünden tanımladığımız için bu mümkün. Henüz oluşturulmamış bir takım için ideal değer.
} } /// /// Takıma eklenen son oyuncuyu geri verir ve listeden çıkartır
/// pub fn pop(&mut self) -> Option<Player> { self.players.pop() } /// /// Takıma yeni bir oyuncu ekler /// pub fn push(&mut self, p: Player) { self.players.push(p) }
}
///
/// Takım rengi
///
pub enum Color { Red, Blue, Green,
}
///
/// Oyuncu bilgilerini tutan veri yapısıdır
///
#[derive(Debug, PartialEq)] // assert_eq! da karşılaştırma == üstünden yapıldığı için eklendi
pub struct Player { name: String, level: i32,
}
///
/// Player veri yapısına ait fonksiyonlar
///
impl Player { /// /// name ve level parametrelerini kullanarak Player nesnesi oluşturur
/// fn new(n: String, l: i32) -> Self { Player { name: n, level: l } } /// /// Player hakkında bilgi verir /// fn to_string(&self) -> String { format!("{},{}", self.name, self.level) }
}(HOF)Higher Order Function
Rust dilinin bir diğer fonksiyonel özelliği de Higher Order Functions kabiliyetidir. Yani fonksiyonları birbirlerine bağlayıp yeni fonksiyonellikleri çalıştırabiliriz. Fonksiyonlar çıktı olarak fonksiyon döndürebildiklerinden bu oldukça doğaldır. Aslında HOF yeteneği denince benim aklıma hep nokta operatörü sonrası birbirlerine bağlanan LINQ fonksiyon zincirleri gelir.
fn main() { let mut total = 0; // imperative yaklaşım
for n in 500..1000 { let s = n * n; if calc(s) { total += s; } } println!("Imperative stilde toplam {}", total); // fonksiyonel yaklaşım
let total2: i32 = (500..1000) .map(|n| n * n) // Aralıktaki sayıların karelerinden oluşan kümeyi bir alalım
.filter(|&s| calc(s)) // bunların 3 veya 5 ile bölünebilme hallerine bakalım
.fold(0, |t, s| t + s); // o kurala uyanları da toplayalım
println!("Fonksiyonel stilde toplam {}", total2);
}
fn calc(n: i32) -> bool { n % 3 == 0 && n % 5 == 0
}Patterns Matching
Fonksiyonel dillerin sık rastlanan özelliklerinden birisi de pattern matching'dir. Karmaşık karar yapılarında kodu basitleştirir ve dallanmaları kolayca yönetmemizi sağlarlar. Enum'larda uygulanabileceği gibi struct türünde de kullanılabilir. Pattern(şablon), basit veya karmaşık bir tipi yapısını eşleştirme yoluyla kontrol etmeye yarayan bir söz dizimi olarak düşünülebilir. Bu deseni Rust dilinde bir çok yerde görebiliriz. Gelin ilk önce temellerini anlayalım ve sonrasında daha özgün bir kullanım örneği yazalım.
fn main() { /* #1 Önce pattern(şablon) konusuna bir bakalım.
İlginç geldi ki aşağıdaki ifadelerde soldaki değişkenler birer pattern'dir. Sağ taraftan ne gelirse gelsin eşleştirdiğimiz birer aktördür. let PATTERN = EXPRESSION; */ let pi = 3.1415; // pi bir pattern let (x, y, z) = (1, 3, 5); // Burada eşitliğin sağındaki tuple verisini bir pattern ile eşleştirdik(match)
let (a, b, _, d) = (1, 1, 0, 1); // _ ile pattern içerisindeki bir eşleşmeyi atladığımızı ifade ettik /* Aşağıdaki while let döngüsünde colors isimli vector'ün elemanlarını dolaşırken
pattern matching kullanılmaktadır.
pop metodu eleman yoksa None döner, eleman varsa da elemanı döner :) while let ile bu eşleşme Some(color) ile kontrol edilir. Böylece vector'den eleman çektikçe None veya herhangi biri olma eşlemesine(match) bakılır.
Bu arada pop fonksiyonu hep son eklenen elemanı vereceğinden döngü renkleri ters sırada ekrana basar. */ let mut colors = Vec::new(); colors.push("Red"); colors.push("Green"); colors.push("Blue"); while let Some(color) = colors.pop() { println!("{}", color); } /* Şimdi de aşağıdaki for kullanımına bakalım.
Burada da (x,v) aslında bir pattern olarak karşımıza çıkar.
enumerate fonksiyonu geriye iterasyondaki elemanın sıra numarası(index)
ve değerini(value) döndürür. for (x,v) bu eşleşmeye bakar. */ let market_list = vec![ "Bir kilo prinç", "2 ekmek", "Yarım kilo un", "Bir paket dilimlenmiş kaşar peyniri", "Aç bitir salam", ]; // Evet bu kısımlarda acıkmışım
for (x, v) in market_list.iter().enumerate() { println!("{} -> {}", x, v); } /* if let ifadelerinde de pattern matchin kullanılabilir.
Aşağıdaki point değişkenin değeri String bir içerikten parse edilerek alınıyor.
parse geriye Result<Value,Error> döner. Bu Ok() ile eşleştirilebilir.
parse işlemi başarılıysa Result'ın Value değeri Ok(p) gibi döner. parse başarılı değilse Ok(p) eşleşmesi ihlal edilir ve else bloğuna girilir. */ let point: Result<f32, _> = "3.1415".parse(); // Bide, float olarak Parse edilemeyecek bir şey yazıp deneyin if let Ok(p) = point { if p > 2.777 { println!("Harika bir iş");
} else { println!("Belki biraz daha çalışmak lazım")
} } else { println!("Problem var"); } /* Fonksiyon parametreleri de birer şablon olabilir. Aşağıdaki örneğe bakalım.
move_left fonksiyonuna gönderilen location isimli tuple, parametre tarafındaki &(x,y) şablonu ile eşleştirilir.
*/ let location = (10, 20); //location bir pattern let (a, b) = move_left(&location, 5); // (a,b) de bir pattern println!("({}:{}) -> ({}:{})", location.0, location.1, a, b); // Aşağıdaki kod parçasını açınca bir uyarı mesajı alınır. Sizce neden? // if let value = 10 { // println!("{}", value); // } /* Şablonları struct veri türünün değişkenlerini başka değişkenlere kolayca almak için de kullanabiliriz. Buna Destructuring demişler. Belki de parçalarını çekip çıkardığımız içindir. Her neyse. Aşağıdaki kullanıma bakalım.
Bu kod parçasında bird içindeki id ve nick_name bilgilerini let pattern ile sol taraftaki number, player_name isimli değişkenlere aldık(aynı isimli değişkenler de kullanabiliriz bu durumda : ile isim belirtmemize gerek yok) ve bir sonraki satırda kullanabildik. */ let bird = Player { id: 33, nick_name: String::from("Leri Böörd"), }; let Player { id: number, nick_name: player_name, } = bird; println!( "{} numaralı formasıyla '{}' geliyorrrr...", number, player_name ); /* Benzer senaryoyu(Destructuring) enum tipi için de uygulayabiliriz. Bunu match ifadesi ile ele almak oldukça mantıklı.
eintesin bir enum değişkeni. İçinde bir tuple ve struct türlerine yer verdik. match ifadesinde Person ve AddValues kısımlarında şablon eşleştirmeleri ile Destructuring işlemi uygulanmaktadır.
*/ let einstein = Genius::Person { level: 78, name: String::from("Gauss"), }; match einstein { Genius::Person { level: l, name } => { println!("{} {}", l, name); } Genius::AddValues(v1, v2) => println!("{} {}", v1, v2), Genius::OnGame => println!("Oyunda"), // Burada sabit bir değer söz konusu olduğunda Destructuring olmaz } /* şablonlar ile Destructuring'in bir arada kullanımı aşağıdaki gibi karmaşık kod ifadelerine de sebebiyet verebilir. Eşitliğin sol tarafındaki şablonda origin_x, origin_y isimli değişkenlere sahip tuple ve Player struct'ını içeren bir tuple tanımı var. Sağ taraftan da buna göre bir eşleşme yapılıyor.
Kısaca tuple ve struct içeren bir tuple'ın içeriği Destructuring ile değişkenlere alınıyor.
Hatta alınırken id değişkenini göz ardı ediyoruz(Eşitliğin solundaki _ kullanımına dikkat) */ let ((origin_x, origin_y), Player { id: _, nick_name }) = ( (155, 179), Player { id: 11, nick_name: String::from("Kayri Örving"), }, ); println!( "'{}' şimdi ({}:{}) konumuna geldi.", nick_name, origin_x, origin_y ); /* #2 Biraz da match kullanımlarına bakıp hatırlayalım.
match kullanımının belki de en basit hali aşağıdaki gibidir. currency şablonunun match ifadesindeki durumlardan birisine uygunluğu kontrol edilir. _ ile hiçbirisine uymayan durum söz konusudur */ let currency = "TL"; match currency { "TL" => println!("TL işlemi uygulanacak"), "USA" => println!("Dolar işlemi uygulanacak"), _ => println!("Hiç birisi uymadı"),
} /* Şimdi aşağıdaki match kullanımına odaklanalım.
value_a'nın sahip olduğu değeri kontrol ediyoruz. Some(50) eşleşmesi çalışmayacak, çünkü value_a Some(100) değerine sahip. Lakin ikinci Some kontrolü eşleşecek. Buradaki mutable value_b, value_a nın başlangıçtaki değerine sahip olur. Yani Some(100)'e. Bu nedenle eşleşme kabul edilir ve blok içerisinde value_b değeri 1 artırılıp ekrana basılır ki bu değer 101 dir!!! match sonrasında ekrana A ve B değerleri 100 ve 10 olarak basılacaktır.
Burada kafalar karışabilir. Some(mut value_b) eşleşmesi çalışmıştı ve orada value_b değerini 1 artırmıştık. Dolayısıyla value_b'nin 101 kalması gerekir diyebiliriz. Ancak Some(mut value_b) value_a nın match ifadesinde kullanılmaktadır. Yani kendi bloğu içinde yeni bir değişkendir. Sadece value_a'nın başlangıç değerini almaktadır.
Bunu etraflıca düşünüp hazmetmeye çalışın :) */ let value_a = Some(100); let value_b = 10; match value_a { Some(50) => println!("Got 50"), Some(mut value_b) => { value_b = value_b + 1; println!("{}", value_b); } _ => println!("Farklı bir koşul"),
} println!("A değeri {:?}, B değeri = {:?}", value_a, value_b); /* Aşağıdaki match ifadesinde, şablonların veyalanarak ve bir aralık
belirtilerek kullanılması örneklenmektedir. Veyalamak için | aralık belirtmek içinse ..=(Matching Range) operatörlerinden yararlanılır.
Matching Range sayı ve karakter veri tipi için kullanılabilir.
*/ let order_no = 10; match order_no { 1 | 2 | 3 => println!("İlk üçtesiniz. Sıranız * 3 puan verilir."), 4 | 5 | 6 => println!("Yine de 1 puan verilir"), 7..=10 => println!("7nci ve 10ncu arasındasınız. O zaman 0.5 puan verelim."), _ => println!("Kontenjan dışı kaldınız :("), } let first_letter = 'l'; match first_letter { 'a'..='m' => println!("{} izin verilen listede", first_letter), _ => println!("{} izin verilen listede değil", first_letter), }
}
fn move_left(&(x, y): &(i32, i32), v: i32) -> (i32, i32) { (x + v, y + v)
}
// Destrcuting örnekleri için
struct Player { id: i32, nick_name: String,
}
enum Genius { AddValues(i32, i32), // iki eleman tutan Tuple Person { level: i32, name: String }, // bir struct OnGame,
}İkinci örneğimizde ise aslında biraz daha derli toplu bir çalışmamız olacak. Konuyu birim testleri ile birlikte ele alacağız. Bunu da bir kütüphane olarak tasarlayıp birim test fonksiyonları ile güçlendirelim.
///
/// story point değerine göre bir t-shirt boyutu döndürür
///
fn get_tshirt_size(s_point: usize) -> String { /* Literal bir tür üstünde yapılan tipik pattern matching örneğidir
*/ let result = match s_point { 1 | 2 => "SMALL", //1 veya 2 olma hali 3..=8 => "MEDIUM", // 3 ile 8 arasındaki değerlerden biri gelirse 8..=13 => "BIG", // 8 ile 13 arasındaki değerlerden biri gelirse 20 | 80 => "EPIC", // 20 veya 80 olma hali 100 => "DRINK COFFEE", // sabit 100e eşit olursa _ => "N/A", // _ ile bunların dışında kalan durumlar ele alınır
}; //Soru: let ile değişkene almadan da fonksiyondan çıktı üretebilir miyiz? //Soru: _ ile kalan durumları ele almazsak ne olur? result.to_owned()
}
///
/// Parametre olarak Gün,Ay,Yıl,Saat,Dakika,Saniye cinsinden gelen bir tuple içinden saat bilgisini döndürür
///
fn get_hour(time: (usize, usize, usize, usize, usize, usize)) -> String { /* pattern matching tuple veri türü ile de kullanılabilir.
_ ile işaretlenen tuple alanları atlanırken h ile tuple içinden dışarıya doğru değişkenin değeri verilir. */ match time { (_, _, _, h, _, _) => format!("Saat {}", h), }
}
/*
Destructuring. Pattern Matching ile yapıların alanlarını dallanmalara çıktı olarak verebiliriz.
*/
enum TaskState { Approved, Rejected, Canceled, Created, Closed, Suspended,
}
struct Task { state: TaskState, title: String, story_point: usize,
}
///
/// Parametre olarak gelen Task ile ilgili özet bilgi döner
///
fn task_info(t: Task) -> String { /* t ile gelen Task yapısının olası durumları ele alınmaktadır.
Sembolik olarak Approved, Rejected ve Canceled durumlarına bakılmaktadır.
Her durum için bir Task örneği oluşturulmakta, Task'a gelen title ve story_pint gibi değişkenler t ve point değişkenleri ile dışarıya çıkartılabilmekte ve => sonrasındaki format! fonksiyonunda kullanılabilmektedir.
*/ match t { Task { state: TaskState::Approved, title: t, story_point: point, } => format!("{},{} -> Onaylandı", t, point), Task { state: TaskState::Rejected, title: t, story_point: _, // story_point'ı dışarı çıkartıp kullanmayacağımız için _ kullanıldı
} => format!("{} -> İade Edildi", t), Task { state: TaskState::Canceled, title: t, story_point: point, } => format!("{},{} -> İptal Edildi", t, point), _ => "Kapsam Dışıdır".to_owned(), // Yukarıdaki hallerinde dışında bir TaskState gelirse }
}
///
/// story_point bazında bir olasılık tahmini yapar
///
fn task_probability(t: Task) -> String { /* Burada guard matching kullanımı söz konusudur. (if point > 80 ile eşleşen bir dala koşul konulmuştur)
.. kullanımlarına dikkat */ match t { Task { story_point: point, .. } if point > 80 => "Şaka yapıyorsun sanırım".to_owned(), //Task eşleşmesinde sadece story_point'i ele alıp 80den büyük olma haline bakıyoruz,
Task { .. } => "Story Point elverişli".to_owned(),
}
}
///
/// Bir Task çiftini story_point bazında karşılaştırıp analiz eder
///
fn compare_task(pair: (Task, Task)) -> String { /* guard matchin örneği.
Fonksiyona gelen tuple içerisinde iki Task örneği var. (t1,t2) çiftlerini if koşullarına sokup story_point bazında karşılaştırma yapıyoruz.
*/ match pair { (t1, t2) if t1.story_point > t2.story_point => format!("{} > {}", t1.title, t2.title), (t1, t2) if t1.story_point < t2.story_point => format!("{} < {}", t1.title, t2.title), (t1, t2) if t1.story_point == t2.story_point => format!("{} = {}", t1.title, t2.title), _ => "İlişki kuramadım".to_owned(),
}
}
#[cfg(test)]
mod tests { use super::*; #[test] fn should_task_state_on_approved() { let redis_task = Task { state: TaskState::Approved, title: "Session bilgileri Redis'e alınacak".to_string(),
story_point: 13, }; assert_eq!( task_info(redis_task), "Session bilgileri Redis'e alınacak,13 -> Onaylandı"
); } #[test] fn should_task_state_out_of_scope() { let core_task = Task { state: TaskState::Created, title: "NDAL Kaldırılacak".to_string(),
story_point: 80, }; assert_eq!(task_info(core_task), "Kapsam Dışıdır");
} #[test] fn should_task_state_on_just_kidding_grater_then_80_points() { let convert_task = Task { state: TaskState::Created, title: "Backend tarafı mikroservise dönüştürülecek".to_string(), story_point: 100, }; assert_eq!(task_probability(convert_task), "Şaka yapıyorsun sanırım");
} #[test] fn should_task_grater_than_other() { let tasks = ( Task { title: "Task 1".to_string(), state: TaskState::Created, story_point: 5, }, Task { title: "Task 2".to_string(), state: TaskState::Created, story_point: 13, }, ); let comment = compare_task(tasks); assert_eq!(comment, "Task 1 < Task 2"); } #[test] fn should_medium_for_5_story_point() { let size = get_tshirt_size(5); assert_eq!(size, "MEDIUM"); } #[test] fn should_small_for_1_or_2_story_point() { let size = get_tshirt_size(1); assert_eq!(size, "SMALL"); let size = get_tshirt_size(2); assert_eq!(size, "SMALL"); } #[test] fn should_return_none_for_other_story_points() { let size = get_tshirt_size(500); assert_eq!(size, "N/A"); } #[test] fn should_get_hour_from_long_time() { let now = (29, 10, 2020, 17, 32, 65); assert_eq!(get_hour(now), "Saat 17"); }
}Smart Pointers
Pointer denince aklımıza bellekteki bir bölgenin adresini tutan işaretçi gelir. Rust dilinde pointer'ların en bilinen tipi ise referans türüdür. Ancak bunların yanında Smart Pointer adı verilen bir veri yapısı daha var. Smart Pointer yine verinin bellek adresini taşır ama ek metadata bilgisi de içerir. Hatta şu ana kadar birkaç smart pointer kullandığımızı söyleyebilirim(Örneğin String ve Vec) Söz gelimi Vector türü sadece verinin referans adresini taşımaz onunla birlikte başlangıç kapasitesi gibi ek bilgi de taşır. Pointer olarak belirtilen referans türleri veriyi ödünç alırlar(borrowing durumu) aksine Smart Pointer'lar adreslenen veriyi sahiplenirler(ownership durumu)Şimdi örnek kod parçası ile konuyu anlamaya çalışalım.
fn main() { /* En bilinen Smart Pointer türlerinden birisi Box<T> Veriyi Heap üzerinde tutmamızı sağlar. Tamam referans türü ile de bunu yapıyoruz ama metadata olayını unutmayalım.
Ayrıca,
Büyük bir verinin sahiplini kopyalamadan taşımak istediğimizde (Büyük veriyi Heap'te kutulayacağız)
Derleme zamanında boyutunu bilemediğimiz bir veri kullandığımızda
gibi durumlarda tercih edilir. */ let a_number = Box::new(3.1415); // normalda stack'te duracak bir f32 verisini Heap'te kutuladık
println!("{}", a_number); /* Rust, derleme zamanında tiplerin ne kadar yer tutacağını bilmek ister. Fonksiyonel dillerde rastlanan cons list gibi türler ise recursive özellik gösterirler ve tipin ne kadar yer tutacağı kestirilemez. cons Lisp kökenlidir ve iki argüman alan bir fonksiyondur. const list, cons fonksiyonunu recursive olarak çağıran bir elemanlar dizisidir. Son elemanda Nil görene kadar bu liste devam edebilir. */ let infinity_war = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil)))))); // Kafa karıştırıcı yahu /* Şimdi aşağıdaki kullanımlara bakalım.
Normalde bir değişkenin referansını almak için & operatörünü kullanırız. Referans üstünden değer okurken de *(Dereference) operatörü kullanılır.
*/ let mut point = 23; let pointer = &point; assert_eq!(23, *pointer); // * operatörünü kullanmadan denersek 'no implementation for `{integer} == &{integer}`' şeklinde hata alırız
// point = 25; // Bunu yapamayız. Çünkü borrowing söz konusudur. point, pointer tarafında referansla da olsa ödünç alınmıştır
/* Yukarıdaki kullanımda pointer, point değerini referans eder. Aşağıdaki kullanımda ise counter değerinin bir kopyası Heap'e alınırken stack bölgesinden referans edilir. */ let mut counter = 1; let smart_pointer = Box::new(counter); assert_eq!(1, *smart_pointer); counter += 1; // Bu mümkündür çünkü smart pointer borrowing durumunu oluşturmamıştır
//assert_eq!(2, *smart_pointer); // counter kendi başına artar. Smart Pointer onun değerini koypalayarak kullandığı için halen 1'e eşittir
// Kendi smart pointer türümüzün kullanımı
let lucky_num = 2.777; let magic_box = MagicBox::create(lucky_num); assert_eq!(2.777, *magic_box);
}
/*
Kutsal Rustacean Kitabına göre Box yapısının referans türlerinden farkını anlamanı en iyi yolu kendi Smart Pointer türümüzü geliştirmekmiş.
Tabii herhangi bir türle çalışması isteneceğininde generic tanımlanıyor.
Tanımlayacağımız MagicBox yapısına create isimli bir fonksiyon da ekledik.(Box<T> türünün new fonksiyonu olarak düşünebiliriz) Ayrıca yukarıkdaki assert_eq!(2.777,*magic_box); satırında Deference operatörünün kullanımı söz konusu. Bunu da kendi Smart Pointer yapımıza öğretmemiz gerekiyor. Aksi durumda 'type `MagicBox<{float}>` cannot be dereferenced' şeklinde derleme zamanı hatası alırız. Sonuçta oradaki kıyaslama için de * operatörü ile derefer ederek değeri almamız lazım.
*/
struct MagicBox<T>(T);
impl<T> MagicBox<T> { fn create(value: T) -> MagicBox<T> { MagicBox(value) // MagicBox bir Tuple gibi tasarlandığından onu metoda parametre olarak gelen value değeri ile oluşturuyoruz
}
}
// Dereference için Deref Trait'inin uygulanması
use std::ops::Deref;
impl<T> Deref for MagicBox<T> { type Target = T; fn deref(&self) -> &T { &self.0 //Kara karıştırmasın. Tuple'ın ilk elemanının değerini döndürüyor }
}
/*
ConsList enum türüne bakalım. Cons fonksiyonunu ve Nil değerini içeriyor. Cons fonksiyonu da i32 türünden bir değer ve yine bir ConsList enum türü alıyor. İşte recursive veri yapısı.
Bunu bu haliyle bırakırsak derleme zamanı 'recursive type `ConsList` has infinite size' şeklinde hata döner. O yüzden ConsListV2 şeklinde tanımlayıp kullanmamız gerekiyor.
*/
// enum ConsList {
// Cons(i32, ConsList),
// Nil,
// }
enum ConsListV2 { Cons(i32, Box<ConsListV2>), // Box kullandığımız için artık veriyi Heap'ta tutacağımızı belirttik. Nil,
}
use crate::ConsListV2::{Cons, Nil}; // Bu küfe bildirimini yapmazsak infinity_war kullanımında 'not found in this scope' hatası alırızReference Counting
Smart Pointer'lar ile yakından ilişkili olan bir konu da reference counting'dir. Bir değerin birden fazla sahibi olduğu durumlar için geçerli bir konudur. Mesela bir graph ağacında bir boğumu işaret eden n sayıda boğum varsa, işaret edilen boğum için n sayıda sahiplikten söz edilebilir. Rc<T> aynı değeri işaret eden referanslar için muhasebeci görevini üstlenir. Öyleki aynı değeri işaret eden referansların sayısı ancak sıfırlanırsa bellekten atılabilir. Bu yönetim Rc ile kontrol altına alınır. Aslında bu kendi Garbage Collector mekanizmanızı yazmanın yolunu bile açar.
Örneğimizde Recursive veri yapılarından olan cons list kullanımı ele alınıyor. points1, points2 ve points3 birer Cons List. points2 ve points3 oluşturulurken ilk değerler sonrası points1 listesine bağlanıyorlar. Hem points2 hem points3 aynı listeyi(points1) paylaşmakta ki aslında paylaşamıyorlar. points3 kısmında derleme zamanı hatası oluşuyor. Bu nedenle Box<T> smart pointer türü yerine Rc<T> türünü kullanmak gerekiyor. Rreferance count değerlerini görmek için strong_count fonksiyonunu nasıl kullandığımıza bir bakın. points1 ilk oluştuğunda bu değer 1 dir. points2 points1'i kullanarak oluştuğunda bu değer 2'ye çıkar. points3 devreye girdiğinde sayaç 3'e çıkar çünkü toplamda 3 referans söz konusudur. {} bloğundan sonra ise points3 scope dışı kalır ve dolayısıyla referance count 1 azalır.
use crate::PointList::{Cons, Nil};
use std::rc::Rc; // Rc<T> veri yapısını kullanabilmek için eklendi
fn main() { // let points1 = Cons(7, Box::new(Cons(8, Box::new(Cons(9, Box::new(Nil)))))); //7->8->9->Nil şeklinde bir listemiz var // let points2 = Cons(1, Box::new(points1)); // let points3 = Cons(3, Box::new(points1)); // Normalde bu şekilde kullanırsak, bir üst satırda points1'in sahipliği points2'ye geçtiği için use of moved value: `points1` derleme zamanı hatası alırız
let points1 = Rc::new(Cons(7, Rc::new(Cons(8, Rc::new(Cons(9, Rc::new(Nil))))))); // Bir önceki kullanımdan farklı olarak Rc::new ile oluşturmaya başladığımıza dikkat edelim println!("Reference Count {}", Rc::strong_count(&points1)); let points2 = Cons(1, Rc::clone(&points1)); // clone fonksiyonunu kullanarak points1'in referansını geçiyoruz { println!("Reference Count {}", Rc::strong_count(&points1)); let points3 = Cons(3, Rc::clone(&points1)); println!("Reference Count {}", Rc::strong_count(&points1)); } println!("Reference Count {}", Rc::strong_count(&points1)); // let points4 = Cons(10, points1.clone()); // Performans açısından tercih edilmez /* Bu arada Rc::clone(&points1) kullanımı yerine points1.clone() da tercih edilebilir ancak Rc::clone deep copy yapmadığından ve sadece referansmatiği (Counter diyelim) 1 artırdığından çok daha hızlı işlem görür. */
}
// // Kobay cons list yapımız
// enum PointList {
// Cons(i32, Box<PointList>),
// Nil,
// }
// Kobay cons list yapımız
enum PointList { Cons(i32, Rc<PointList>), Nil,
}Fearless Concurrency
Eş zamanlı ve paralel programlama çok çekirdekli işlemcilerin hayatımıza girmesiyle birlikte önem kazanan başlıca iki konu olarak düşünülebilir. Concurrent Programming ile birbirlerinden bağımsız olarak çalışan program parçalarını, Parallel Programming ile de aynı anda çalışan program parçalarını kastediyoruz. Rust dilinin güçlü taraflarından birisi de Concurrency konusunda kendini göstermekte.
Bu zamana kadarki örneklerde ownership, type safety, borrowing vs gibi konuları görmüştük. Bunlar bellek güvenliği(memory safety) ve verimlilik açısından Rust'ı öne çıkaran başlıklar. Bu yetenekler sayesinde Concurrent programlama daha güvenli ve verimli hale geliyor. Nitekim pek çok dilin aksine Rust ortamında, Concurrent çözümlerde yaşanacak sorunlar çalışma zamanında değil daha derleme aşamasındayken görülebiliyor. Kim üretim ortamında gerçekeleşen bir concurrency hatasını geliştirme veya test ortamında tekrarlamaya çalışıp sorunun tam olarak ne olduğunu anlamaya çalışmak için çaba sarf etmek ister ki ;) Dolayısıyla Rust'ın bu sorunlara neden olabilecek sıkıntıları henüz derleme aşamasında söylemesi oldukça önemli. Rust'ın bu gücü için Fearless Concurrency terimi kullanılmakta. Tabii işin sırrı birçok işletim sistemi ve programlama dilinde olduğu gibi Thread'ler ile çalışmaktan geçiyor.
use std::thread; // Thread kütüphanemiz
use std::time::Duration; // Sembolik gecikmeler için
fn main() { example_one(); // Burada da main thread'i içerisinde çalışan bir döngü var // Ekrana 10 kere Bar yazacak println!("Ana thread başladı...");
for _i in 1..5 { println!("Bar"); thread::sleep(Duration::from_secs(1)); // ve bu ana thread'de 1er saniye gecikmeli çalışacak
} println!("Ana thread bitti..."); /* Bu ilk örnekte dikkat edilmesi gereken iki nokta var. A- example_one içerisinde thread'ler henüz bitmese de, yukarıdaki döngü bittiği için uygulama sonlanacak ve diğer thread'ler de ölmüş olacaktır. (join_handle örneğine bakın)
B- Ayrıca main içerisindeki sıra nasıl olursa olsun (ki burada example_one içerisindeki thread'ler önce çalışmak üzere yazılmıştır) ilk olarak ana thread içerisindeki kod çalıştırılır. Bu sebepten diğer thread'ler başlamadan önce 27nci satır mutlaka işletilir ve döngü derhal başlar. (Sanırım Main thread'in öncelikli olduğunu düşünebilirim) */
}
fn example_one() { // Bir thread açtık
std::thread::spawn(|| { println!("1 başladı...");
for _i in 1..10 { // Ekrana 10 defa Foo yazacak println!("Foo"); thread::sleep(Duration::from_secs(2)); // ve herbir yazma sonrası bu thread 2 saniye bekletilecek } println!("1 bitti..."); }); // Burada da ikinci bir thread açtık
// Bu kez bir vector'ün elemanları üzerinde işlem yaptığımızı varsayıyoruz
std::thread::spawn(|| { println!("2 başladı...");
for color in vec!["red", "green", "blue"] { println!("{}", color); thread::sleep(Duration::from_secs(2)); // ve yine 2 saniyelik bir gecikme } println!("2 bitti..."); });
}Örneğin çalışma zamanı çıktısı aşağıdaki gibi olacaktır.
![]()
Join Handle
Bir önceki örnekte ana thread işi bitirdiği için başlatılan ve halen devam eden diğer thread'lerin de sonlandığını gördük. Bu çok da istediğimiz bir durum değil. Bunu önlemek için JoinHandle<T> tipinden yararlanılabilir ve halen daha bitmemiş iş parçalarının bitmesinin beklenmesi sağlanabilir.
use std::thread;
use std::time::{Duration, SystemTime}; // Zaman ölçümlemeleri için ekledik
fn main() { let now = SystemTime::now(); // spawn geriye JoinHandle<T> nesnesi döndürür let wait_handle = std::thread::spawn(|| { println!("#1 başladı...");
for _i in 1..7 { // Ekrana 10 defa Black yazacak println!("BLACK"); thread::sleep(Duration::from_secs(2)); } println!("#1 bitti..."); }); // başka bir thread daha let another_wait_handle = std::thread::spawn(|| { println!("#2 başladı...");
for _i in 1..7 { // Ekrana 10 defa Black yazacak println!("RED"); thread::sleep(Duration::from_secs(4)); } println!("#2 bitti..."); }); println!("Ana thread başladı...");
for _i in 1..5 { println!("White"); thread::sleep(Duration::from_secs(1)); } println!("Ana thread bitti..."); // Main Thread'e ilk thread'in tamamlanmasını beklemesini söylüyoruz wait_handle.join().unwrap(); // Diğer thread'i de bekle diyoruz another_wait_handle.join().unwrap(); match now.elapsed() { Ok(elapsed) => { println!("Tüm işlemler için geçen toplam süre {}", elapsed.as_secs()); } Err(e) => { println!("Error: {:?}", e); } }
}Şimdi örneğin çıktısı aşağıdaki gibi olacaktır.
![]()
Join kullanımına ait başka bir örneği de aşağıda bulabilirsiniz. Bu kez iş parçaları bir döngü içerisinde kuyruğa alınmakta. Bu döngüde iş parçasının bitip bitmediğini pattern matching ile kontrol ettiğimize dikkat edelim.
use std::thread;
use std::time::{Duration, SystemTime}; // Zaman ölçümlemeleri için ekledik
fn main() { let now = SystemTime::now(); /* Döngü başlatılan thread'leri bir vector'de topluyor. Eğer move closure'ını kullanmazsak i değişkeni sahipliğinin ödünç olarak thread içerisine alınamamasından dolayı
derleme zamanı hatası alırız.
*/ let mut threads = vec![]; for i in 0..5 { threads.push(thread::spawn(move || { println!("{} başladı", i); for j in 1..5 { println!("Thread #{} da {} için bir şeyler yapılıyor gibi...", i, j); thread::sleep(Duration::from_secs(1)); } return i; // thread'den geriye bir değer döndürüyoruz. Bu değeri aşağıdaki pattern matching kullanımında yakaladık
// println!("{} sonlandı", i); })); } // Bitmeyen thread'ler için Main bekletiliyor. for t in threads { let result = t.join(); match result { Ok(r) => { println!("#{} tamamlandı", r); // Tamamlanan thread'den dönen değeri r ile alabiliriz } Err(e) => { println!("{:?}", e); } } } match now.elapsed() { Ok(elapsed) => { println!("Tüm işlemler için geçen toplam süre {}", elapsed.as_secs()); } Err(e) => { println!("Hata oluştu: {:?}", e); } }
}![]()
Counter Örneği
Thread'ler ile ilgili sıradaki örnek bir metin içerisindeki ç harflerinin sayısını bulmak için kullanılıyor. Ahım şahım bir örnek değil ama thread'ler için iyi bir antrenman olduğunu söyleyebilirim. Senaryoya göre document değişkeni pipe işaretlerine göre parçalarına ayrılıyor. Her bir parça üzerinde işlemler yapılması içinse birer thread açılıyor. Thread'ler içerisinde o thread'in ele aldığı içerikteki ç harfleri sayılıyor. Program sonunda bu değerler bir arada toplanarak ele alınıyor.
use std::thread;
fn main() { // üzerinde çalışacağımız değişken
let document = "Bugün epeyce Rust çalışmaya çalıştım|Çarşambanın gelişi bir önceki çarşambadan belli olur mu dersin|Kaç tane ç harfi yazalım|çççççççç demek istiyorum|Çok çalışmamız lazım...Çooookk çalışmamız";
// thread'leri toplayacağımız vector let mut workers = vec![]; // içeriği | işaretine göre ayrıştırdık
let rows = document.split('|'); for (i, row) in rows.enumerate() { println!("#{}->\"{}\"", i, row); // Burada yeni thread açıp workers'a ekliyoruz // Thread geriye kaç tane ç olduğunu dönecek workers.push(thread::spawn(move || -> u32 { let mut total = 0; for c in row.chars() { if c == 'ç' { total += 1; } } println!("#{} içerisinde {} tane ç harfi var", i, total); total })); } let mut all_totals = vec![]; // işlenen her bir satır için bulunan toplam değerleri biriktireceğimiz vector(ne uzun cümle yazdım yahu) /* Tüm worker'ların işlerini bitirmesini bekliyoruz. Worker'ların işi bittikçe döndürülen sonuçlar(ç'lerin toplmaları)
bir başka vector'de toplanıyor.
En sonunda da genel toplamı yazdırıyoruz.
*/ for worker in workers { let sub_total = worker.join().unwrap(); all_totals.push(sub_total); } let sum = all_totals.iter().sum::<u32>(); println!("Tüm dokümanda {} adet ç harfi varmış", sum);
}Bu örneğe ait çalışma zamanı çıktısı aşağıdaki gibidir.
![]()
Message Passing
Thread'lerin ortak veriler üzerinde işlem yapması gerektiği durumlarda eşzamanlılığı güvenli bir şekilde sağlamak için mesajlaşma tekniği uygulanır. Go'dan gelen motto burada da geçerliliğini korur; "Hafızayı paylaşarak iletişim kurmayın; bunun yerine iletişim kurarak hafızayı paylaşın" Rust dilinde de Go'dakine benzer şekile channel kullanımı söz konusudur. Kanaldan faydalanarak thread'ler aralarında haberleşme sağlanabilir. Bir channel nesnesi verici(Transmitter) ve alıcı(Receiver) olmak üzere iki parçadan oluşur. Örneğin n adet thread'in bir hesaplama yapıp bu hesaplamaları işlenmek(aggregate)üzere başka bir thread'e gönderdiğini düşünelim. Bu channel nesne kullanımı için ideal bir senaryodur.
use std::sync::mpsc; // Multiple Producer Single Consumer
use std::thread;
use std::time::Duration;
fn main() { /* #1 İlk olarak bir kanal nasıl açılır, bu kanale bir thread üstünden mesaj nasıl basılır ve tabii basılan mesaj başka bir thread tarafından nasıl alınır bakalım.
channel tanımlandığında geriye bir tuple döner tx, transmitter(yayıncı) rx ise receiver(alıcı) nesneleri işaret eder */ let (tx, rx) = mpsc::channel(); // move kullandık ki tx'i closue ile kullanabilelim let worker1 = thread::spawn(move || { println!("#1 Jennifer tepeden nehre bir plastik ördek bırakıyor. Aklında bir sayı var."); let calculated_value = 3.1415; tx.send(calculated_value).unwrap(); // transmitter ile kanala mesajımızı/değeri bırakıyoruz
/* worker'lar pek tabi eş zamanlı olarak işe başlarlar.
Aşağıda worker1 sembolik olarak uzun süre bir iş yapsa da, yukarıda kanala bir mesaj bırakmıştır ve diğer thread'ler bu mesajı duraksatmaya aldırmadan alıp kullanabilirler ;) */ thread::sleep(Duration::from_secs(3)); }); let worker2 = thread::spawn(move || { println!("#2 Alice, Jennifer'ın gönderdiği plastik ördeği bekliyor."); let received_value = rx.recv().unwrap(); //receiver ile kanala bırakılan mesajı yakalıyoruz
println!( "Kanala bırakılan plastik ördeğin aklındaki sayı: {}", received_value ); }); worker1.join().unwrap(); worker2.join().unwrap(); println!(); /* #2 Aşağıdaki kod bloğu safe concurency sebebiyle derlenmez. Transmitter değişkeninin send metodu, outgoing referansının sahipliğini alır
ve bu değişken gönderildikten sonra bu sahiplik receiver'a geçer. Bu nedenle spawn bloğunda send çağrısı sonrası outgoing değişkeni artık kullanılamaz.
Bunun sebebi bir thread'in kanala bıraktığı değeri sonradan kendisinin değiştirmesini engellemektir. Lakin gönderilen değişkenin gönderildiği haliyle receiver tarafından kullanılmasını isteriz. */ let (tx, rx) = mpsc::channel(); thread::spawn(move || { let outgoing = String::from("Eco Eco Bravo 6 Eco...Burası Kartal Kondu. Tamam"); tx.send(outgoing).unwrap(); // println!("{}", outgoing); // Derleme hatasını görmek için bu satırı etkinleştirin
}); let incoming = rx.recv().unwrap(); println!("{}", incoming); println!(); /* #3 Pek tabii en sık başvurulacak senaryolardan birisi de n sayıda thread'den mesaj gönderip almak. Yani Multiple Consumer Single Receiver olayı.
Burada önemli olan nokta transmitter'ın klonlanması.
Aşağıdaki örnek kod parçasında tx nesnesi klonlanmış ve diğer thread'ler tarafında kullanılabilir hale gelmiştir.
*/ let (tx, rx) = mpsc::channel(); let tx_kadikoy = mpsc::Sender::clone(&tx); let tx_besiktas = mpsc::Sender::clone(&tx); thread::spawn(move || { let status = String::from("Üsküdar da hava açık ve 23 derece"); tx.send(status).unwrap(); thread::sleep(Duration::from_secs(3)); }); thread::spawn(move || { let status = String::from("Kadıköy de hava açık ve 22,4 derece"); tx_kadikoy.send(status).unwrap(); thread::sleep(Duration::from_secs(1)); }); thread::spawn(move || { let status = String::from("Beşiktaş da hava yer yer rüzgarlı ve 21 derece"); tx_besiktas.send(status).unwrap(); thread::sleep(Duration::from_secs(5)); }); let last_standing_man = thread::spawn(move || { /* tx, tx_kadikoy ve tx_besiktas transmitter'ları üstünde gelen mesajlar rx nesnesi üstünden yakalanabilirler. */ for current_status in rx { println!("{}", current_status); } }); last_standing_man.join().unwrap(); println!(); /* #4 Transmitter üstünden kanala n sayıda mesaj da bırakılabilir.
Aşağıdaki kod parçasında aynı thread içinden aralıklarla birkaç mesaj yollanıyor. Bu mesajlar yine rx'i kullandığımız bir for döngüsü ile alınıyorlar.
sleep'ler ile yaptığımız duraklatmalar mesaj yollandıkça dinleyici tarafından
alınır durumunu göstermek için. */ let (tx, rx) = mpsc::channel(); thread::spawn(move || { let value_1 = String::from("1 kilo un"); tx.send(value_1).unwrap(); thread::sleep(Duration::from_secs(1)); let value_2 = String::from("3 yumurta"); tx.send(value_2).unwrap(); thread::sleep(Duration::from_secs(3)); let value_3 = String::from("Yarım çay bardağı kadar şeker");
tx.send(value_3).unwrap(); thread::sleep(Duration::from_secs(2)); }); for received in rx { println!("{}", received); }
}
ve tabii ki çalışma zamanı çıktısı.
![]()
Mutexes
Rust dilinde kanallardan yararlanarak mesajlaşma yapan eş zamanlı thread'leri nasıl kullanabileceğimizi gördük. Kanallar (Channels) aslında tekil mülkiyet hakkı sağlarlar. Yani bir thread kanala bir veri bıraktığında bu veri onun için artık kullanılabilir değildir. Buna karşın birden fazla thread'in aynı anda aynı bellek bölgesini kullanmak isteyeceği durumlarda mümkündür. Bu tip durumların kanallar haricinde bir diğer yönetim şekli ise Mutex tipi ile gerçekleşir. Kanallar nasıl tekil mülkiyetliği baz alıyorsa, Mutex tipi de smart pointer'lar gibi çoklu mülkiyet/sahiplik hakkını baz alır(Keza Mutex<T> bir smart pointer'dır) Bir thread Mutex'e alınan bir veriyi kullanmak istediğinde bunu öncelikle ona sorar ve eğer müsaitse verinin kilidini(lock) alır. İşi bitince de serbest bırakır.
Özetle çoklu thread'lerin aynı veriyi kullanmak istemeleri halinde t anında sadece bir tanesinin onu kullanmasına nasıl izin vereceğimizi bilmemiz gerekiyor. Mutex bu anlamda nasıl bir çözüm sunuyor görelim.
use std::sync::{Arc, Mutex};
use std::thread;
fn main() { /* #1 İki thread Mutex kullanırken.
worker_sue içinde "use of moved value" derleme zamanı hatası alırız.
*collector satırında ise "borrow of moved value" derleme zamanı hatasını alırız.
*/ // // Mutex nesnesini oluşturuyoruz. Tutacağı veri 32 bit integer ve değeri 1 // let collector = Mutex::new(1); // // Bir thread başlatılıyor
// let worker_joe = thread::spawn(move || { // // mutex'in kilidini alıyoruz ve işimiz bitene kadar thread'i blokluyoruz // let mut point = collector.lock().unwrap(); // // Burada kilidi bizde olan Mutex verisinin değerini değiştirdik
// *point += 5; // }); // // Scope dışına çıktığımız anda Mutex'in kilidini de devretmiş olduk. Dolayısıyka başka bir thread artık bu kilidi alabilir. // /* // Aşağıdaki satırda "use of moved value" hatası alınır
// Rust, collector'un mülkiyetinin birden fazla thread'e alınamayacağını söyler. // Dikkat edin. Üst taraftaki thread için derleyici kızmaz. Aşağıdaki move || satırının altını çizerek kızar.
// */ // let worker_sue = thread::spawn(move || { // let mut point = collector.lock().unwrap(); // *point += 3; // }); // worker_joe.join().unwrap(); // worker_sue.join().unwrap(); // println!("{}", *collector.lock().unwrap()); /* #2 Üstteki kodda bildiğiniz üzere mülkiyet sorunu yaşadık.
Thread Safe olarak Mutex'i diğer thread'lerin de kullanılmasını sağlamak için, Atomic Reference Counting Arc<T> tipinden yararlanabiliriz. Kodun çalışır hali aşağıdaki gibidir. Mutex verisini değiştirmek ve son halini almak için Arc üstünde klonladığımız referanslar olduğuna dikkat edelim. */ let main_collector = Arc::new(Mutex::new(1)); let mid_collector = Arc::clone(&main_collector); let last_collector = Arc::clone(&main_collector); // Buna neden ihtiyaç duydum? let worker_joe = thread::spawn(move || { let mut point = main_collector.lock().unwrap(); *point += 5; }); let worker_sue = thread::spawn(move || { let mut point = mid_collector.lock().unwrap(); *point += 3; }); worker_joe.join().unwrap(); worker_sue.join().unwrap(); println!("{}", *last_collector.lock().unwrap());
}Rust dilinde şimdilik buraya kadar gelebildim. Gerçek saha tecrübem olmadığı için halen daha başlangıç seviyesinde olduğumu söyleyebilirim. Sürekli kodlamak sürekli onunla haşırneşir olmak gerekiyor ki biraz olsun hakimiyet kazanabileyim. Bakalım bir sonraki yıl buna zaman ayırabilecek miyim. Gelelim bu uzun öğretiye ait size verebileceğim ödevelere ve sorulara.
Sorular
- Rust dilinde değişkenler neden varsayılan olarak immutable işaretlenir?
- factorial örneğindeki expect fonksiyonları hangi hallerde devreye girer? panic durumları bu kod parçasında nasıl ele alınır?
- lucky_number örneğindeki match kullanımlarının ne işe yaradığını bir arkadaşınıza anlatınız?
- Büyük veri yapısına sahip bir tipi mutable olarak kullanmak mı uygundur, immutable olarak mı? Yoksa duruma göre değişir mi?
- shadowing hangi durumlarda mantıklı olabilir?
- Ne zaman array ne zaman vector kullanmak uygun olur?
- C# dilinde String atama ve metotlara parametre olarak geçme davranışları ile Rust tarafındakileri karşılaştırın.
- ownership uygulamasının aldığı derleme zamanı hatasının sebebi nedir?
- Hiçbir alan(field) içermeyen bir struct tanımlanabilir mi? Buna izin veriliyorsa amaç ne olabilir?
- structs örneğinde yer alan println!("{}", mouse.title); kod parçası açılırsa neden derlenmez?(Line: 18)
- Yine structs örneğinin 19ncu satırındaki kod, mouse değişkeni mut ile mutable yapılsa dahi derleme hatasına neden olacaktır. Neden?
- Bir enum yapısındaki değişkenler başka enum değişkenlerini de içerebilir mi?
- Bir vector koleksiyonunda farklı tipten elemanlar tutmak istersek ne yaparız?
- String'leri + operatörü ile birleştirirken neden & ile referans adresi kullanırız?
- collections örneğinde a_bit_off_word değişkenine siyah isimli metindeki ilk karakteri almak ve panic durumunun oluşmasını engellemek için ne yapılabilir?
- Unwinding kabiliyeti nasıl etkinleştirilir?
- traits isimli örnekte yer alan Action içerisindeki initialize metodunun Hyperlink fonksiyonu için kullanılmasını istemezsek nasıl bir yol izlememiz gerekir
- lifetimes isimli programdaki #1 örneğinde oluşan derleme zamanı hatasını nasıl düzeltiriz?
- Bir fonksiyon birden farklı generic lifetime parametresi kullanabilir mi?
- Bir test fonksiyonu sonuç dönebilir mi?
- Ne zaman normal fonksiyon ne zaman closure kullanılır?
- iterators2 örneğinde yer alan Game struct'ı için neden #[derive(PartialEq, Debug)] niteliği uygulanmıştır?
- cons list kullanmamızı gerektirecek bir durum düşünün ve tanıdığınız bir Rustacean'a bunu anlatın.
- Rc<T> kullanmamızı gerektirecek en az bir senaryo söyleyebilir misiniz?
- Arc<T>(Atomic Reference Counting) tipi hangi amaçla kullanılır?
- Bir struct değişkenini match ifadesi ile kullanabilir miyiz?
Ödevler
- lucky_number örneğindeki cpm işlem sonucunu match yerine if blokları ile tesis ediniz.
- lucky_number örneğinde loop döngüsü kullanmayı deneyiniz.
- Bir kitabı birkaç özelliği ile ifade eden bir struct yazıp, bu kitabın fiyatına belirtilen oranda indirim uygulayan metodu geliştiriniz(Metot, impl bloğu ile tanımlanmalı)
- mercury isimli kütüphaneyi başka bir rust uygulamasında kullanabilir misiniz? Nasıl?
- Bir String içeriğini tersten yazdıracak fonksiyonu geliştiriniz?(rev kullanmak yasak)
- error_handling örneğinde 69ncu satırda başlayan ifadede i32'ye dönüşemeyen vector değerlerini hariç tuttuk. Geçersiz olan değerleri de toplayıp ekrana yazdırabilir misiniz?(ipucu : partition fonksiyonu)
- İki kompleks sayının eşit olup olmadığını kontrol eden trait'leri geliştiriniz.
- Iterator trait'ini yeniden programlayarak Fibonnaci sayı dizisini belli bir üst limite kadar ekrana yazdırmayı deneyiniz.
- Fizz Buzz kod katasını Rust ile Test Driven Development odaklı olarak uygulayınız.
- reader uygulamasındaki akış kodlarını ayrı bir kütüphaneye alın.
- .Netçiler!!! Birkaç LINQ sorgusunu closure'ları kullanarak icra etmeye çalışınız.
- Closures örneğinde yer alan get_fn fonksiyonunu inceleyin. Sizde farklı bir senaryo düşünüp geriye koşula göre fonksiyon döndüren ama Fn yerine FnMut trait'ini ele alan bir kod parçası yazmayı deneyin.
- iter fonksiyonu üstünden örneğin 1den 100e kadar olan sayılardan sadece kendisi ve 1 ile bölünülebilenleri(asal olanları) elde etmeye çalışın.
- hof örneğinde 28nci satırdaki filter fonksiyonuna bakın. Burada calc fonksiyonunu çağırmadan aynı hesaplamayı yaptırmaya çalışın.
- M:N ve 1:1 thread modelleri nedir, araştırınız? Öğrendiklerinizi bir arkadaşınızla paylaşıp konuyu tartışarak pekiştiriniz.
- counter uygulamasını genişletelim. En az 20 paragraftan oluşan bir word dokümanı hazırlayın. Herbir paragraf için ayrı bir thread çalıştırın. Herbir thread ilgili paragrafta bizim söylediğimiz kelimelerden kaç tane geçtiğini case-sensitive veya case-insensitive olarak hesaplasın.
- _ ve .. operatörlerinin kullanım alanları nerelerdir, araştırıp deneyiniz.
Böylece geldik bir SkyNet derlememizin daha sonuna. Tekrardan görüşünceye dek hepinize mutlu günler dilerim.
![]()
 Uzun süre önce bankada çalışırken nereye baksam servis görüyordum. Bir süre sonra ana bankacılık uygulaması dahil pek çok ürünün kullandığı bu sayısız servisler ağının yönetimi zorlaşmaya başladı. Bir takım ortak işlerin daha kolay ve etkili yönetilmesi gerekiyordu. Müşterek bir kullanıcı doğrulama ve yetkilendirme kontrolü(authentication & authorization), yük dengesi dağıtımı (load balancing), birkaç servis talebinin birleştirilmesi ve hatta birkaç servis verisinin birleştirilerek döndürülmesi(aggregation), servis verisinin örneğin XML'den JSON gibi farklı formata evrilmesi, servis geliş gidişlerinin loglanması, yönlendirmeler yapılması(routing), performans için önbellek kullanılması(caching), servis hareketliliklerini izlenmesi(tracing), servislerin kolayca keşfedilmesi(discovery), çağrı sayılarına sınırlandırma getirilmesi, bir takım güvenlik politikalarının entegre edilmesi, özelleştirilmiş delegeler yazılması(custom handler/middleware), tüm uygulamalar için ortak bir servis geçiş kanalının konuşlandırılması ve benzerleri. Yazarken yoruldum, daha ne olsun :D Sonunda Java tabanlı WSO2 isimli bir API Gateway kullanılmasına karar verildi.
Uzun süre önce bankada çalışırken nereye baksam servis görüyordum. Bir süre sonra ana bankacılık uygulaması dahil pek çok ürünün kullandığı bu sayısız servisler ağının yönetimi zorlaşmaya başladı. Bir takım ortak işlerin daha kolay ve etkili yönetilmesi gerekiyordu. Müşterek bir kullanıcı doğrulama ve yetkilendirme kontrolü(authentication & authorization), yük dengesi dağıtımı (load balancing), birkaç servis talebinin birleştirilmesi ve hatta birkaç servis verisinin birleştirilerek döndürülmesi(aggregation), servis verisinin örneğin XML'den JSON gibi farklı formata evrilmesi, servis geliş gidişlerinin loglanması, yönlendirmeler yapılması(routing), performans için önbellek kullanılması(caching), servis hareketliliklerini izlenmesi(tracing), servislerin kolayca keşfedilmesi(discovery), çağrı sayılarına sınırlandırma getirilmesi, bir takım güvenlik politikalarının entegre edilmesi, özelleştirilmiş delegeler yazılması(custom handler/middleware), tüm uygulamalar için ortak bir servis geçiş kanalının konuşlandırılması ve benzerleri. Yazarken yoruldum, daha ne olsun :D Sonunda Java tabanlı WSO2 isimli bir API Gateway kullanılmasına karar verildi.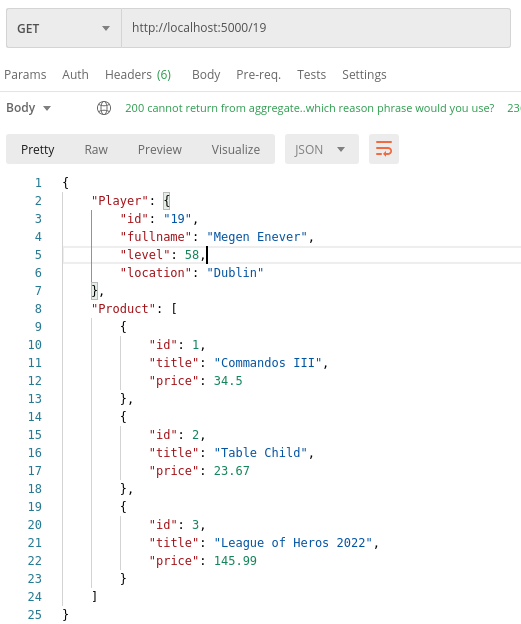
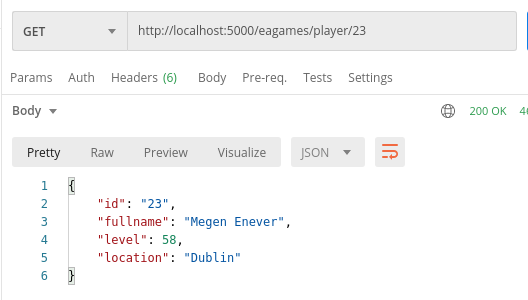
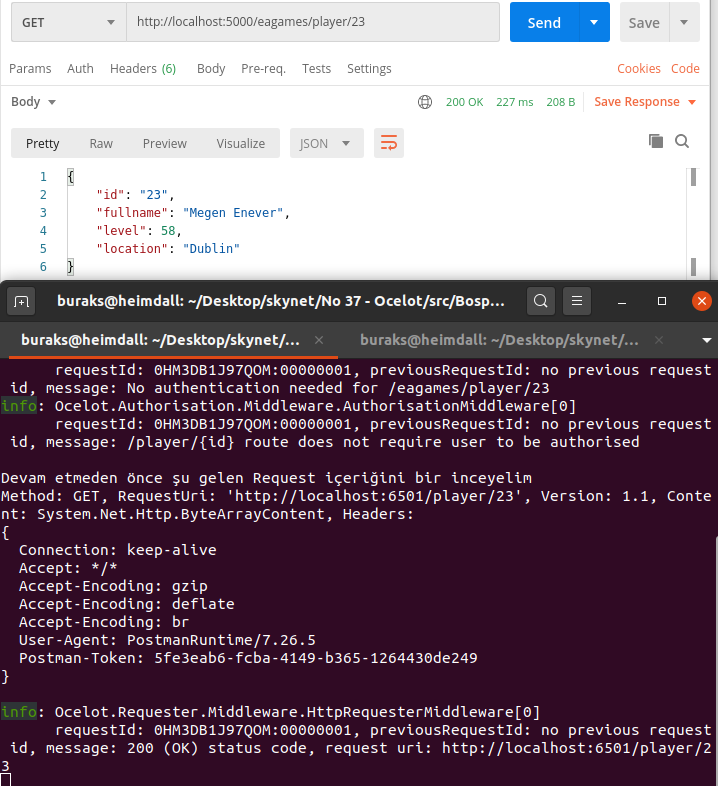
 Yazılım işine girdiğimden beri en çok zorlandığım konu Frontend tarafında kodlama yapmak. Ne yazık ki sadece Backend tarafta kalma lüksümüz de pek bulunmuyor. Örneğin hali hazırda çalışmakta olduğum firmada yeni nesil birçok uygulama önyüz tarafında çeşitli Javascript çatıları(Framework) kullanıyor.
Yazılım işine girdiğimden beri en çok zorlandığım konu Frontend tarafında kodlama yapmak. Ne yazık ki sadece Backend tarafta kalma lüksümüz de pek bulunmuyor. Örneğin hali hazırda çalışmakta olduğum firmada yeni nesil birçok uygulama önyüz tarafında çeşitli Javascript çatıları(Framework) kullanıyor.

 Heimdall üstünden birşeyler kurcalamak istediğimde yolum genellikle bir Docker imajı ile kesişiyor. Bakmak istediğim bir NoSQL veritabanı mı var, ELK üçlüsü mü gerekli, bir NGinx server ortamımı lazım ya da yeni bir servis için çalışma zamanımı hazırlamam gerekiyor... Hemen Docker kardeşimizin kapısını çalıyorum. Aslında bakarsanız Container teknolojileri denince çoğumuzun aklına Docker'dan başka bir şey gelmiyordur belki de. "Gerçekten de böyle mi?" diye düşündüğüm bir ara Docker'ın güçlü bir alternatifi olan Podman isimli ürünle karşılaştım ve onu biraz tanımaya karar verdim.
Heimdall üstünden birşeyler kurcalamak istediğimde yolum genellikle bir Docker imajı ile kesişiyor. Bakmak istediğim bir NoSQL veritabanı mı var, ELK üçlüsü mü gerekli, bir NGinx server ortamımı lazım ya da yeni bir servis için çalışma zamanımı hazırlamam gerekiyor... Hemen Docker kardeşimizin kapısını çalıyorum. Aslında bakarsanız Container teknolojileri denince çoğumuzun aklına Docker'dan başka bir şey gelmiyordur belki de. "Gerçekten de böyle mi?" diye düşündüğüm bir ara Docker'ın güçlü bir alternatifi olan Podman isimli ürünle karşılaştım ve onu biraz tanımaya karar verdim.
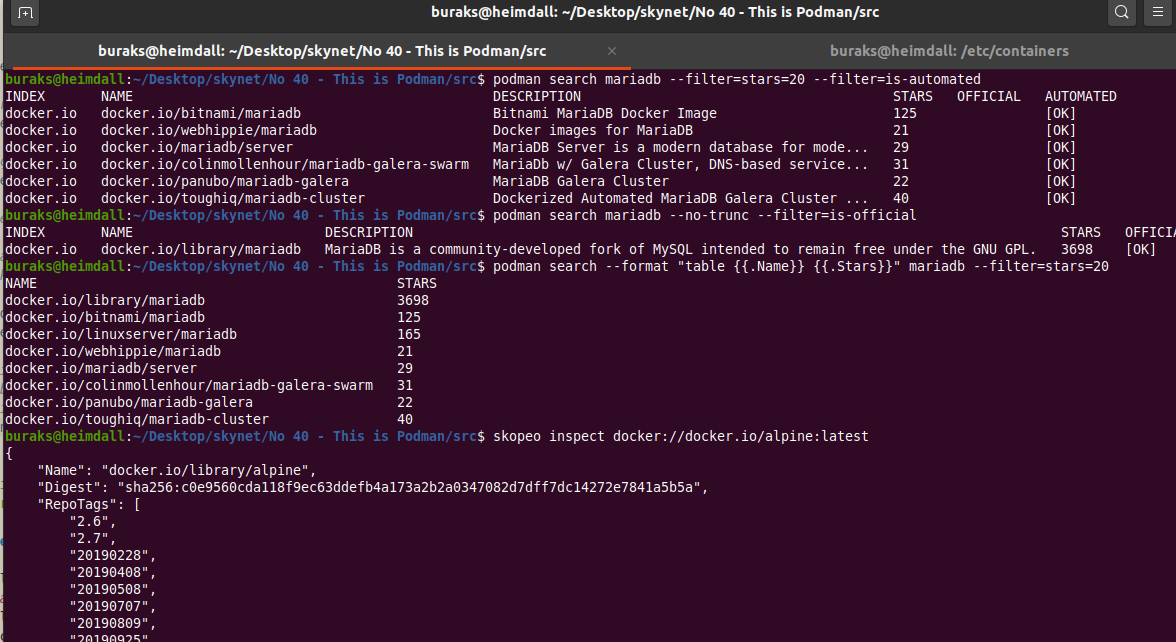
 Hepimiz için berbat geçen bir yılı geride bırakıyoruz. Koca sene boyunca uğraştığımız salgının etkileri daha da sürecek gibi duruyor. 2021 bize neler getirir bilemiyorum ama yazılımcıların bilgisayarları başında daha çok vakit geçirdiği günlerin hayatımızda kalıcı hale geldiğini de ifade edebilirim. Geçen yılın bir bölümünde işlerden arta kalan vakitlerde kendimce yeni şeyler öğrenmeye gayret ettim. Bunlardan birisi de Mozilla Labs'ın gücünü arkasına almış olan Rust programlama diliydi.
Hepimiz için berbat geçen bir yılı geride bırakıyoruz. Koca sene boyunca uğraştığımız salgının etkileri daha da sürecek gibi duruyor. 2021 bize neler getirir bilemiyorum ama yazılımcıların bilgisayarları başında daha çok vakit geçirdiği günlerin hayatımızda kalıcı hale geldiğini de ifade edebilirim. Geçen yılın bir bölümünde işlerden arta kalan vakitlerde kendimce yeni şeyler öğrenmeye gayret ettim. Bunlardan birisi de Mozilla Labs'ın gücünü arkasına almış olan Rust programlama diliydi.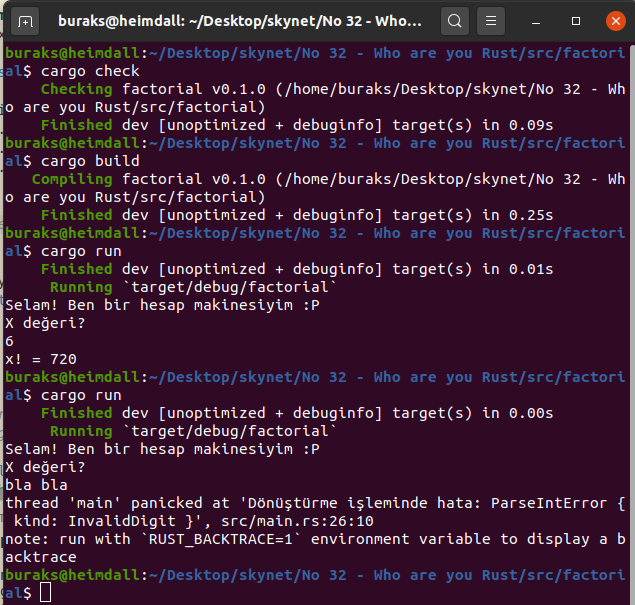
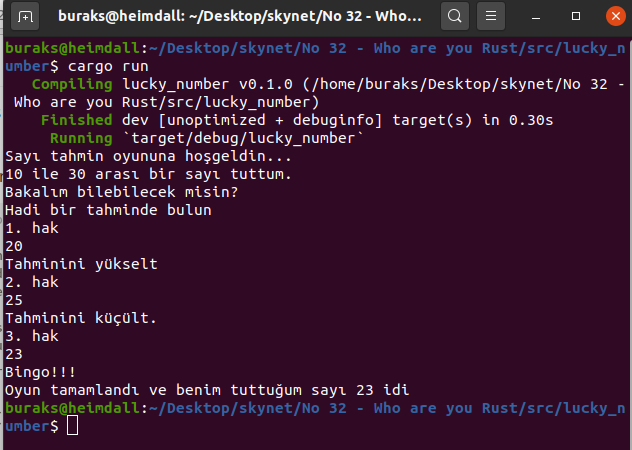
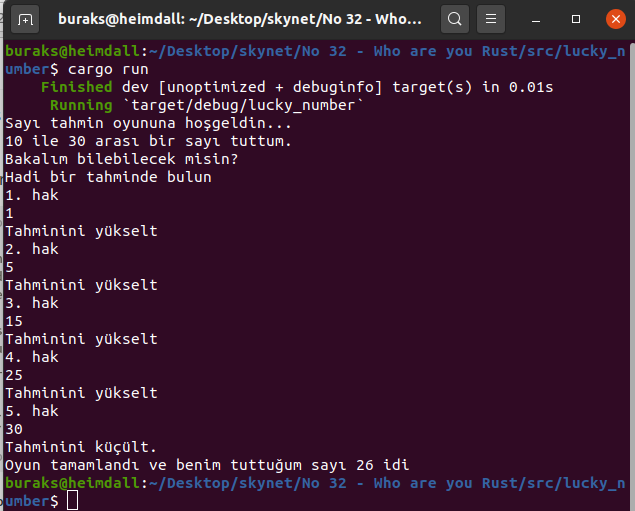
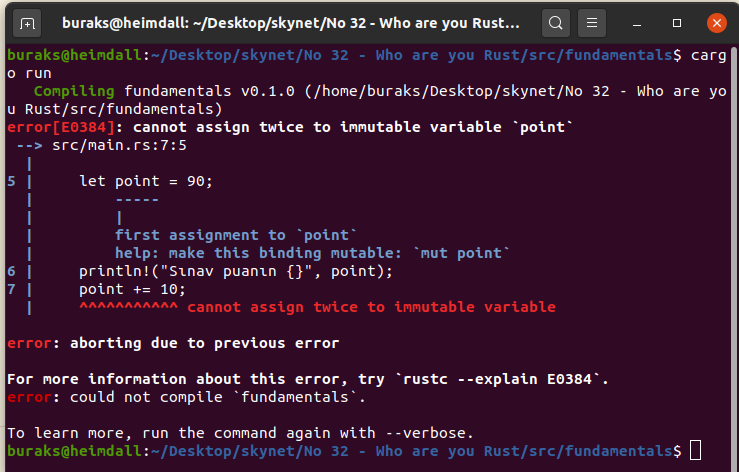
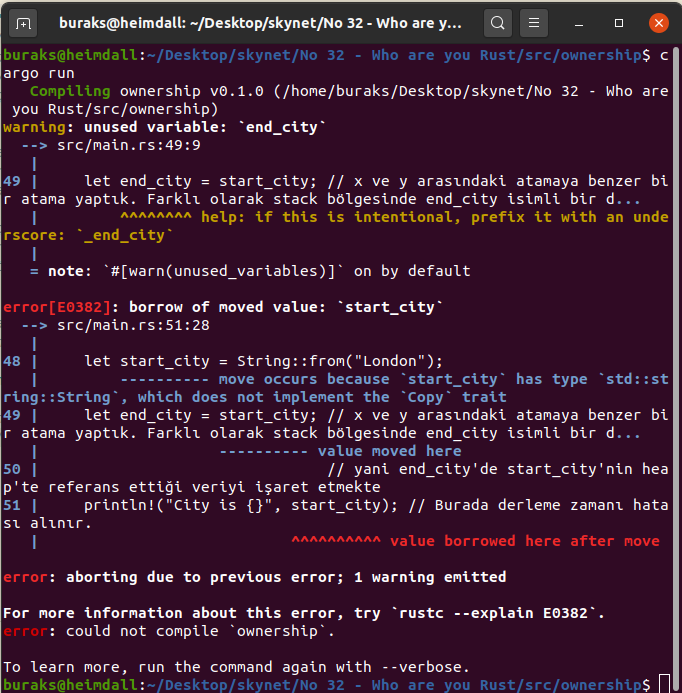
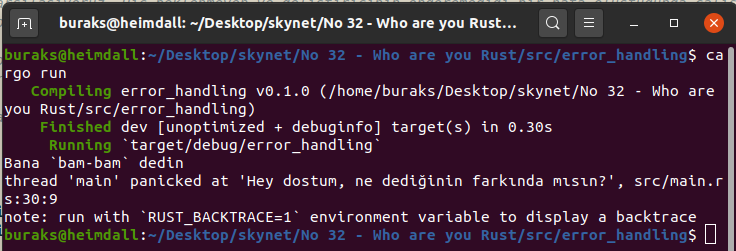 ardından Result<T,E> ile olayı kontrol altında tutma çabası.
ardından Result<T,E> ile olayı kontrol altında tutma çabası.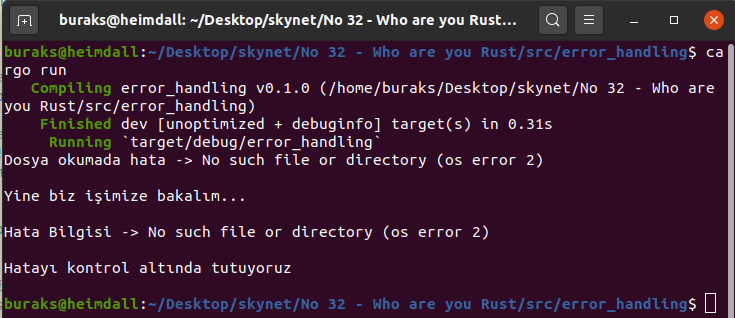
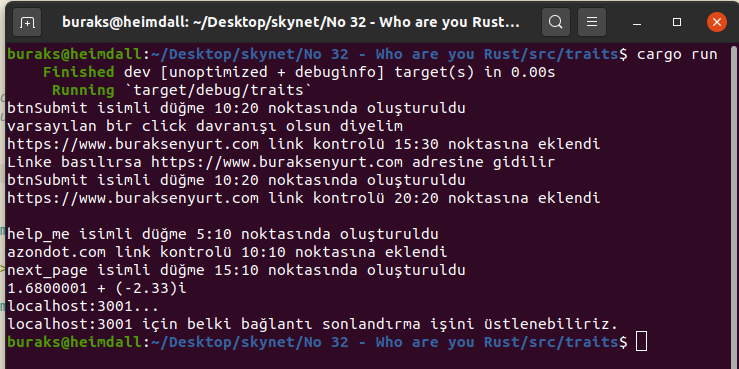
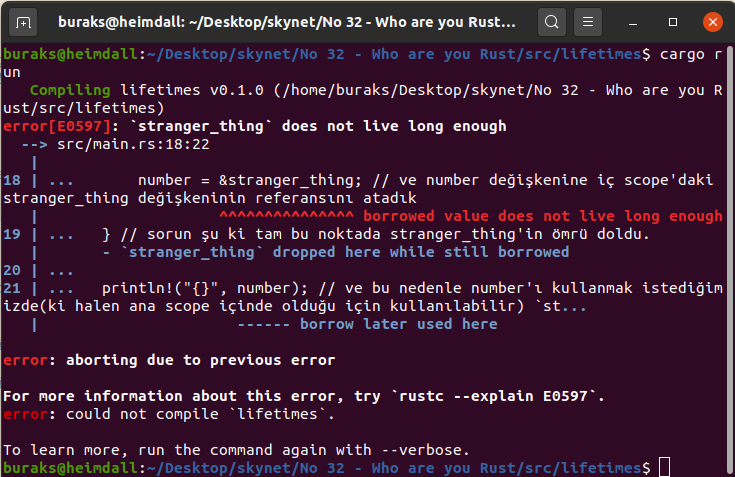
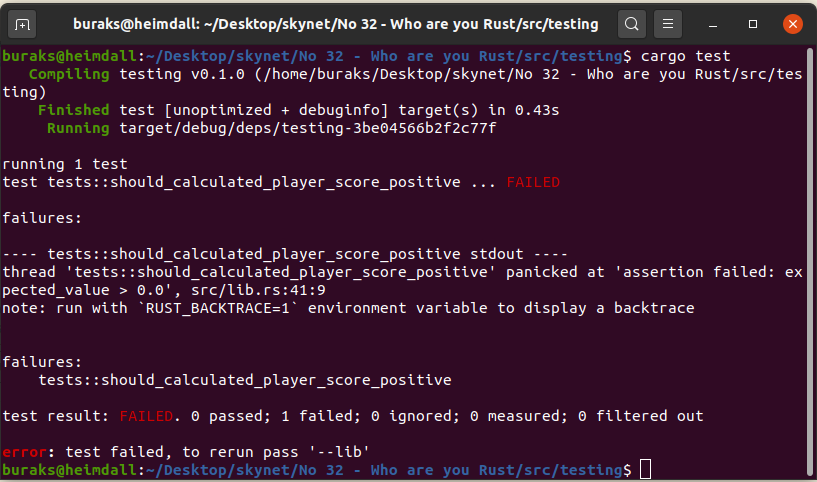
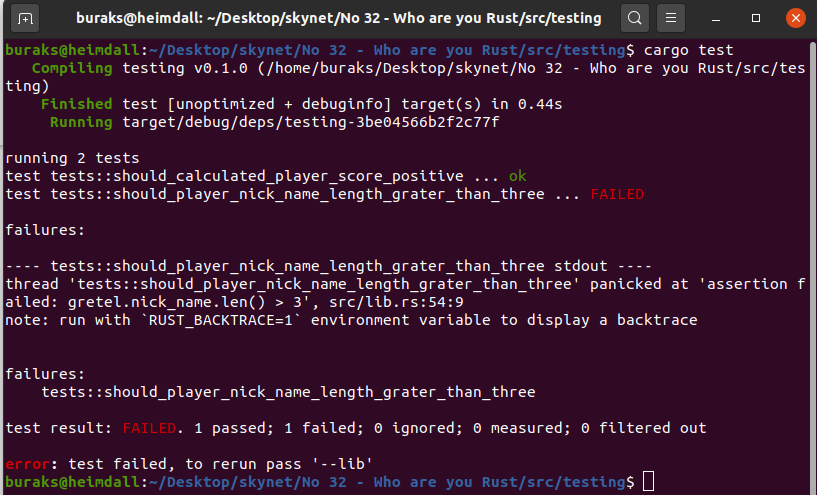
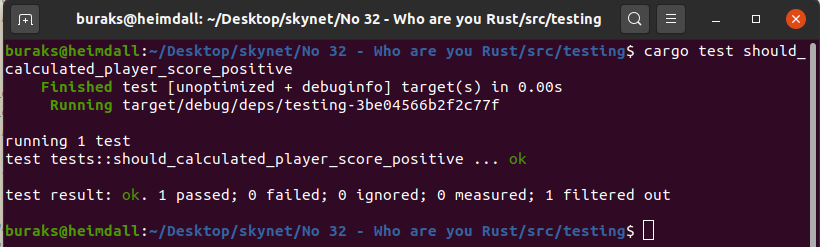
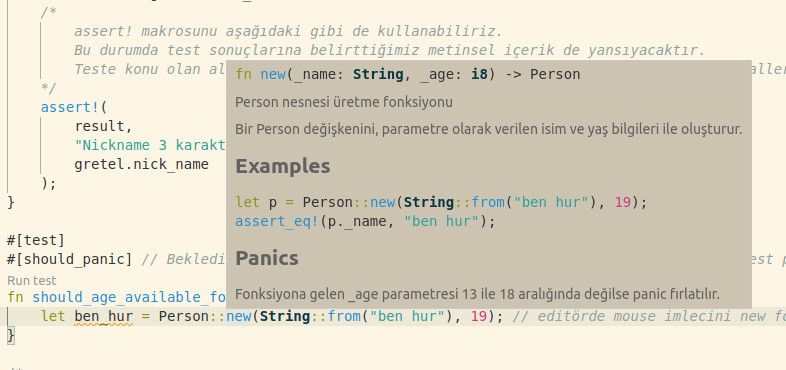
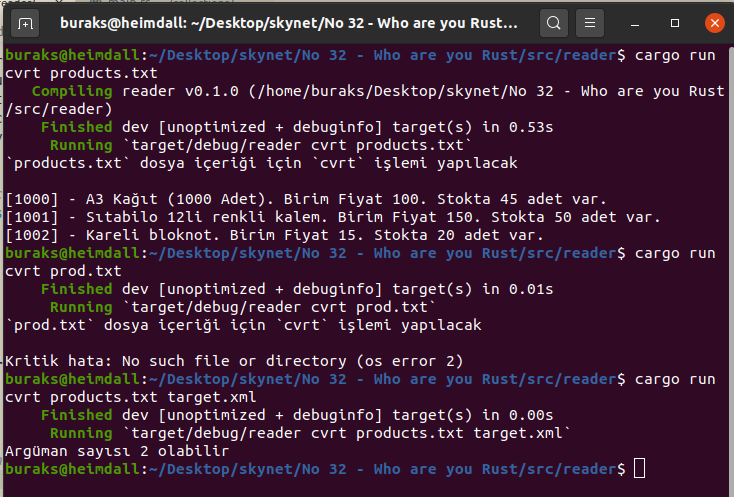
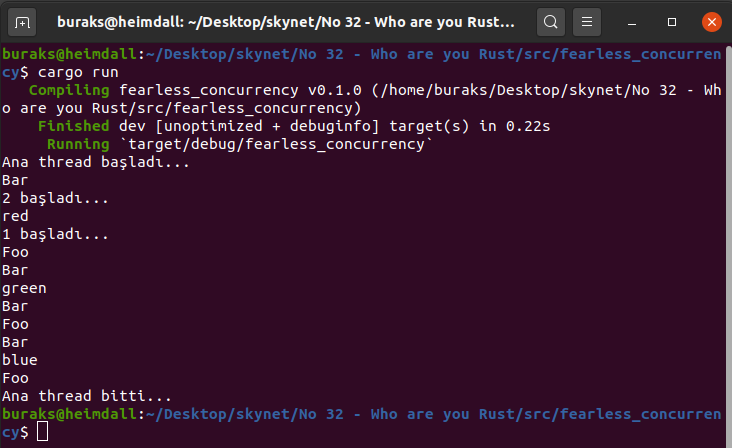
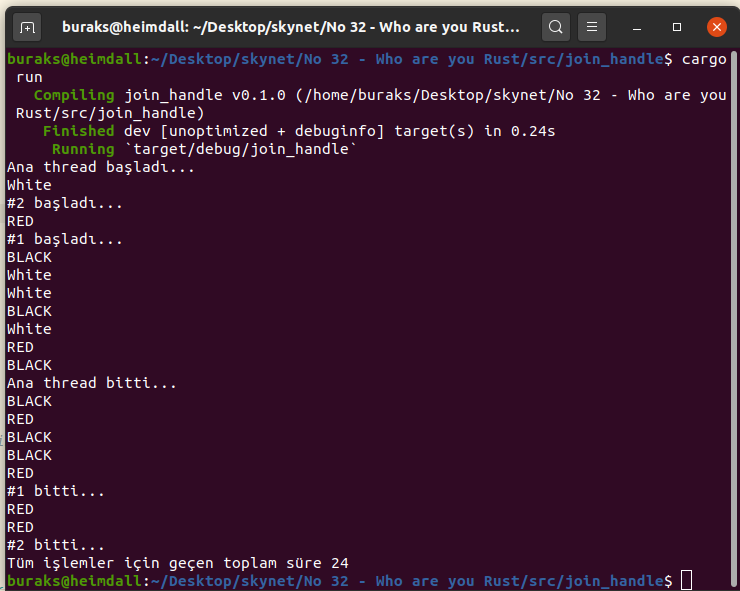
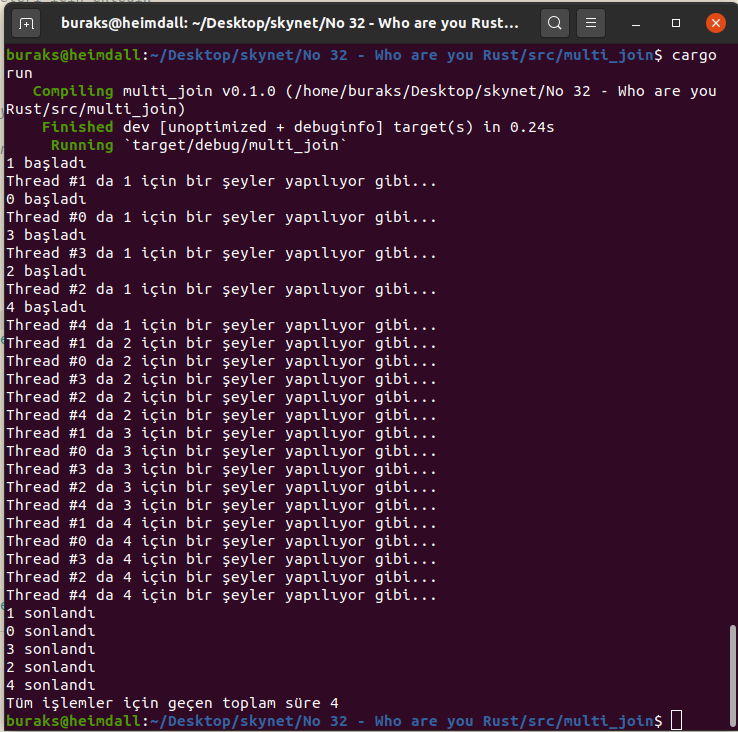
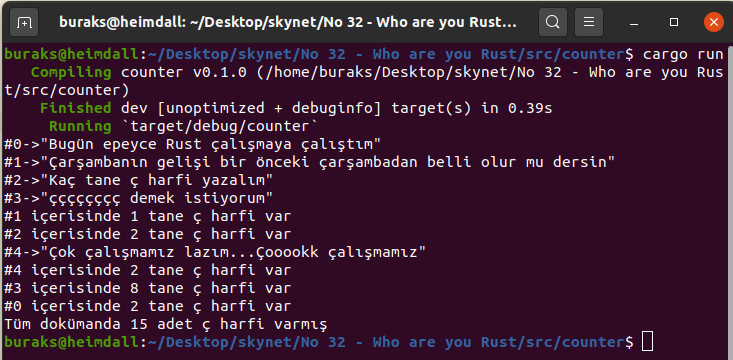
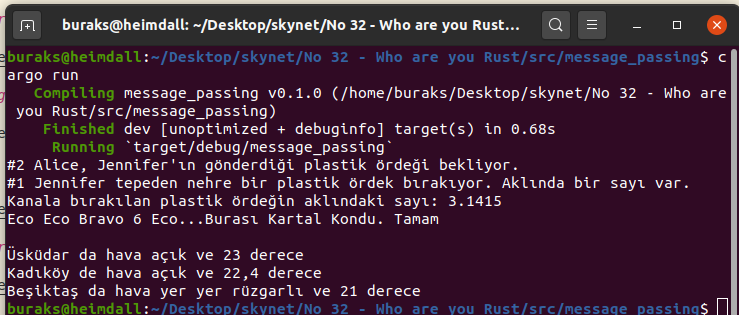
 Star Wars'ın figür kabul edilen gemilerinden birisi imparatorluk güçlerinin Tie Fighter'ıdır. Lord Vader ile özdeşlemiş olan bu figürün kulak tırmalayan ama rahatsız etmeyen sesinin Almanların İkinci Dünya savaşındaki hafif bombardıman uçaklarından birisi olan Junkers Ju-87 Stuka'dan (Sturzkampfflugzeug) geldiği bile söylenir.
Star Wars'ın figür kabul edilen gemilerinden birisi imparatorluk güçlerinin Tie Fighter'ıdır. Lord Vader ile özdeşlemiş olan bu figürün kulak tırmalayan ama rahatsız etmeyen sesinin Almanların İkinci Dünya savaşındaki hafif bombardıman uçaklarından birisi olan Junkers Ju-87 Stuka'dan (Sturzkampfflugzeug) geldiği bile söylenir.
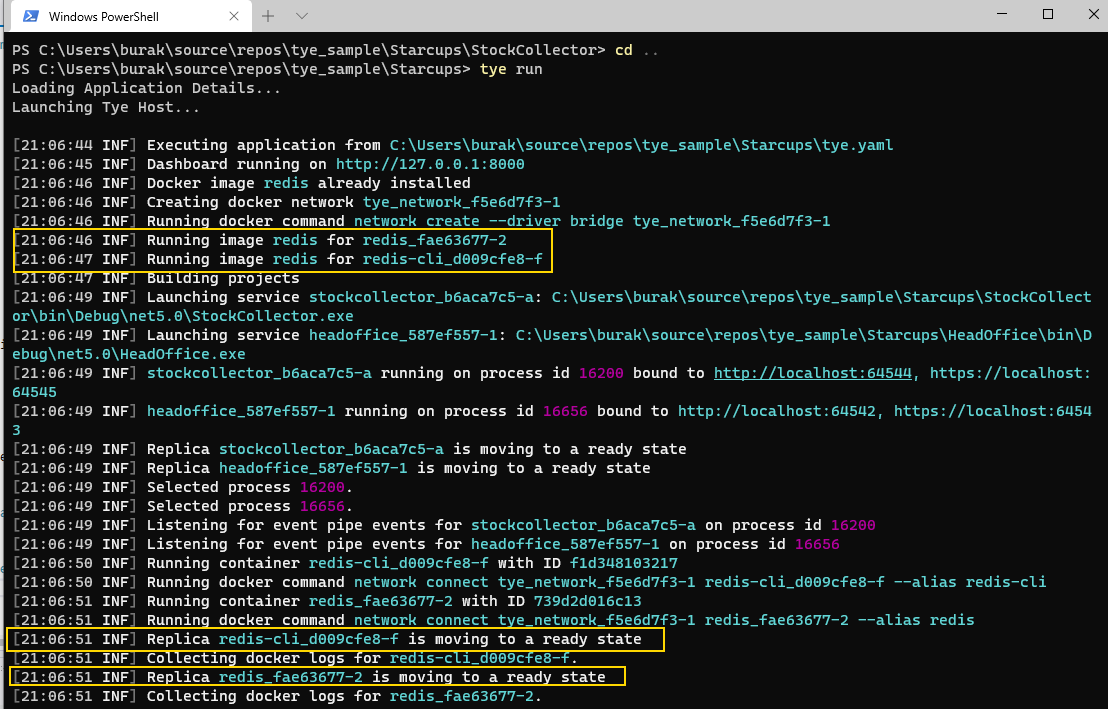
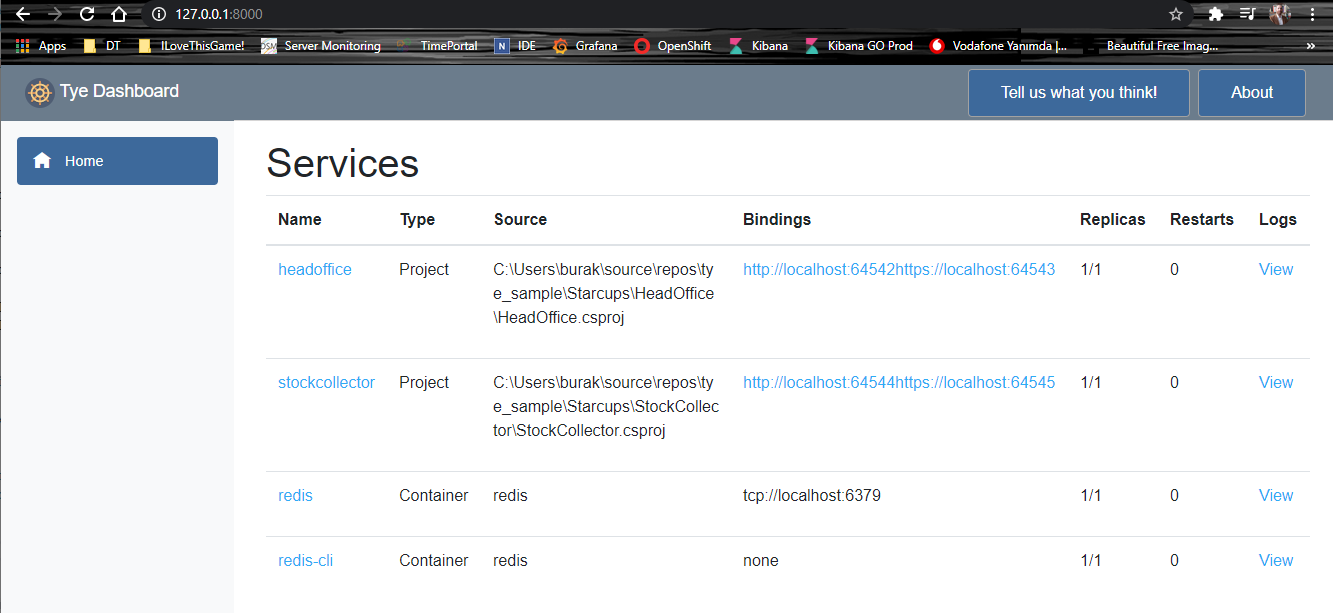
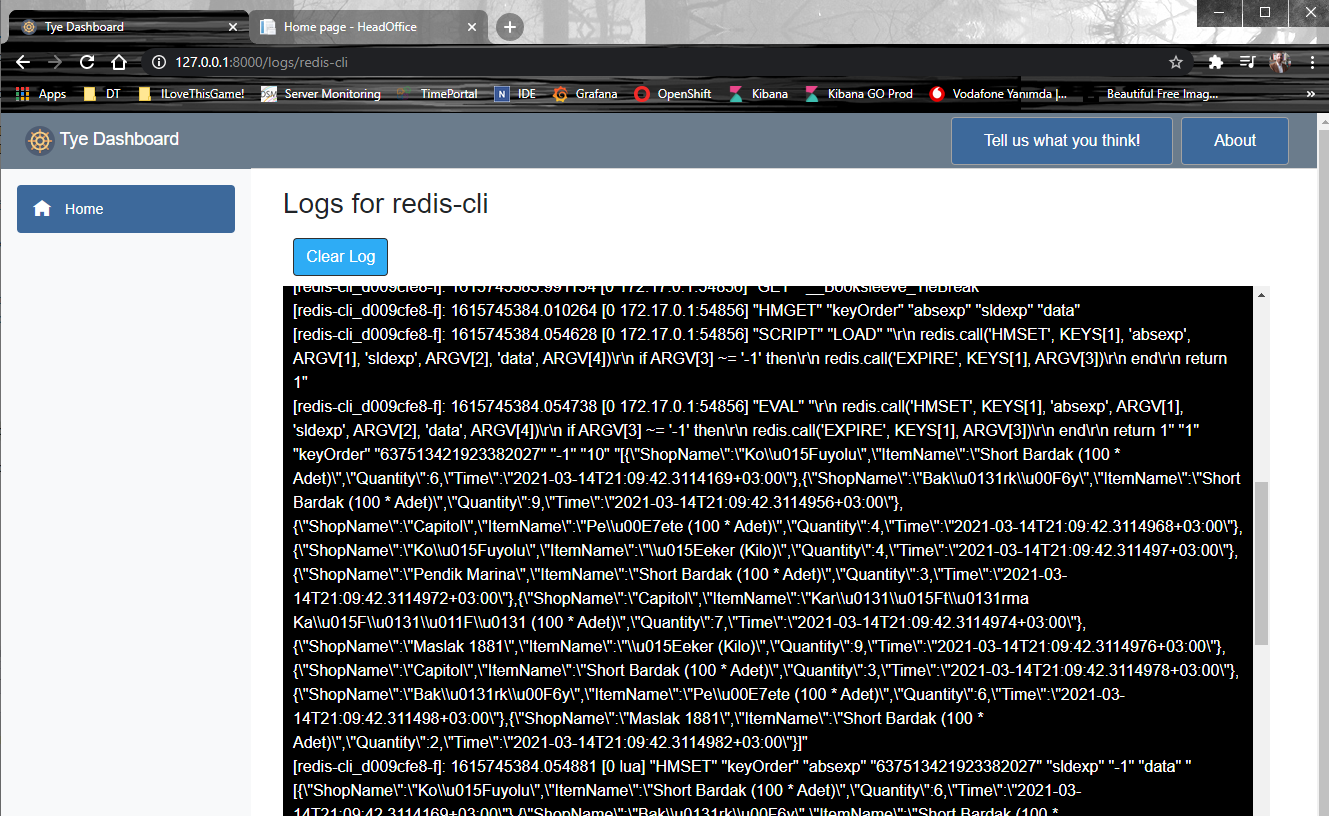
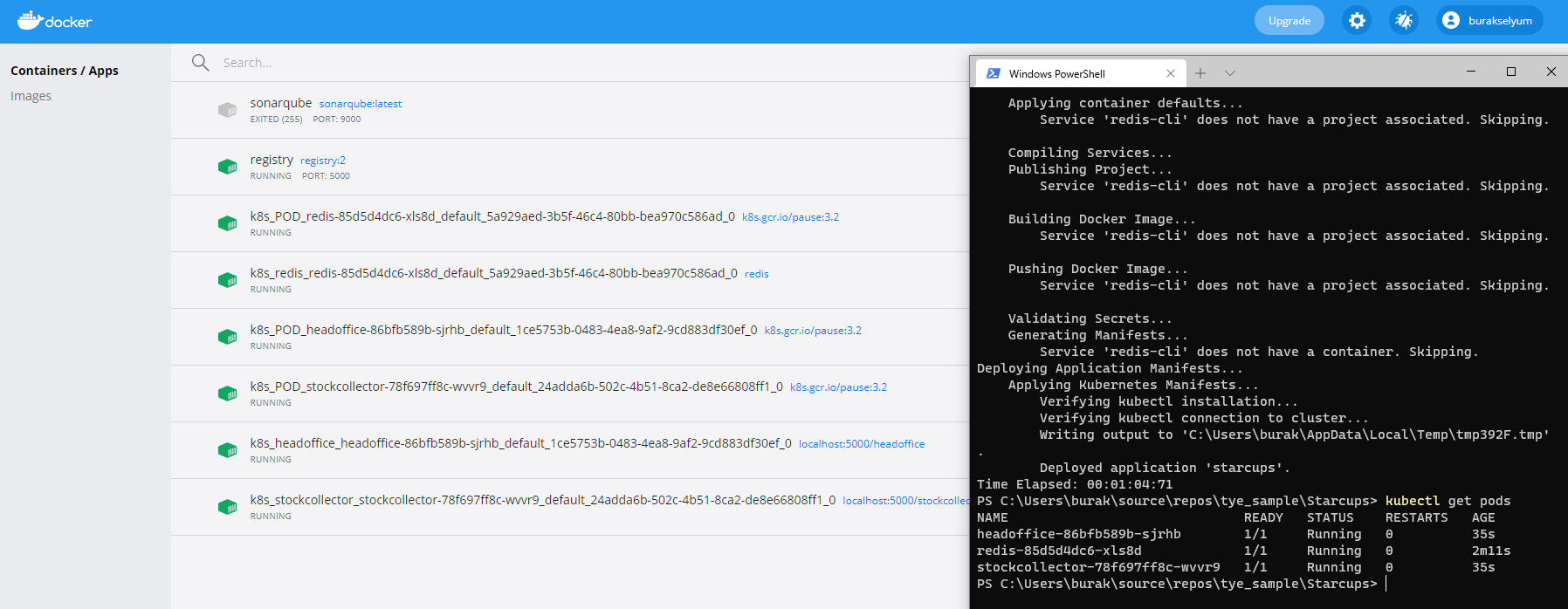
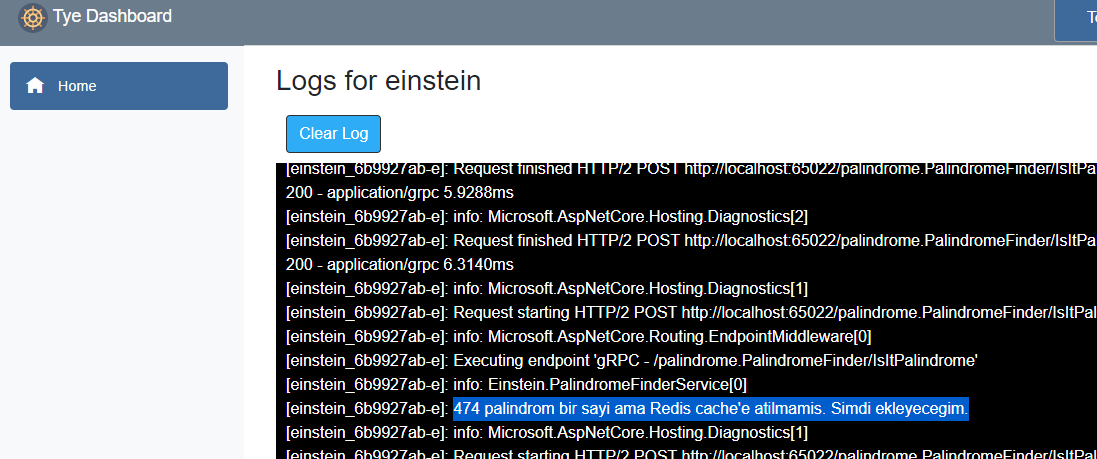
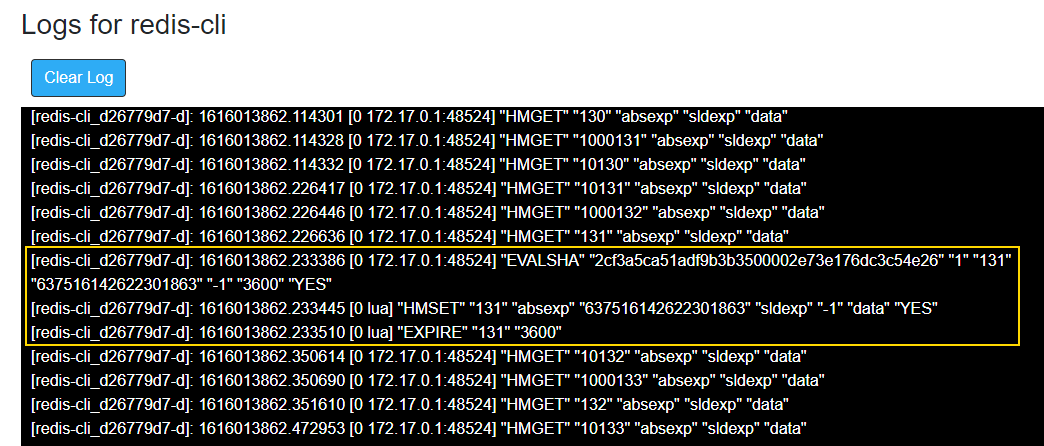
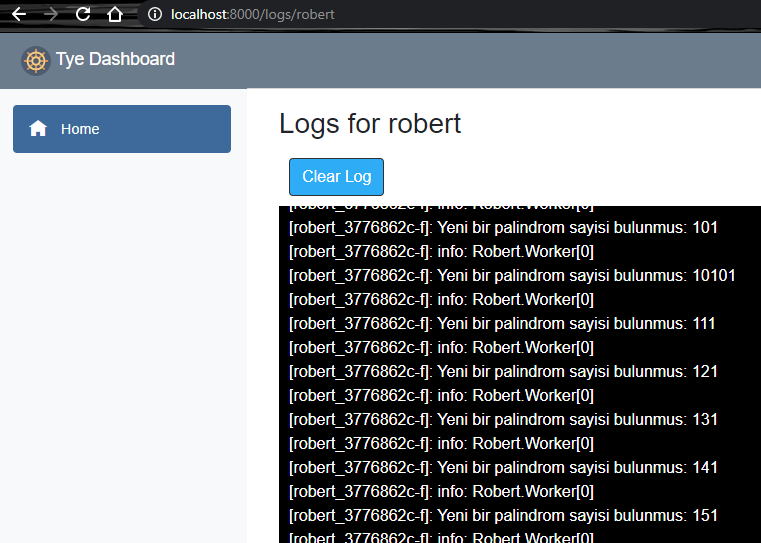
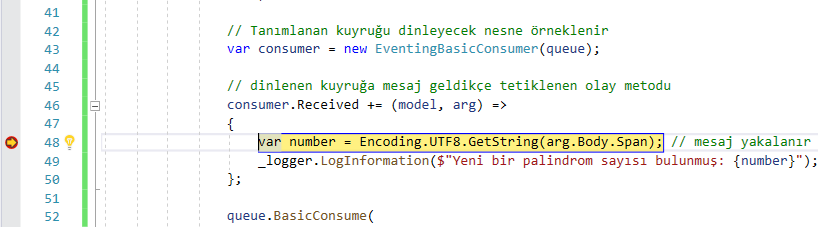
 Yazılım geliştirme işine ciddi anlamda başladığım yeni milenyumun başlarında .Net Framework sahanın yükselen yıldızıydı. Delphi’den kopup gelen Anders’in yarattığı C# programlama dilinin gücü ve .Net Framework çatısının vadettikleri düşünülünce bu son derece doğaldı. Aradan geçen neredeyse 20 yıllık süre zarfında .Net Framework’te evrimleşti ve sürekli güncellendi. Versiyon 2.0 ile gelen generic tipler, 3.0'la birlikte SQL yazar gibi sorgulanabilir nesneler(LINQ-Language INtegrated Query), sonrasında karşımıza çıkan WCF(Windows Communication Foundation), WF(Workflow Foundation), Entity Framework vs derken Microsoft’un açık kaynak dünyasına girişi, benimsediği platform bağımsız stratejiler(Miguel De Icaza’nın Mono’suna da saygı duyalım), Linux, MacOS gibi bir zamanların ciddi rakipleri ile el sıkışarak hamle yapması sonrasında da son birkaç yıllık zaman diliminde karşımıza çıkan .Net Core. Yeni gelişmeler Microsoft’un sıklıkla yaptığı üzere bazı kavram karmaşalarını da beraberinde getirdi elbette. En nihayetinde tek ve birleşik bir .Net 5 ortamından bahsedilmeye başlandı. (Photo by
Yazılım geliştirme işine ciddi anlamda başladığım yeni milenyumun başlarında .Net Framework sahanın yükselen yıldızıydı. Delphi’den kopup gelen Anders’in yarattığı C# programlama dilinin gücü ve .Net Framework çatısının vadettikleri düşünülünce bu son derece doğaldı. Aradan geçen neredeyse 20 yıllık süre zarfında .Net Framework’te evrimleşti ve sürekli güncellendi. Versiyon 2.0 ile gelen generic tipler, 3.0'la birlikte SQL yazar gibi sorgulanabilir nesneler(LINQ-Language INtegrated Query), sonrasında karşımıza çıkan WCF(Windows Communication Foundation), WF(Workflow Foundation), Entity Framework vs derken Microsoft’un açık kaynak dünyasına girişi, benimsediği platform bağımsız stratejiler(Miguel De Icaza’nın Mono’suna da saygı duyalım), Linux, MacOS gibi bir zamanların ciddi rakipleri ile el sıkışarak hamle yapması sonrasında da son birkaç yıllık zaman diliminde karşımıza çıkan .Net Core. Yeni gelişmeler Microsoft’un sıklıkla yaptığı üzere bazı kavram karmaşalarını da beraberinde getirdi elbette. En nihayetinde tek ve birleşik bir .Net 5 ortamından bahsedilmeye başlandı. (Photo by 

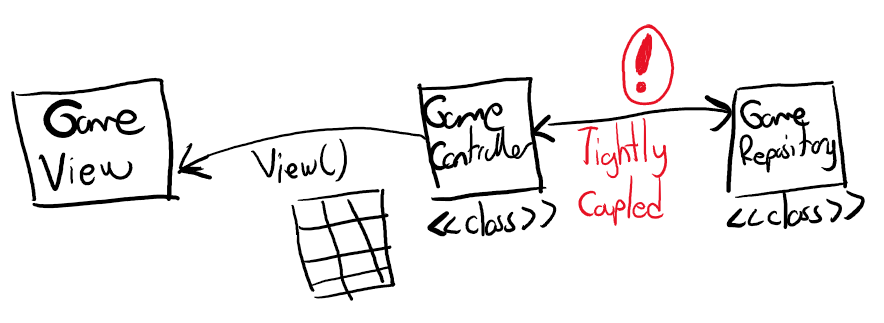
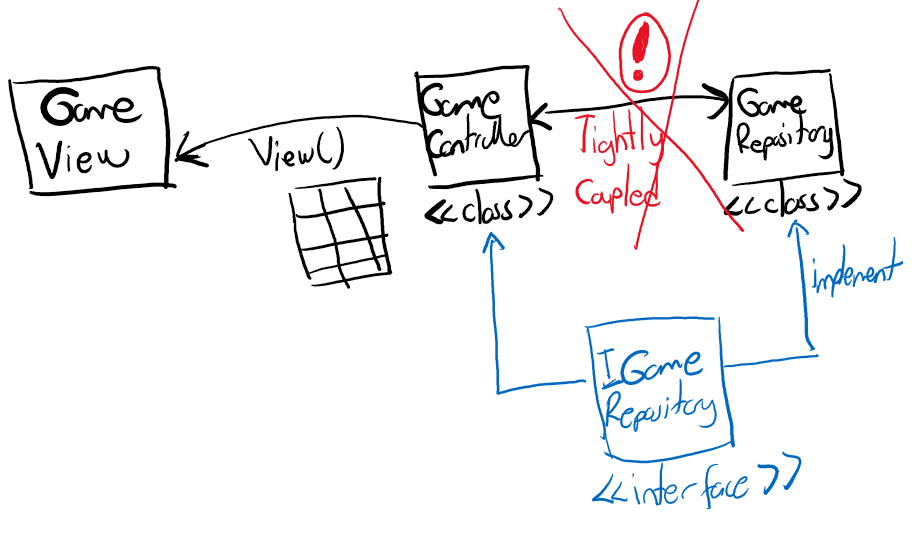
 Ayakta durmuş odanın camından dışarıyı izlerken yazıya nasıl bir giriş yapsam diye düşünüyordum. Baharın etkisi ile yapraklarını açmış meşenin yavaş yavaş gölgelediği caddeden İtalyan bayrağı kasklı bir motosikletli geçti aniden. Sadece birkaç metre gerisinden de onu neredeyse aynı süratle takip eden martıya binmiş bir genç. Kaldırımda bir elinde alışveriş poşeti ötekinde onu yola doğru çekiştiren haylazla birlikte yürümeye çalışan orta yaşlarında bir kadın. Hemen binanın önündeki basket sahasında da yaşları beş ile on beş arasında değişen on çocuk. Futbol oynuyorlar. Bağrışlar, çağrışlar. Çekişmeli de gidiyor ama herkesin yüzünde bir maske. Eve kapanmak zorunda kalmadan önce çocukların son bir bahar ziyafetini izliyorum diye iç geçiriyorum.
Ayakta durmuş odanın camından dışarıyı izlerken yazıya nasıl bir giriş yapsam diye düşünüyordum. Baharın etkisi ile yapraklarını açmış meşenin yavaş yavaş gölgelediği caddeden İtalyan bayrağı kasklı bir motosikletli geçti aniden. Sadece birkaç metre gerisinden de onu neredeyse aynı süratle takip eden martıya binmiş bir genç. Kaldırımda bir elinde alışveriş poşeti ötekinde onu yola doğru çekiştiren haylazla birlikte yürümeye çalışan orta yaşlarında bir kadın. Hemen binanın önündeki basket sahasında da yaşları beş ile on beş arasında değişen on çocuk. Futbol oynuyorlar. Bağrışlar, çağrışlar. Çekişmeli de gidiyor ama herkesin yüzünde bir maske. Eve kapanmak zorunda kalmadan önce çocukların son bir bahar ziyafetini izliyorum diye iç geçiriyorum.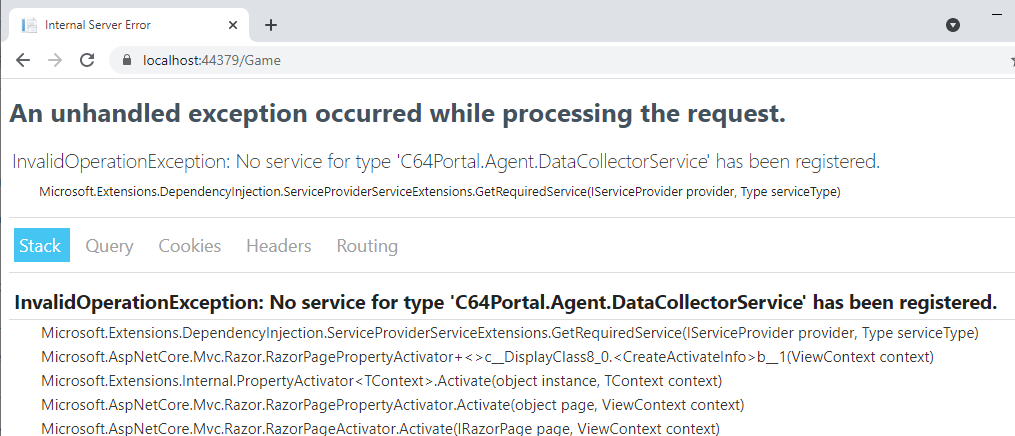
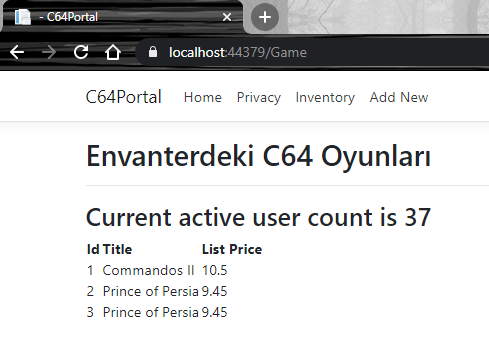
 Çalışmakta olduğum şirketin çok büyük bir ERP(Enterprise Resource Planning) uygulaması var. Microsoft .Net Framework 1.0 sürümünde düşünce olarak hayat geçirilip geliştirilmeye başlanmış. Milyonlarca satır koddan ve sayısız sınıftan oluşan, katmanlı monolitik mimari üstünde yürüyen, sahada on binden fazla personelin kullandığı çok etkili bir ürün. Geçtiğimiz yıl bu uygulamanın modernizasyonu kapsamında başlatılan IT4IT çalışmaları bünyesinde nesne bağımlılıklarının yönetimi için Dependency Injection mekanizmasının nimetlerinden de epeyce yararlanıldı. Doğruyu söylemek gerekirse koda yaptıkları dokunuşları hayranlıkla izledim.
Çalışmakta olduğum şirketin çok büyük bir ERP(Enterprise Resource Planning) uygulaması var. Microsoft .Net Framework 1.0 sürümünde düşünce olarak hayat geçirilip geliştirilmeye başlanmış. Milyonlarca satır koddan ve sayısız sınıftan oluşan, katmanlı monolitik mimari üstünde yürüyen, sahada on binden fazla personelin kullandığı çok etkili bir ürün. Geçtiğimiz yıl bu uygulamanın modernizasyonu kapsamında başlatılan IT4IT çalışmaları bünyesinde nesne bağımlılıklarının yönetimi için Dependency Injection mekanizmasının nimetlerinden de epeyce yararlanıldı. Doğruyu söylemek gerekirse koda yaptıkları dokunuşları hayranlıkla izledim.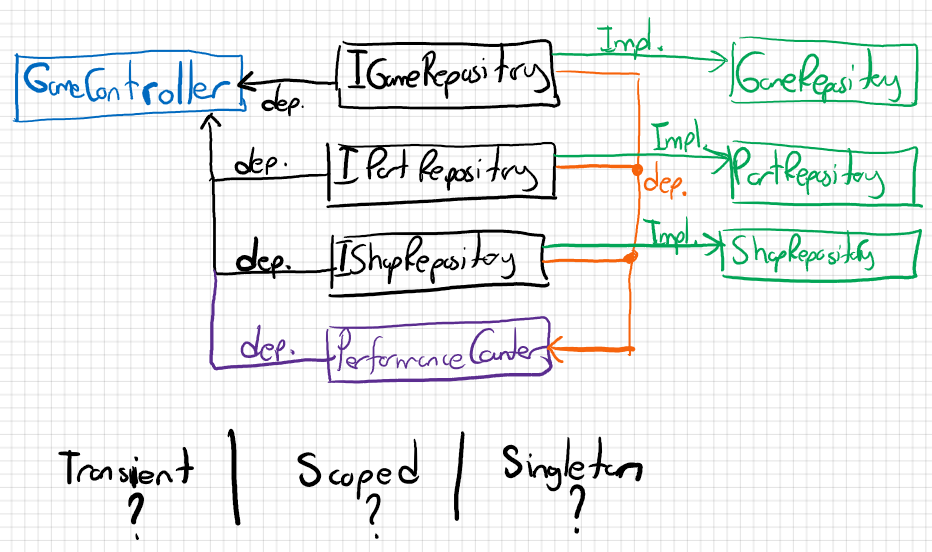
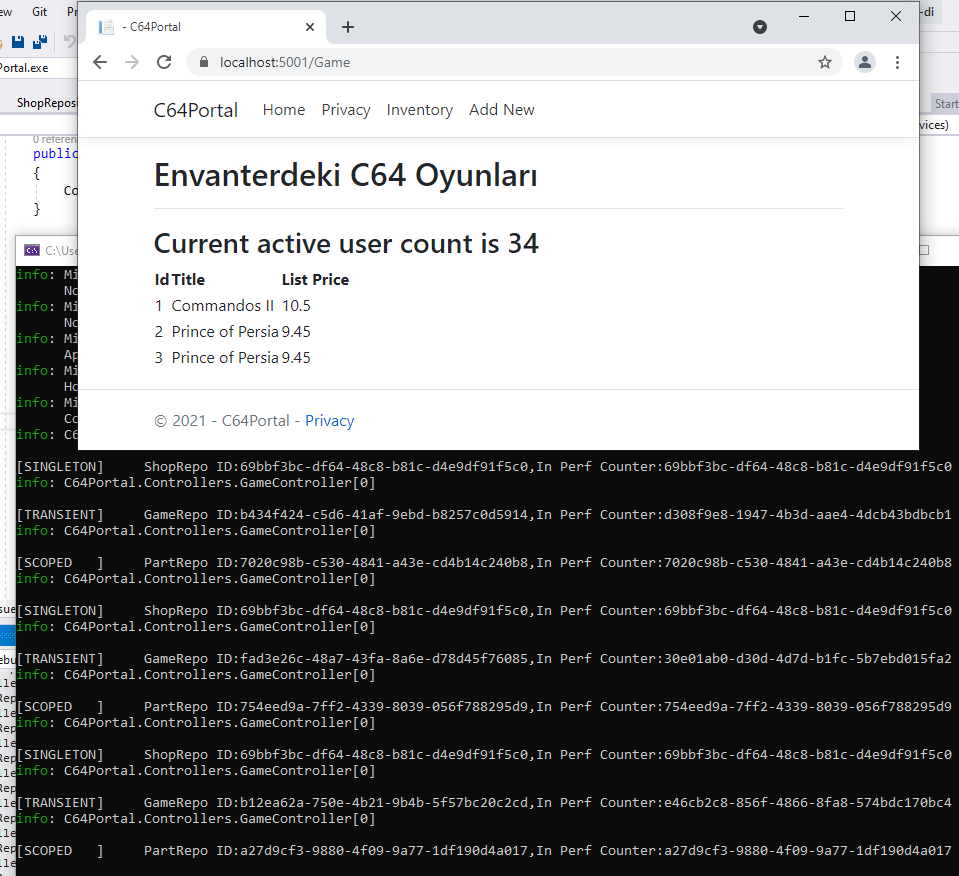
 Kendime geldiğimde hiçbir şey göremediğimi fark ettim. Üstüme çöken zifiri karanlığa rağmen halen daha hayatta olduğuma dair tek şey yağmur damlalarının birkaç metre üstümde olduğunu sandığım metal tavana vurarak çıkardıkları seslerdi. Ensemden neredeyse ayak parmaklarıma kadar yayılan ağrı hiçbir şeyi umursamaz bir tavırda yattığım yerden doğrulmamı güçleştiriyordu. Son hatırladığım CloudTown'dan birkaç sibernetik coder ile karşılaştığım belli belirsiz yansımalardan ibaretti. Kısa süre sonra yakınlarımda koşuşturan bazı ayak sesleri işittim. Yer yer duraksıyor yer yer su birikintilerine girip çıkıyorlardı. Fısıltılar daha duyulur sesler haline gelmeye başladı. Tavandaki kapağı açmak üzere içlerinden birinin elindeki anahtarları hazırladığını işittim. Sonrası gözlerim için çok korkunç bir deneyimdi. Bu zifiri karanlıkta ne kadar kaldığımı bilmiyorum ama gözlerim dışardan gelen o parlak ışığa karşı adeta haykırıyordu. Üstüme boca edilen bir kova soğuk suyun ardından gelen kaba ses ise çok tanıdıkdı. Ve şöyle seslendim; "Reyzor! Sen haaa" :P
Kendime geldiğimde hiçbir şey göremediğimi fark ettim. Üstüme çöken zifiri karanlığa rağmen halen daha hayatta olduğuma dair tek şey yağmur damlalarının birkaç metre üstümde olduğunu sandığım metal tavana vurarak çıkardıkları seslerdi. Ensemden neredeyse ayak parmaklarıma kadar yayılan ağrı hiçbir şeyi umursamaz bir tavırda yattığım yerden doğrulmamı güçleştiriyordu. Son hatırladığım CloudTown'dan birkaç sibernetik coder ile karşılaştığım belli belirsiz yansımalardan ibaretti. Kısa süre sonra yakınlarımda koşuşturan bazı ayak sesleri işittim. Yer yer duraksıyor yer yer su birikintilerine girip çıkıyorlardı. Fısıltılar daha duyulur sesler haline gelmeye başladı. Tavandaki kapağı açmak üzere içlerinden birinin elindeki anahtarları hazırladığını işittim. Sonrası gözlerim için çok korkunç bir deneyimdi. Bu zifiri karanlıkta ne kadar kaldığımı bilmiyorum ama gözlerim dışardan gelen o parlak ışığa karşı adeta haykırıyordu. Üstüme boca edilen bir kova soğuk suyun ardından gelen kaba ses ise çok tanıdıkdı. Ve şöyle seslendim; "Reyzor! Sen haaa" :P
 Yeni bir on yılın arifesini çoktan geçtik ve bu on yıla girmeden önce Microsoft, milenyumun başında da yaptığı üzere önemli ürünlerin altına imzasını attı. Açık kaynak dünyasına hızlı bir girişten sonra yıllardır süregelen Mono projesi daha da anlam kazandı. Artık Silverlight, Windows Phone, Web Forms, .Net Remoting gibi kavramlardan neredeyse hiç söz etmiyoruz. Üstelik bazıları yıllar önce rafa kalktı. Rafa kalkanların, eskiyenlerin bıraktığı tecrübe yeni nesil ürünlerin başarısını artırdı. Unity ile platform bağımsız oyunlar, Xamarin ile macOS ve linux ayırt etmeksizin çalışan kodlar vs derken .Net Core hayatımıza girerek büyük sükse yaptı.
Yeni bir on yılın arifesini çoktan geçtik ve bu on yıla girmeden önce Microsoft, milenyumun başında da yaptığı üzere önemli ürünlerin altına imzasını attı. Açık kaynak dünyasına hızlı bir girişten sonra yıllardır süregelen Mono projesi daha da anlam kazandı. Artık Silverlight, Windows Phone, Web Forms, .Net Remoting gibi kavramlardan neredeyse hiç söz etmiyoruz. Üstelik bazıları yıllar önce rafa kalktı. Rafa kalkanların, eskiyenlerin bıraktığı tecrübe yeni nesil ürünlerin başarısını artırdı. Unity ile platform bağımsız oyunlar, Xamarin ile macOS ve linux ayırt etmeksizin çalışan kodlar vs derken .Net Core hayatımıza girerek büyük sükse yaptı.
 Altunizade’nin bahar aylarında insanı epey dinlendiren yeşil yapraklı ağaçları ile çevrelenmiş cadde
Altunizade’nin bahar aylarında insanı epey dinlendiren yeşil yapraklı ağaçları ile çevrelenmiş cadde
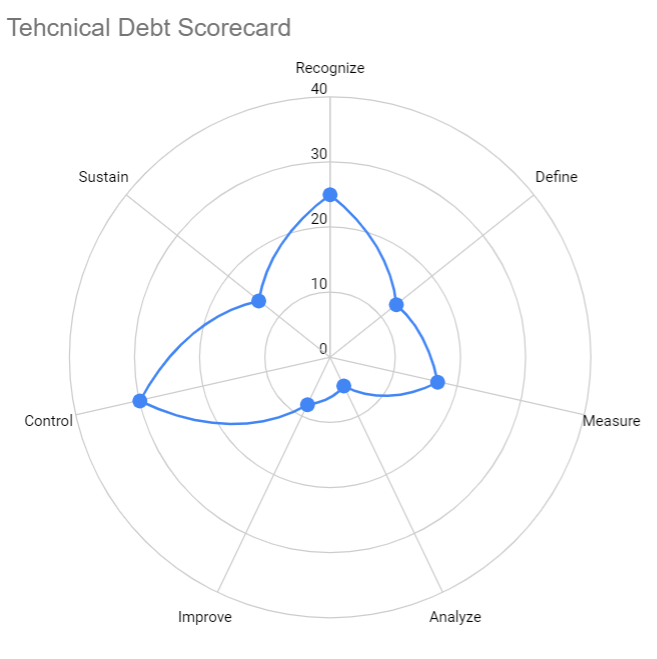
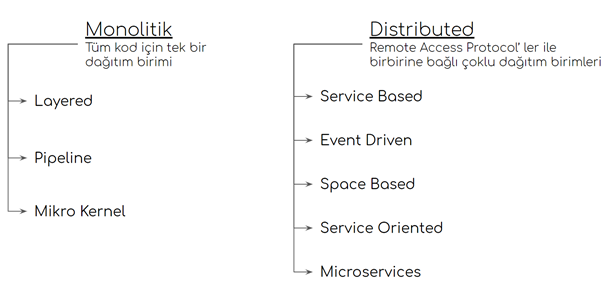
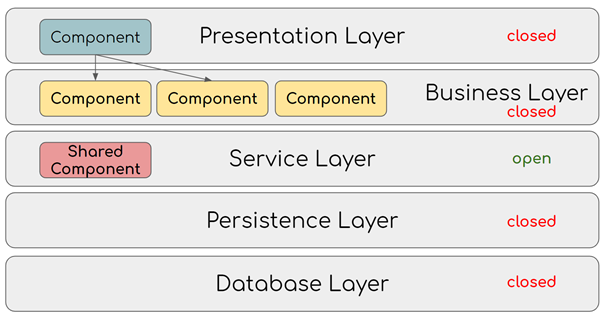
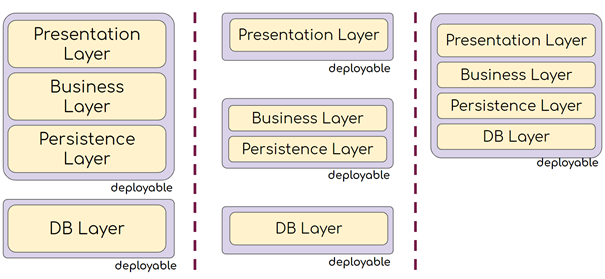
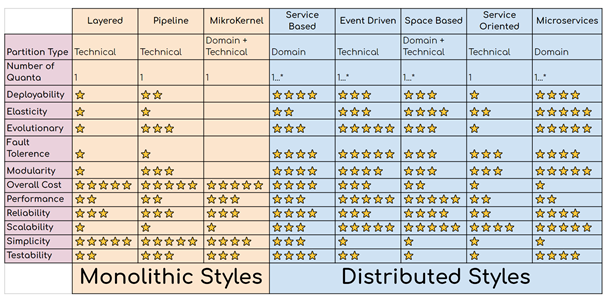

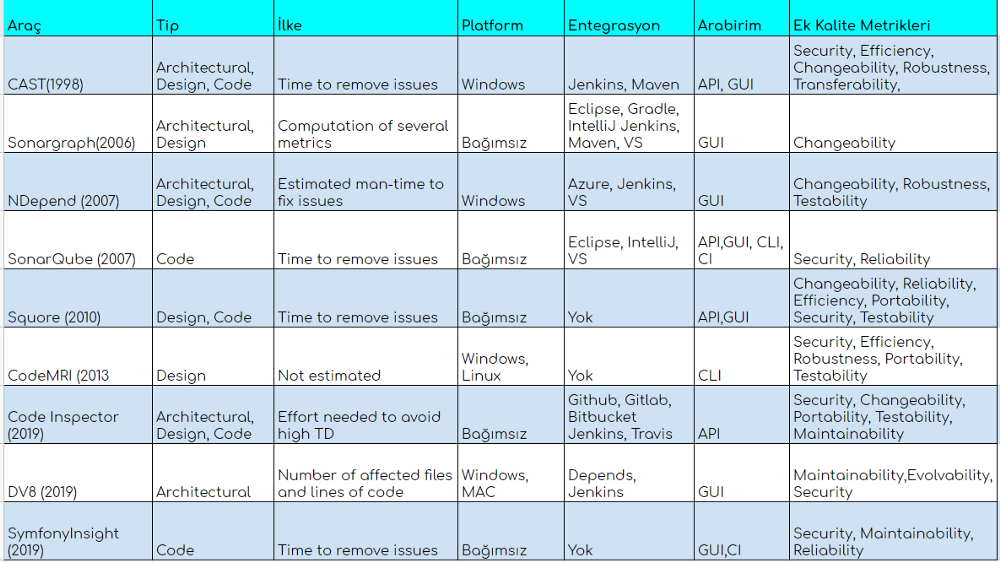
 İki yıl kadar önce bir merakla başladığım ama sonrasında takıntı haline gelen bir uğraş edindim; Rust programlama dili. Profesyonel iş yaşantımın neredeyse tamamında .Net platformu üstünde geliştirme yaptım ve halen daha maaşımı ondan kazanıyorum. Bazı zamanlar Python, Go, Ruby gibi dillere de baktım ama hep hobi olarak kaldılar. Rust içinse aynı şeyi söylemem zor. Onunla ilgili resmi dokümantasyonu takip edip birkaç satır kod yazmaya başladım ve derken sayısız derleme zamanı hatası ile karşılaştım. Bunların neredeyse büyük çoğunluğu borrowing, ownership, lifetimes gibi konularla ilintiliydi ve her biri Rust’ın temelde bilinmesi gereken demirbaşları.
İki yıl kadar önce bir merakla başladığım ama sonrasında takıntı haline gelen bir uğraş edindim; Rust programlama dili. Profesyonel iş yaşantımın neredeyse tamamında .Net platformu üstünde geliştirme yaptım ve halen daha maaşımı ondan kazanıyorum. Bazı zamanlar Python, Go, Ruby gibi dillere de baktım ama hep hobi olarak kaldılar. Rust içinse aynı şeyi söylemem zor. Onunla ilgili resmi dokümantasyonu takip edip birkaç satır kod yazmaya başladım ve derken sayısız derleme zamanı hatası ile karşılaştım. Bunların neredeyse büyük çoğunluğu borrowing, ownership, lifetimes gibi konularla ilintiliydi ve her biri Rust’ın temelde bilinmesi gereken demirbaşları.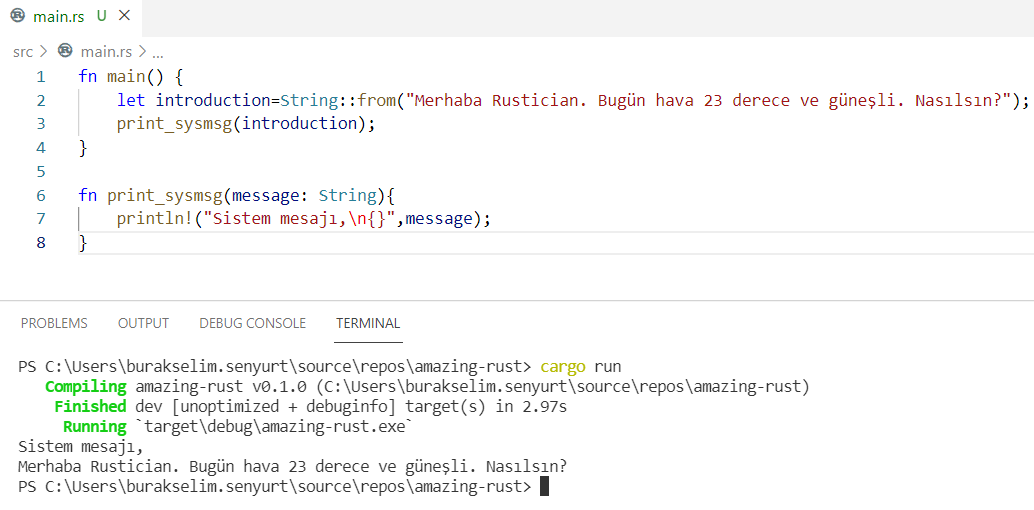
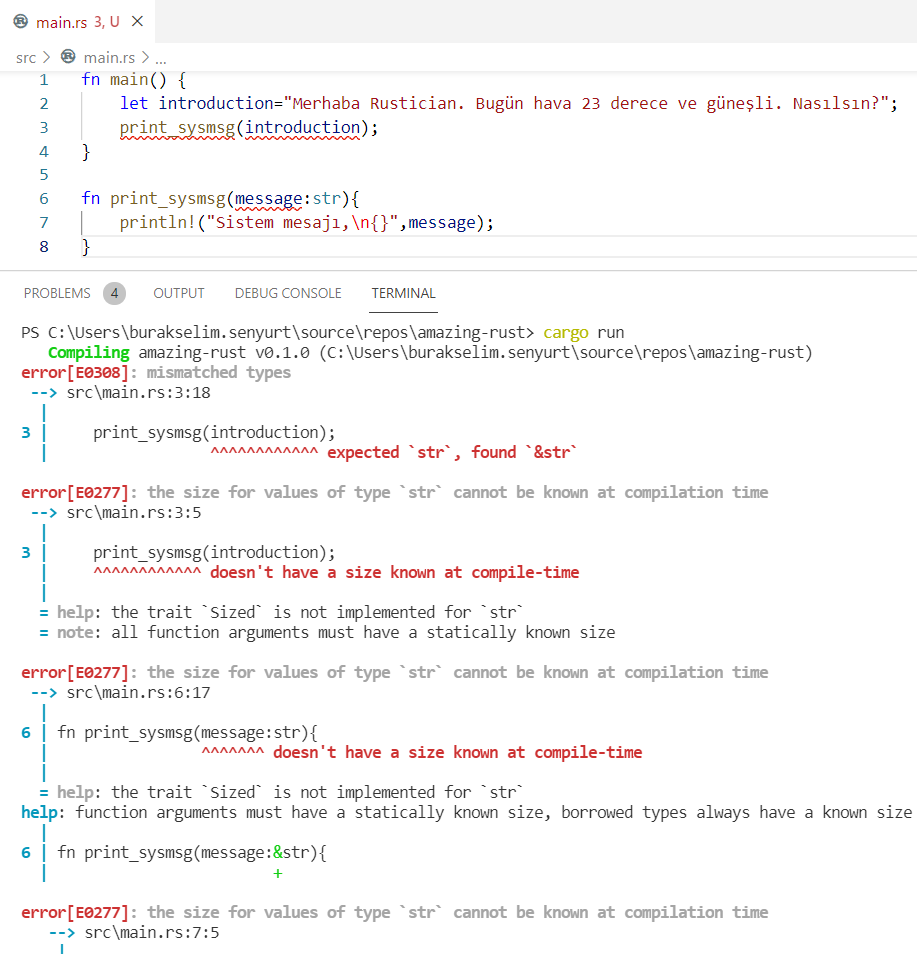
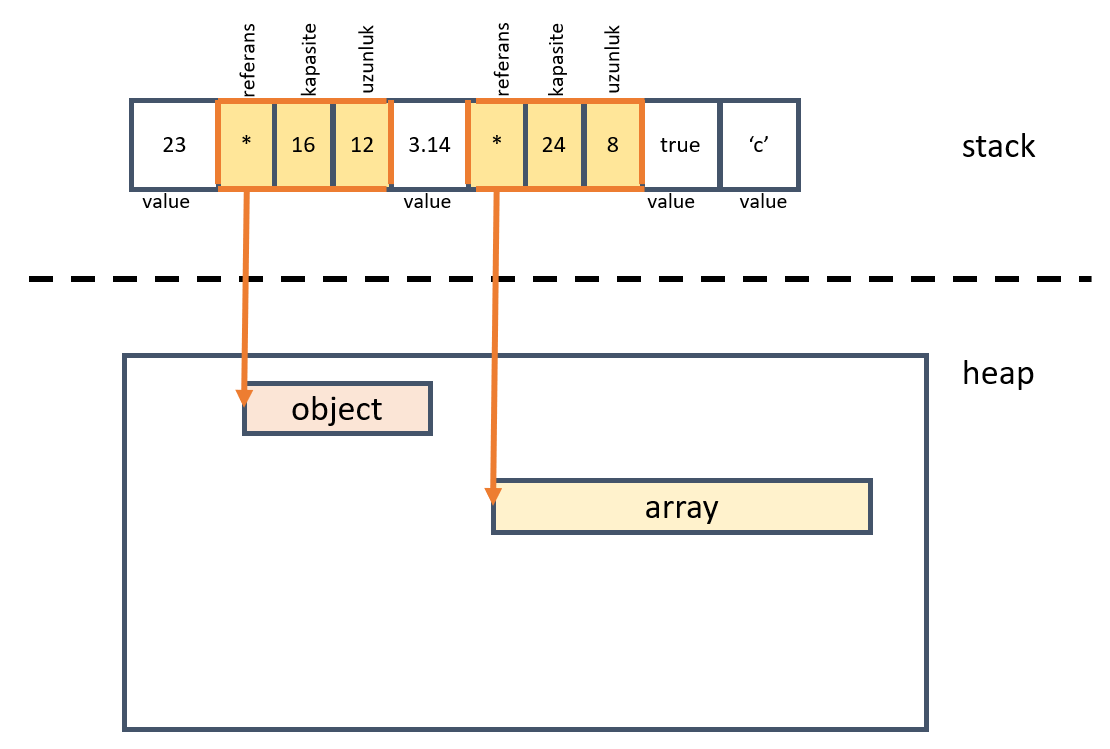
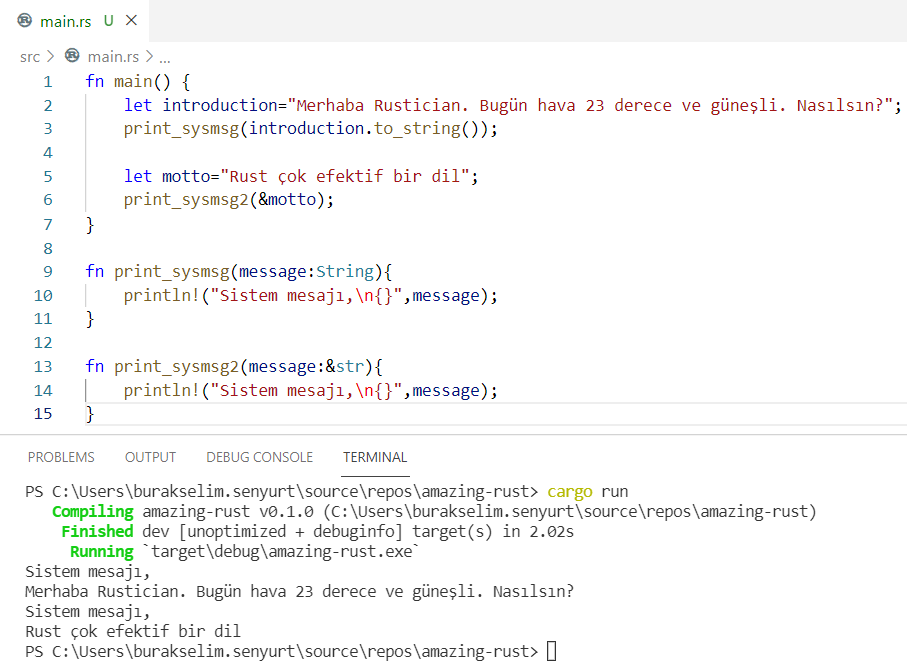
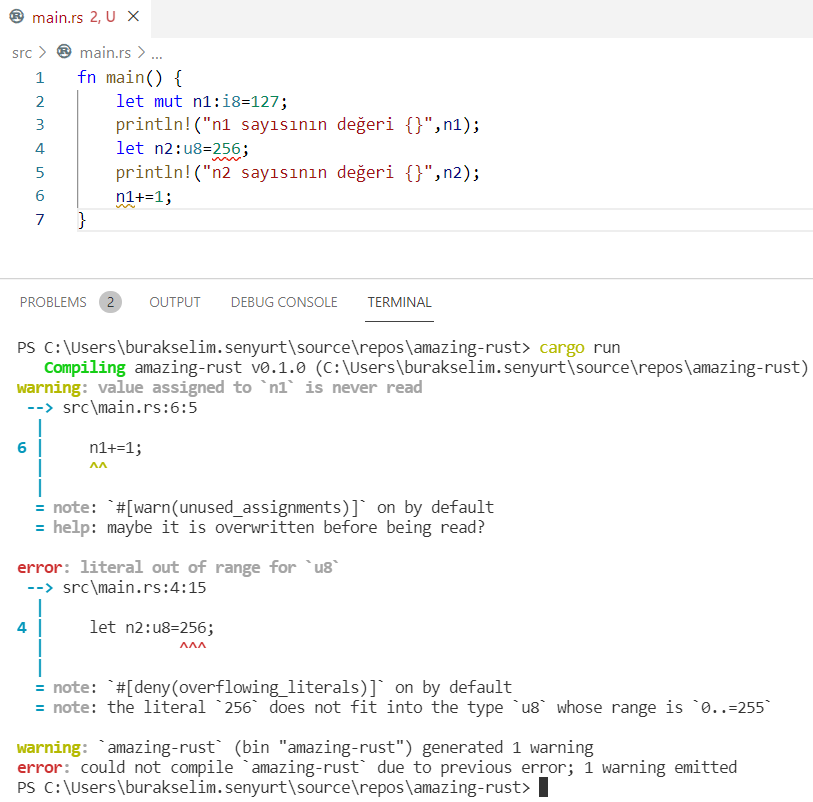
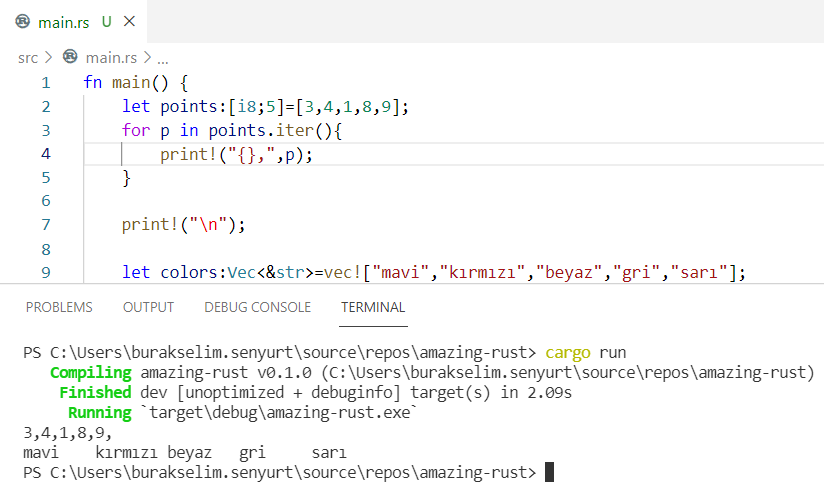

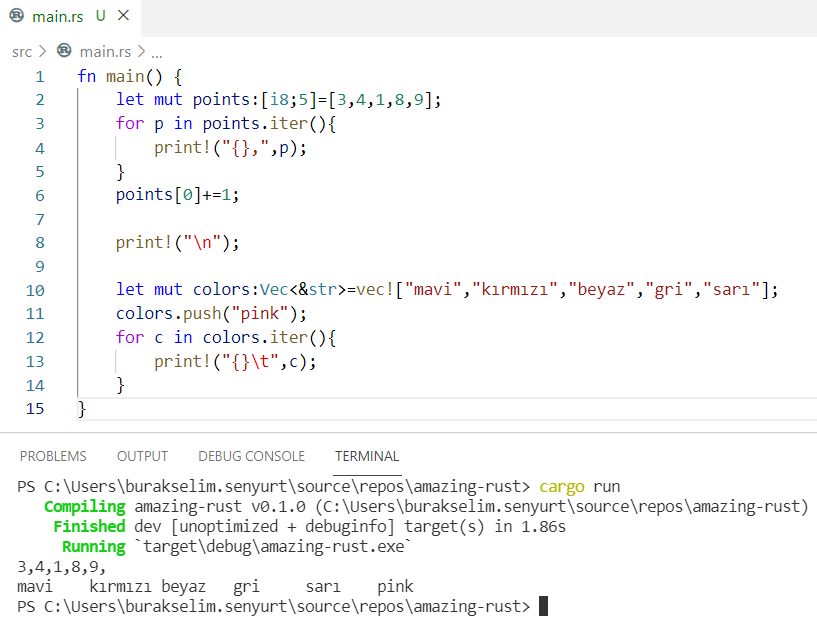
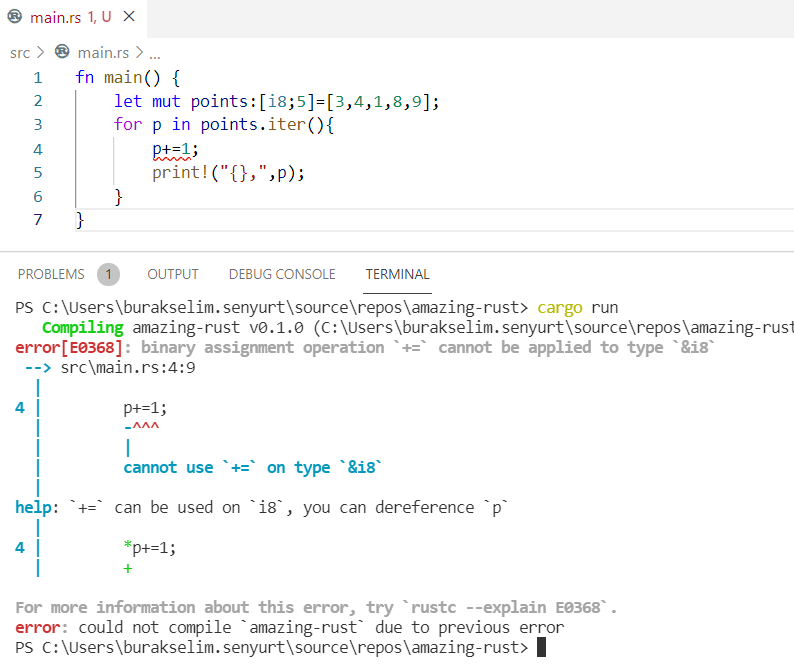
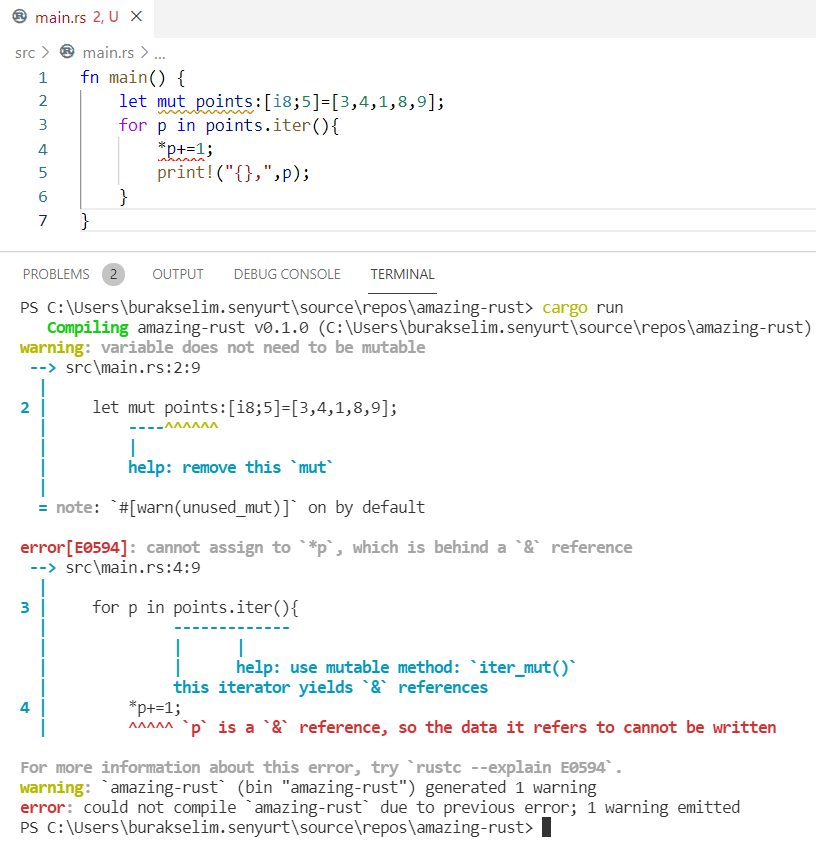
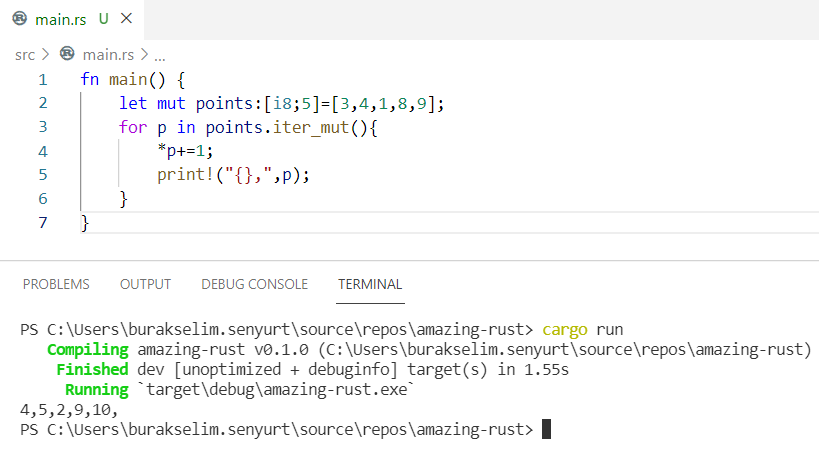
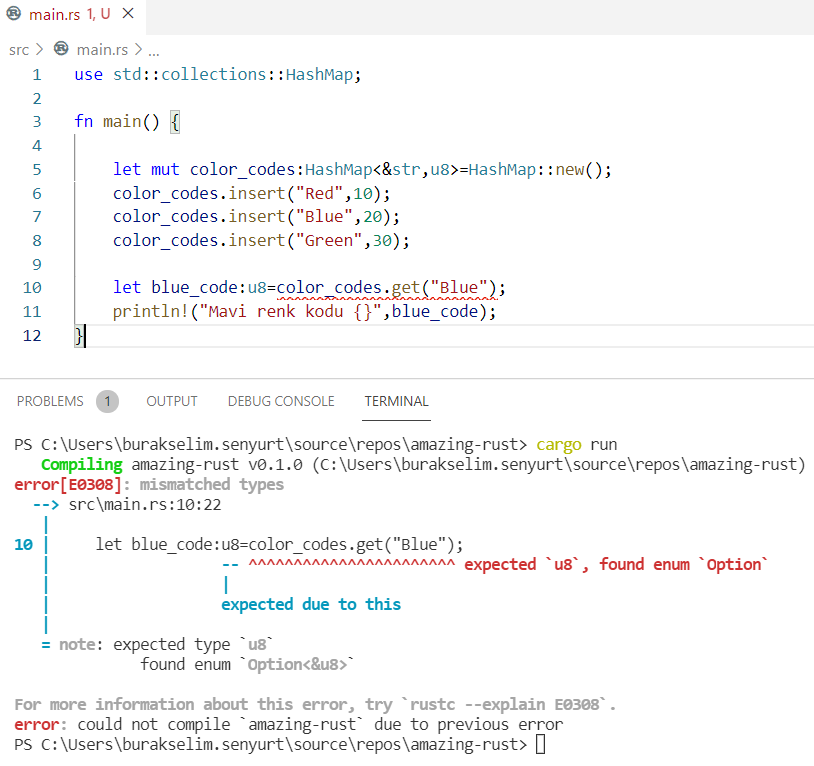
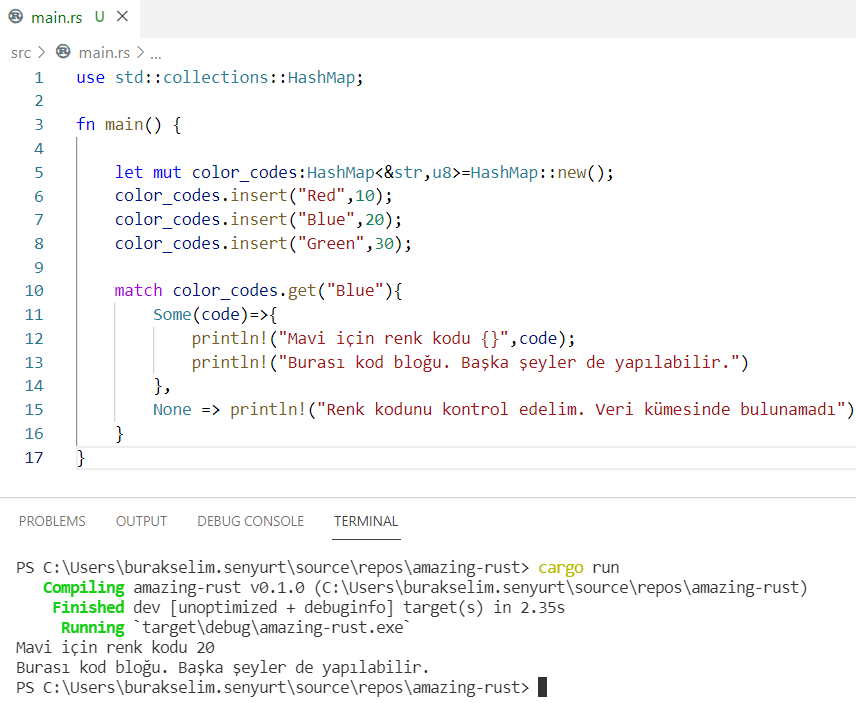
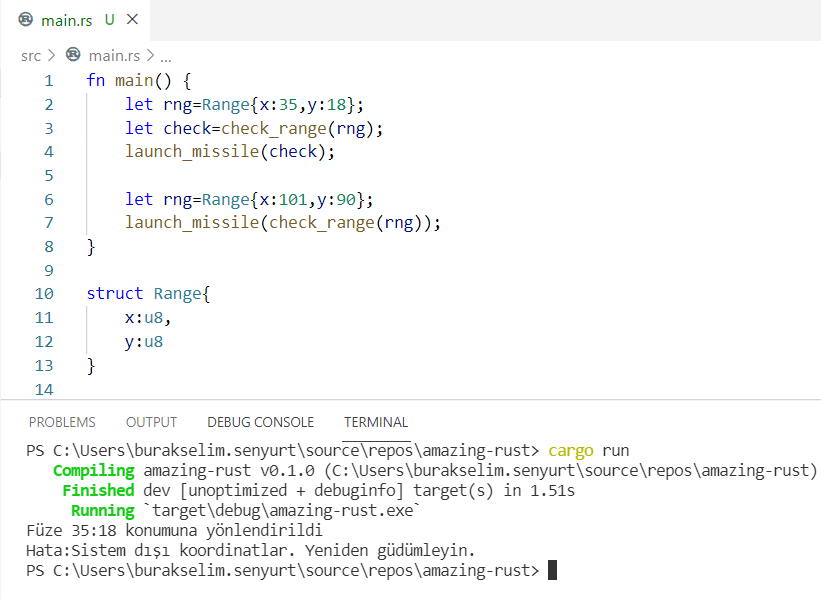
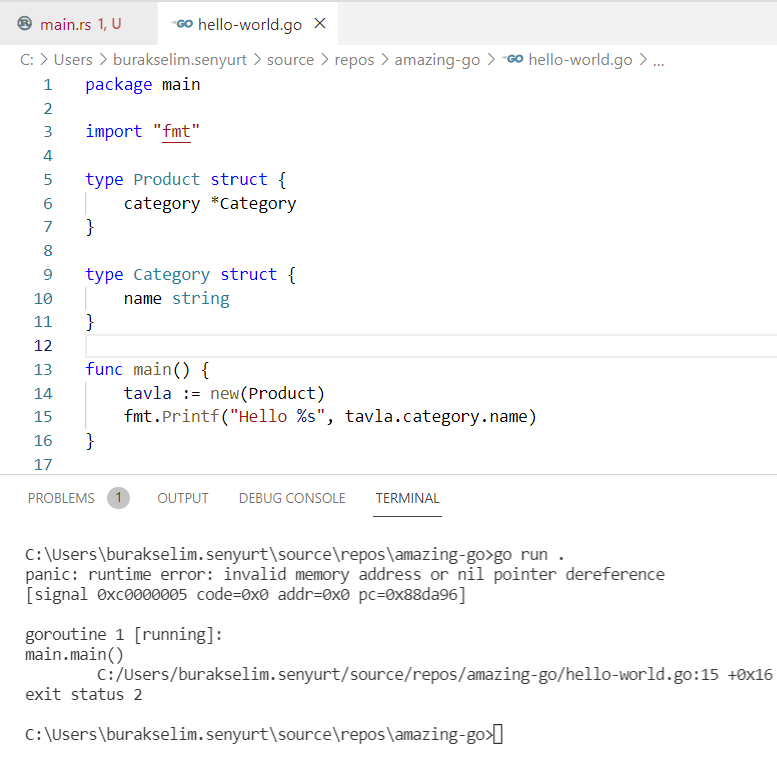
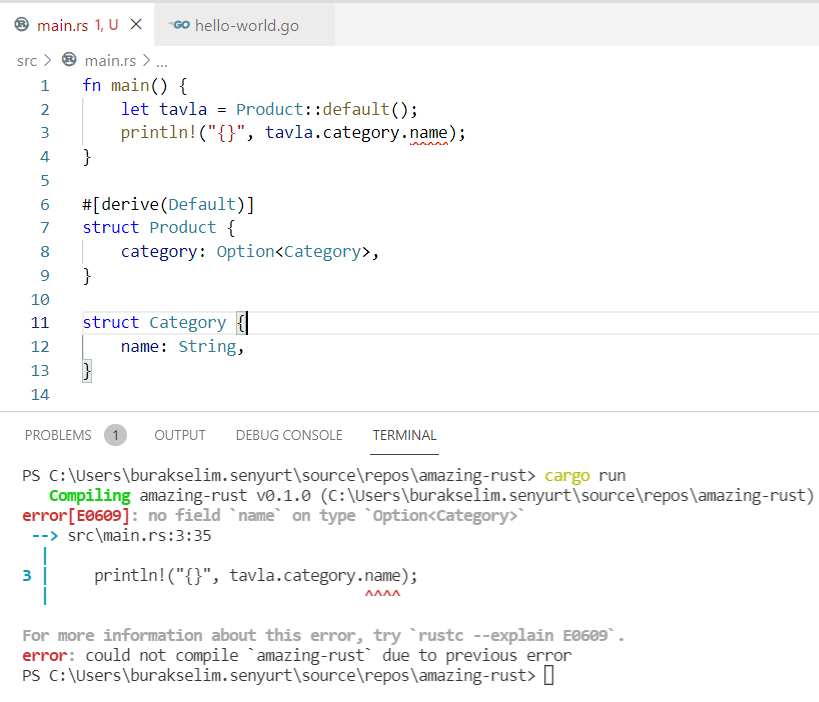
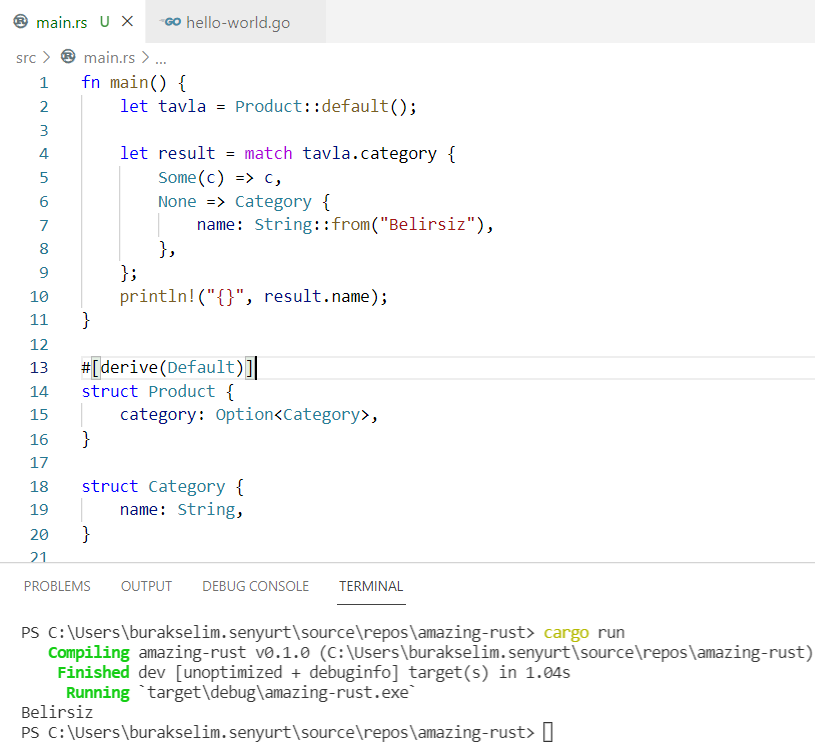
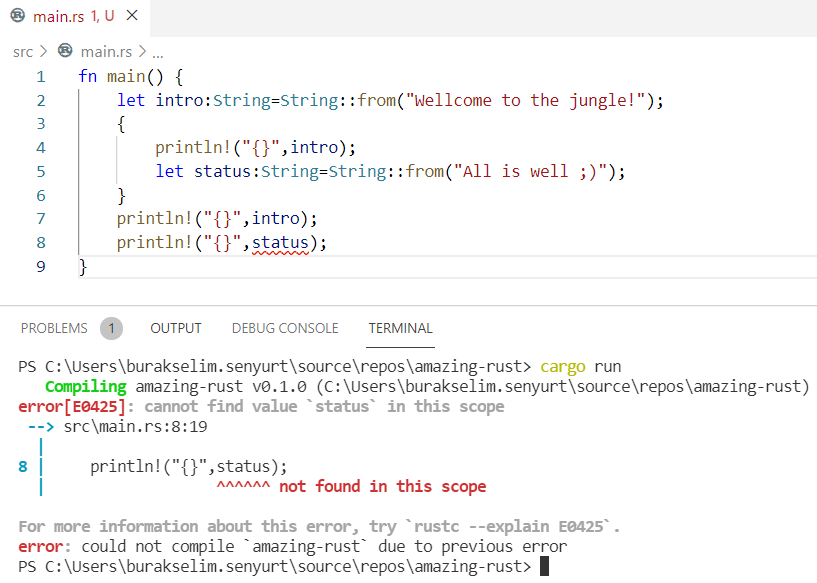
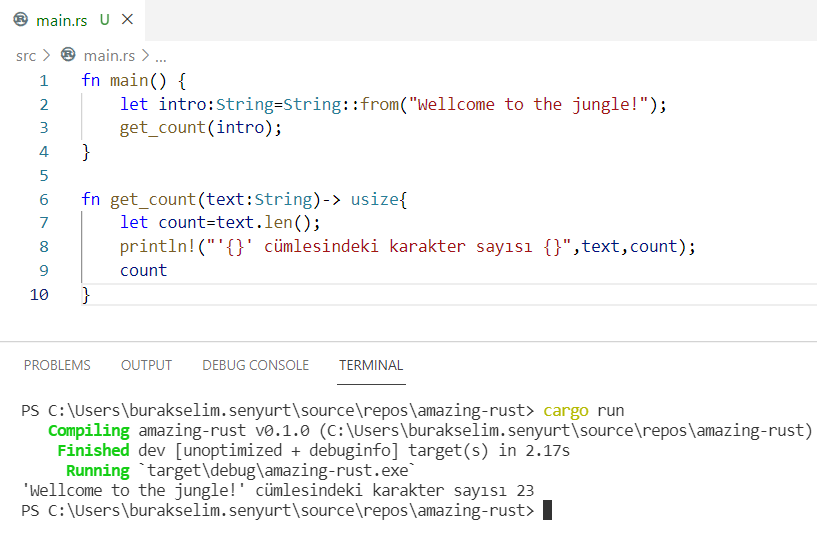
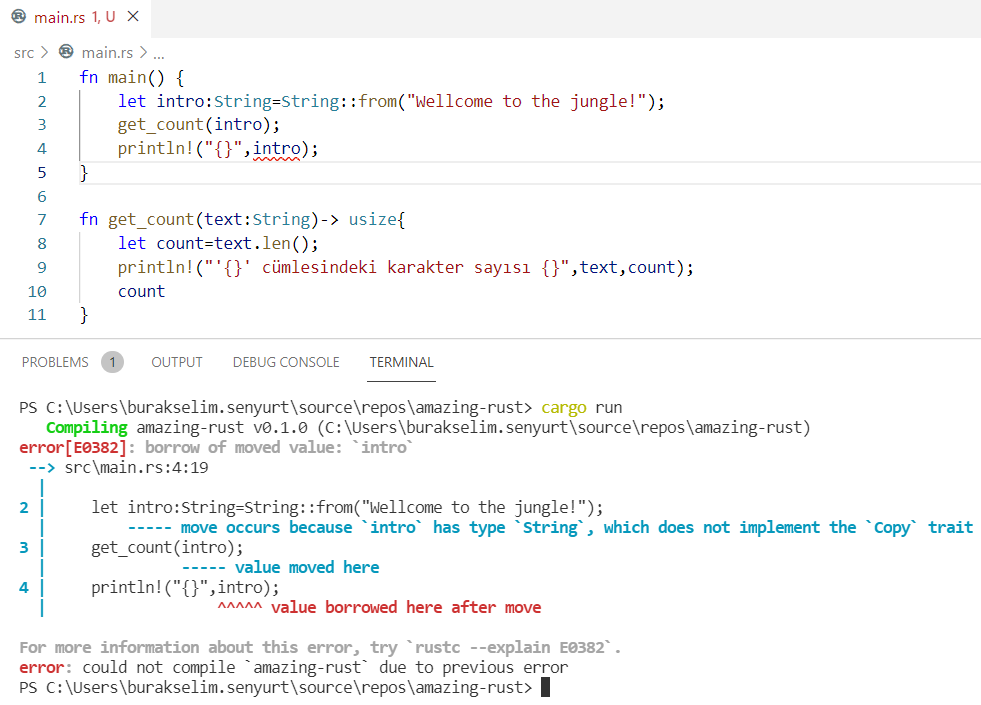
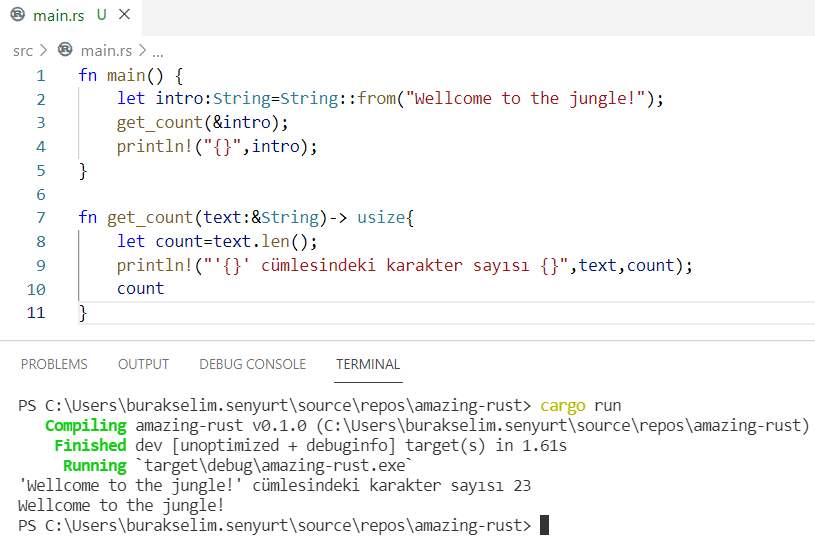
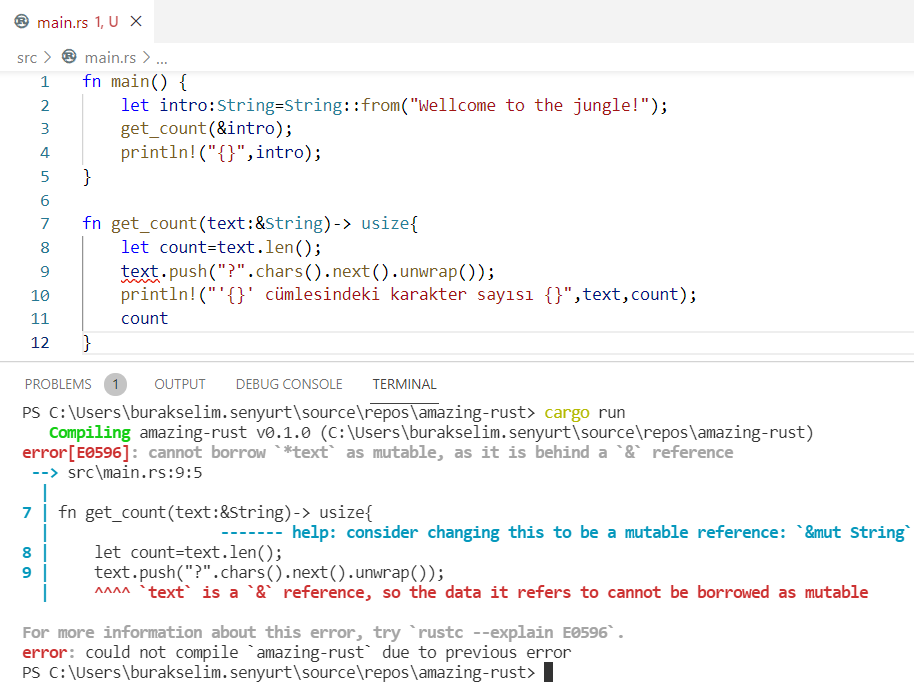
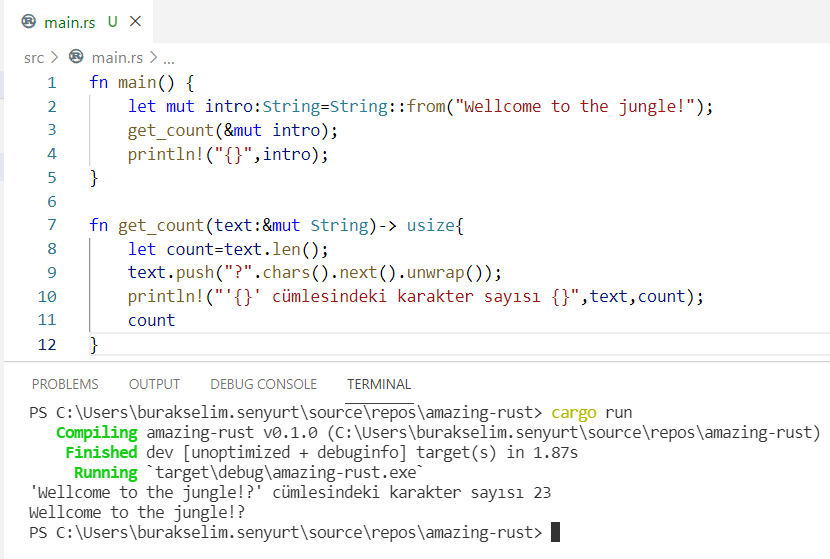
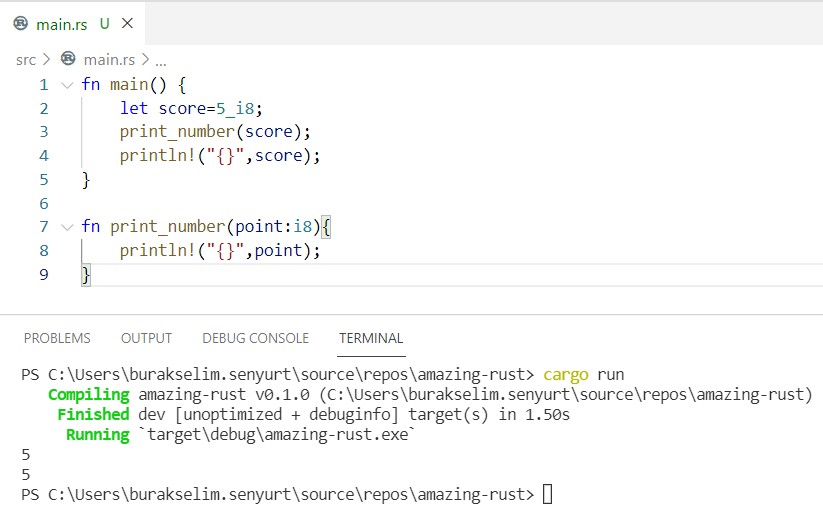
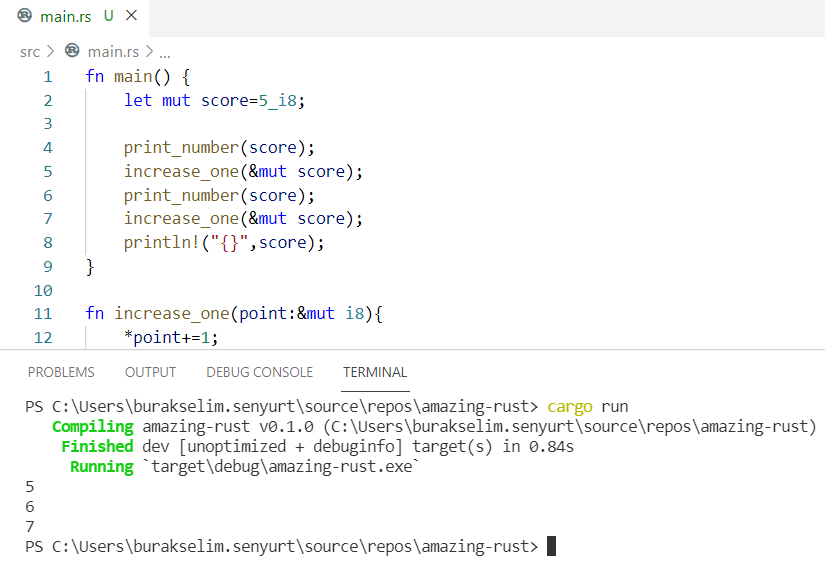
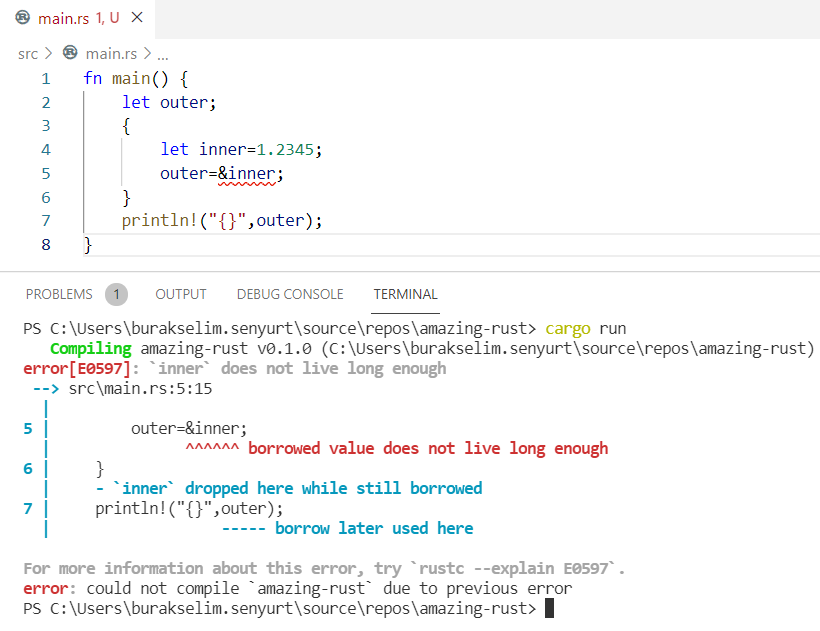
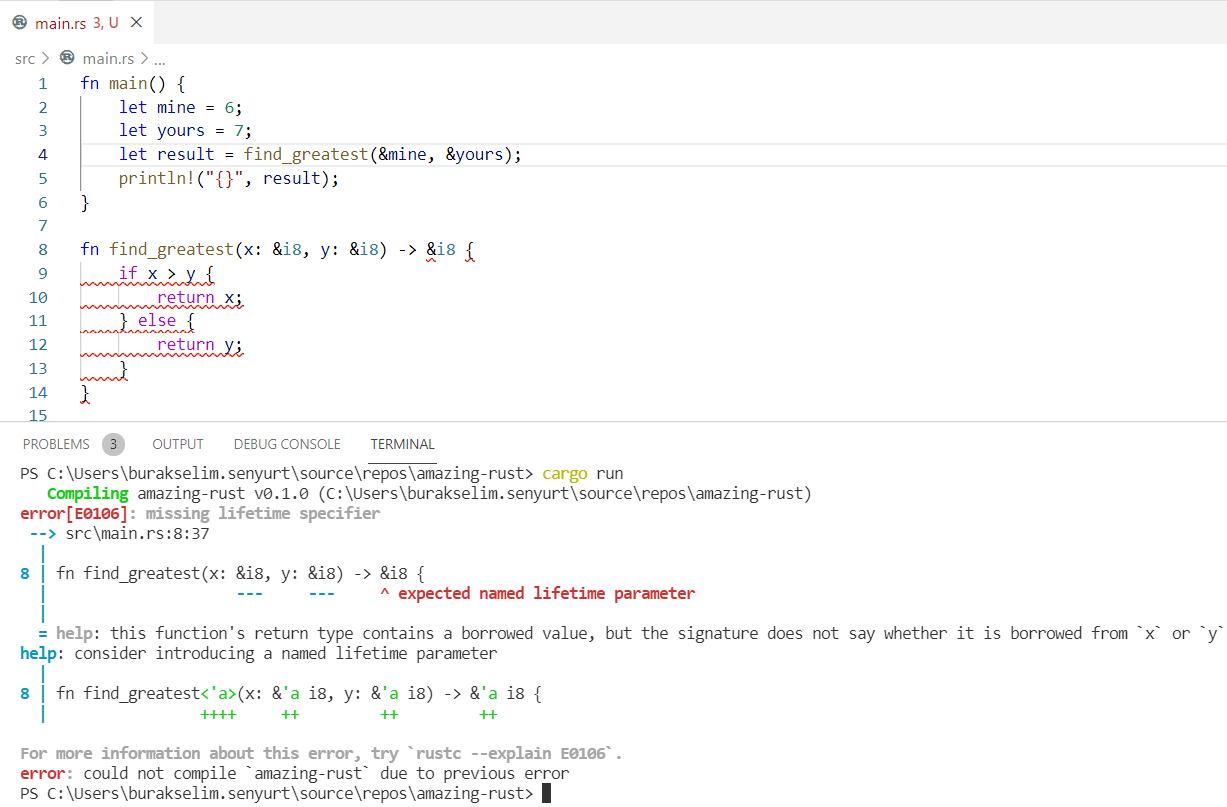
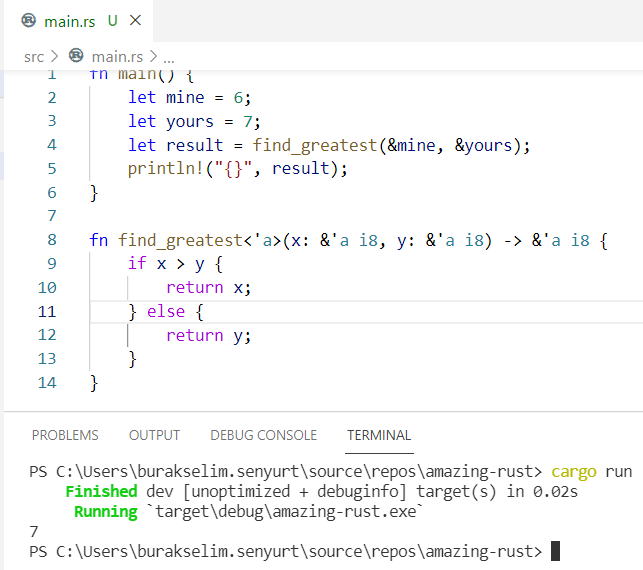
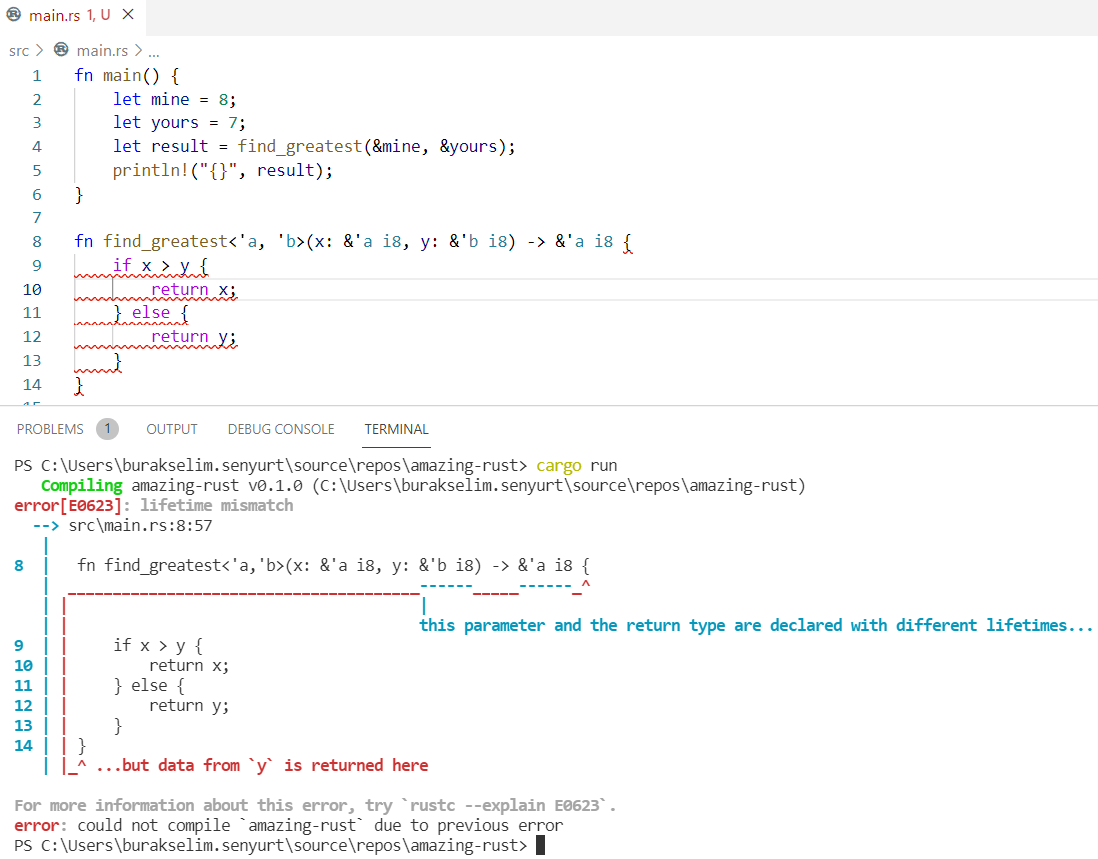
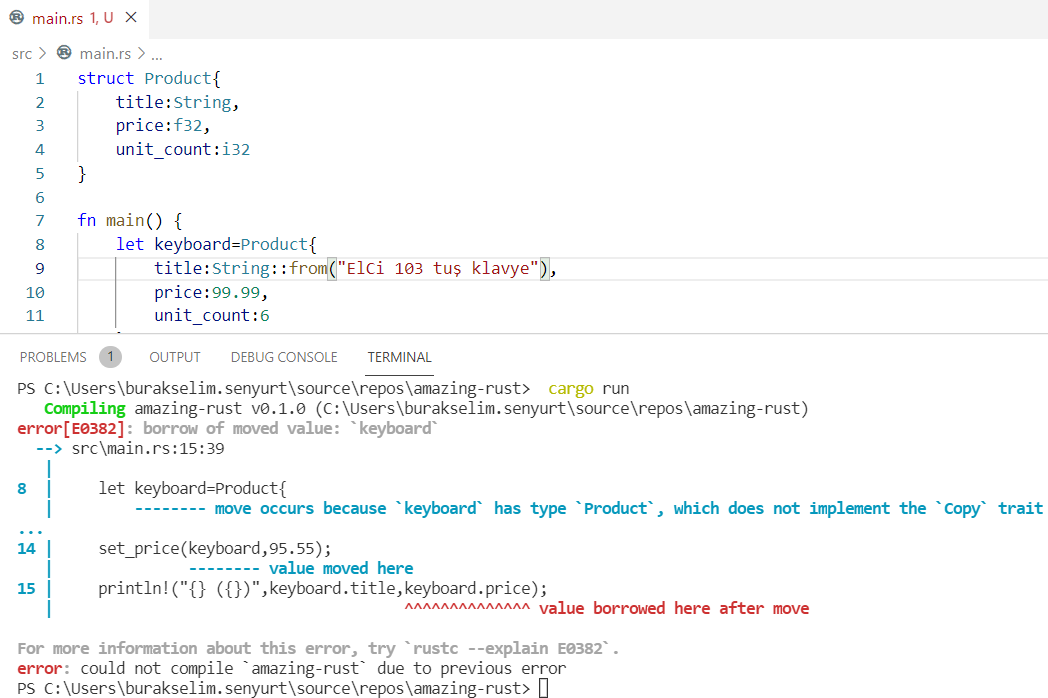
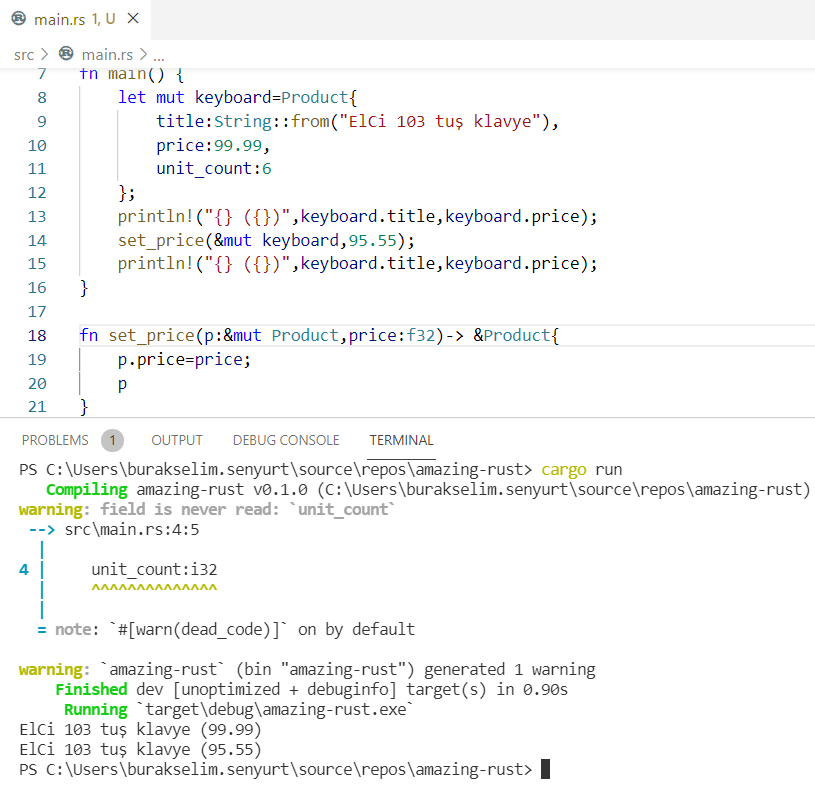
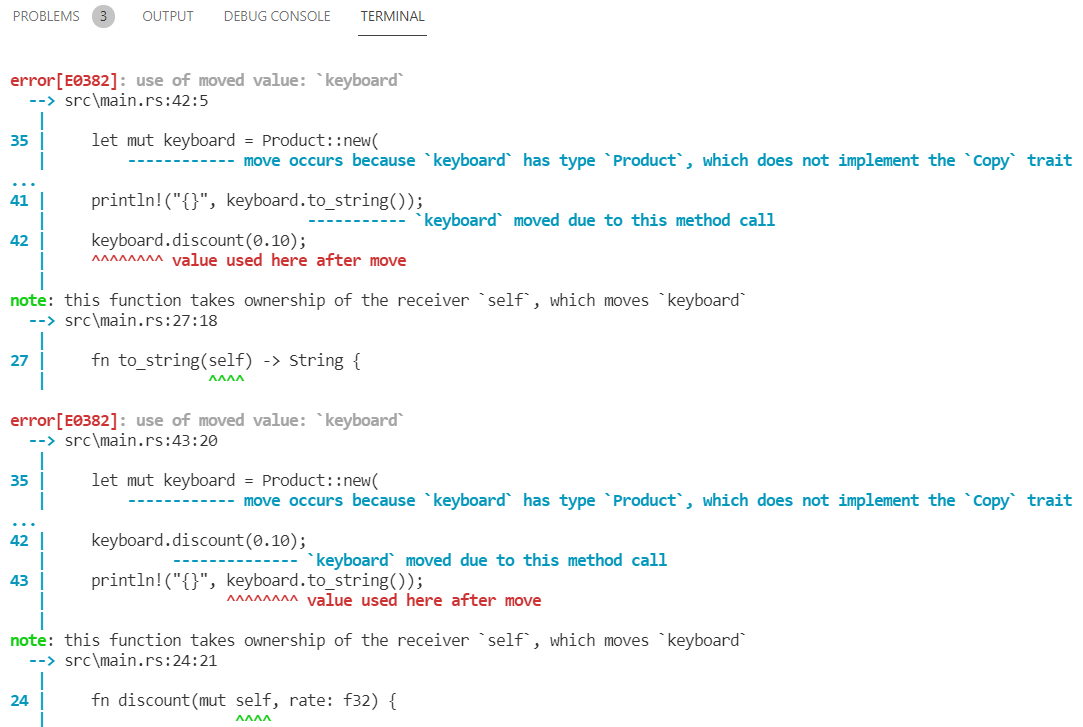
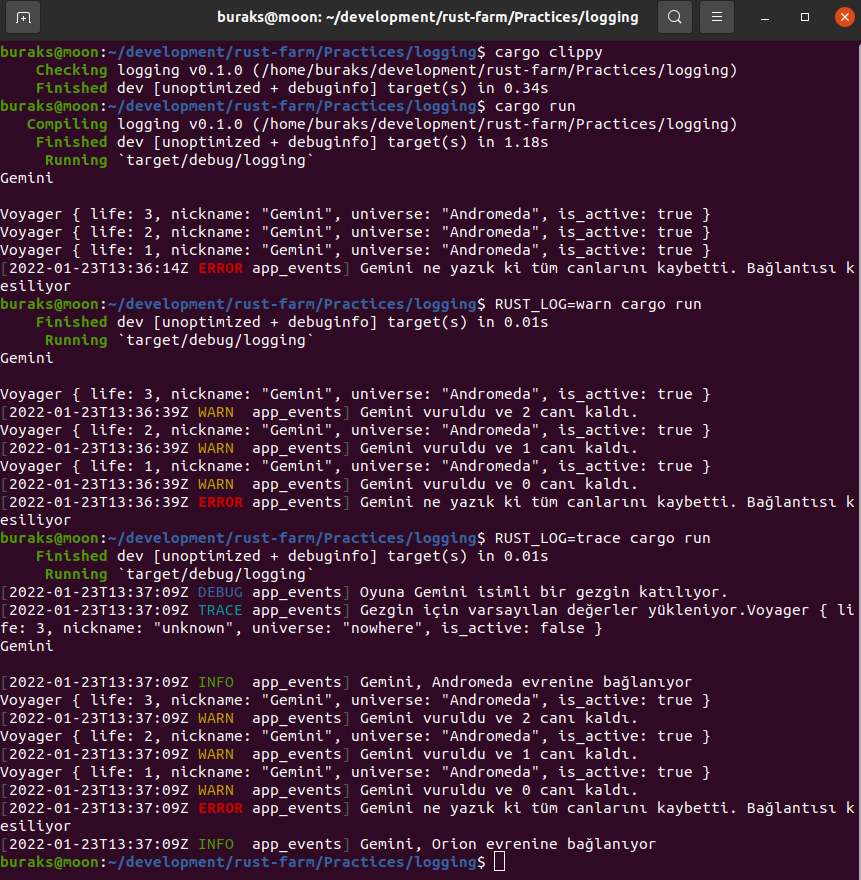
 Uygulamalar işletim sistemlerince Process olarak ayağa kaldırılırlar. Bir process içerisindeki işleri birbirlerinden bağımsız olarak yapan thread'ler de söz konusu olabilir. Çoğu zaman çalıştırılabilir programın main fonksiyonu ile akan akış tek bir thread ile işleyişini sürdürür ama ihtiyaç dahillinde yeni thread'ler açmak gerekir. Rust için process içerisinde bir thread açmak oldukça kolaydır ve bellek tüketimi açısından maliyeti düşüktür. Ownership ve borrowing kuralları sayesinde bellek sahası güvende kalır ve özellikle data-race sorunları oluşmaz.
Uygulamalar işletim sistemlerince Process olarak ayağa kaldırılırlar. Bir process içerisindeki işleri birbirlerinden bağımsız olarak yapan thread'ler de söz konusu olabilir. Çoğu zaman çalıştırılabilir programın main fonksiyonu ile akan akış tek bir thread ile işleyişini sürdürür ama ihtiyaç dahillinde yeni thread'ler açmak gerekir. Rust için process içerisinde bir thread açmak oldukça kolaydır ve bellek tüketimi açısından maliyeti düşüktür. Ownership ve borrowing kuralları sayesinde bellek sahası güvende kalır ve özellikle data-race sorunları oluşmaz.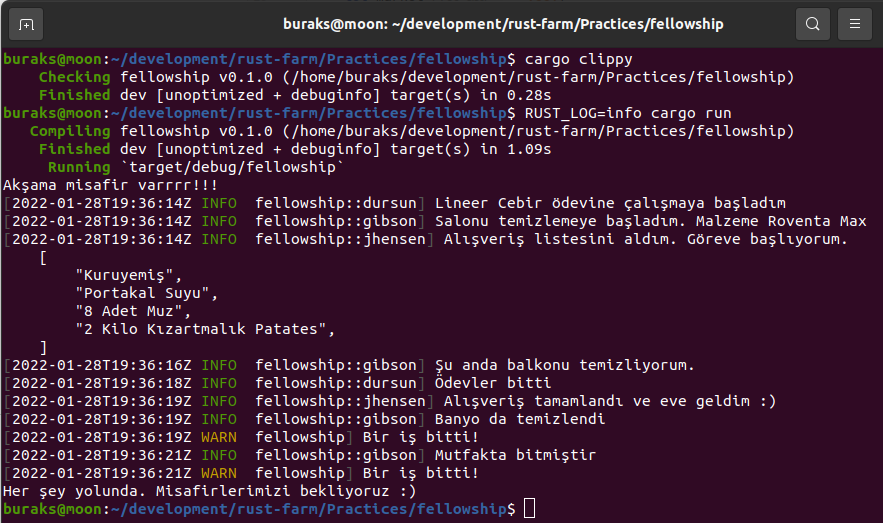
 Bir programlama dilini iyi yapan ve onu öne çıkaran bazı önemli unsurlar vardır. İdeal bir söz dizimi oluşturulması için önerilerde bulunmak, kullanılan fonksiyon veya türlerle ilgili yardım dokümantasyonları sunmak, merkezi ve başarılı bir paket yönetim sistemine sahip olmak bunlar arasında sayılabilir. Rust dilindeki pek çok kural sayesinde bellek sahasının güvende kaldığı(memory safe), dangle pointer, data race, memory leak gibi sorunların oluşmadığı, performansı yüksek ve üstelik bütün bunlar için garbage collector benzeri mekanizmalara ihtiyaç duymayacak şekilde geliştirme yapmamız mümkün. Yine de idiomatic olarak ifade edilen ve dilin en ideal şekilde kullanılmasını tarifleyen ihtiyaç için yardım almamız gerekiyor. Bu anlamda cargo clippy en büyük destekçimiz. Ancak kaliteli kodlamanın olmazsa olmaz önemli özelliklerinden birisi de elbette verimli içerik sunan dokümantasyon. Özellikle yazdığımız kütüphaneleri herkesin kullanımına açmak istediğimiz senaryolarda bu konuya azami özeni göstermek lazım.
Bir programlama dilini iyi yapan ve onu öne çıkaran bazı önemli unsurlar vardır. İdeal bir söz dizimi oluşturulması için önerilerde bulunmak, kullanılan fonksiyon veya türlerle ilgili yardım dokümantasyonları sunmak, merkezi ve başarılı bir paket yönetim sistemine sahip olmak bunlar arasında sayılabilir. Rust dilindeki pek çok kural sayesinde bellek sahasının güvende kaldığı(memory safe), dangle pointer, data race, memory leak gibi sorunların oluşmadığı, performansı yüksek ve üstelik bütün bunlar için garbage collector benzeri mekanizmalara ihtiyaç duymayacak şekilde geliştirme yapmamız mümkün. Yine de idiomatic olarak ifade edilen ve dilin en ideal şekilde kullanılmasını tarifleyen ihtiyaç için yardım almamız gerekiyor. Bu anlamda cargo clippy en büyük destekçimiz. Ancak kaliteli kodlamanın olmazsa olmaz önemli özelliklerinden birisi de elbette verimli içerik sunan dokümantasyon. Özellikle yazdığımız kütüphaneleri herkesin kullanımına açmak istediğimiz senaryolarda bu konuya azami özeni göstermek lazım.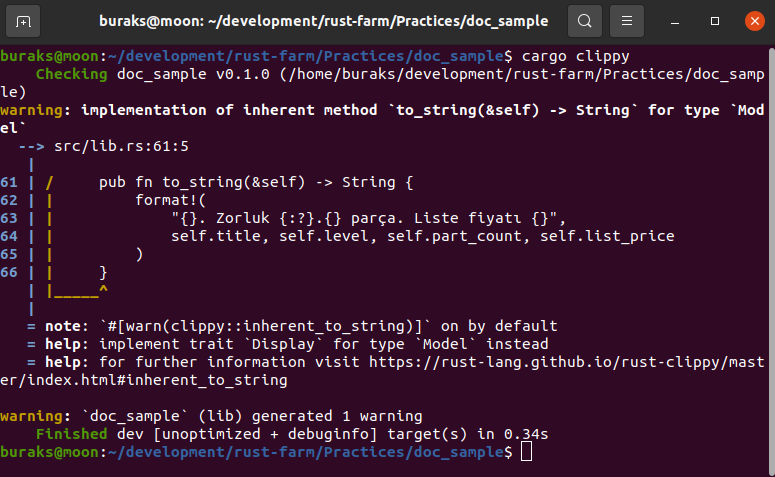
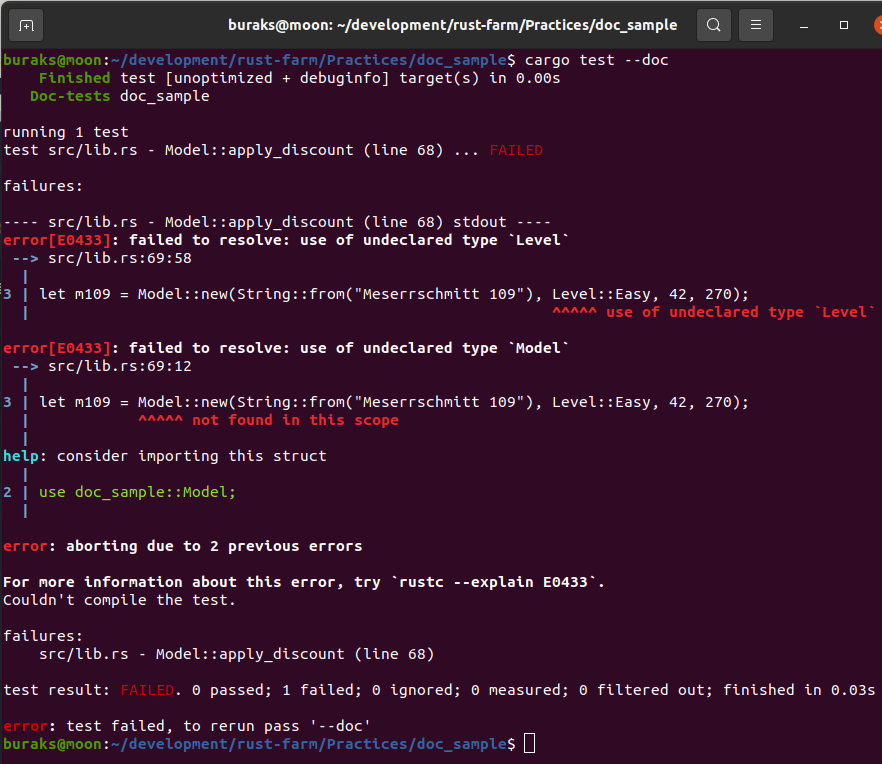
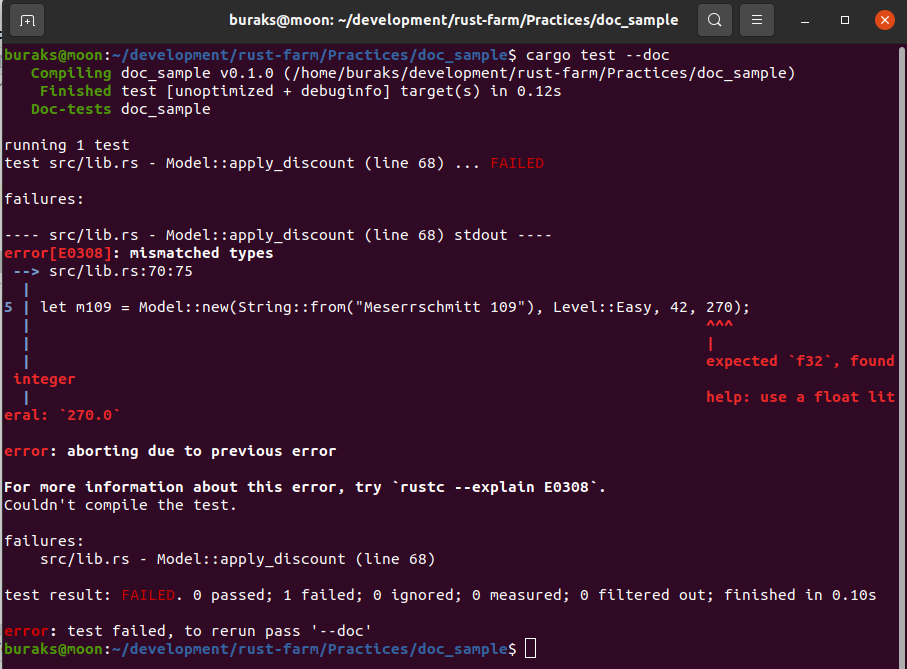
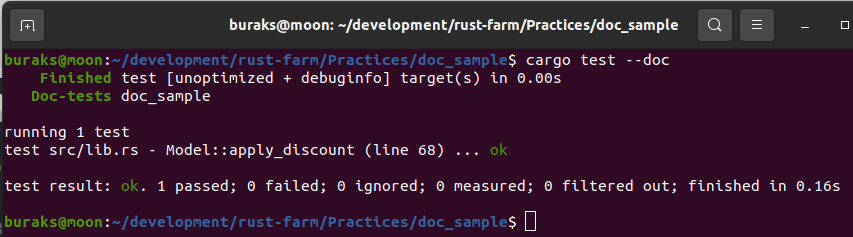
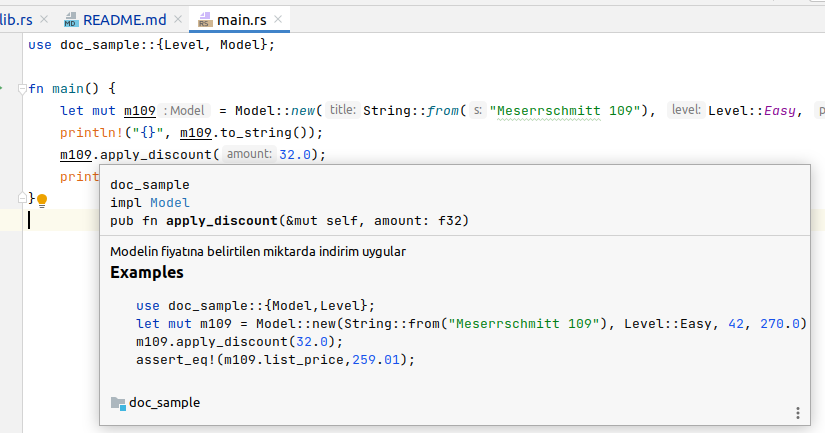
 Thread'ler aralarında haberleşmek için kanallardan(channels) yararlanır. Rust dilinde bu amaçla built-in modüllerinden olan mpsc(multi-producer single-consumer) paketi kullanılır. Bu paket aslında FIFO(First-In First-Out) ilkesine göre çalışan tipik bir kuyruk yapısıdır. Kanallar yardımıyla örneğin iki thread arasında bir yol açıp tek yönlü olarak mesaj göndermek mümkündür. Böylece bir thread'den diğerine çeşitli verileri aktarabiliriz. Hatta asenkron ve olay güdümlü(event-driven) haberleşmeler dahi tesis edebiliriz. Bir veri türünün kanalda akması için Send trait'ini uyarlamış olması gerekir. Primitive tiplerin hepsi bu davranışa sahiptir.
Thread'ler aralarında haberleşmek için kanallardan(channels) yararlanır. Rust dilinde bu amaçla built-in modüllerinden olan mpsc(multi-producer single-consumer) paketi kullanılır. Bu paket aslında FIFO(First-In First-Out) ilkesine göre çalışan tipik bir kuyruk yapısıdır. Kanallar yardımıyla örneğin iki thread arasında bir yol açıp tek yönlü olarak mesaj göndermek mümkündür. Böylece bir thread'den diğerine çeşitli verileri aktarabiliriz. Hatta asenkron ve olay güdümlü(event-driven) haberleşmeler dahi tesis edebiliriz. Bir veri türünün kanalda akması için Send trait'ini uyarlamış olması gerekir. Primitive tiplerin hepsi bu davranışa sahiptir.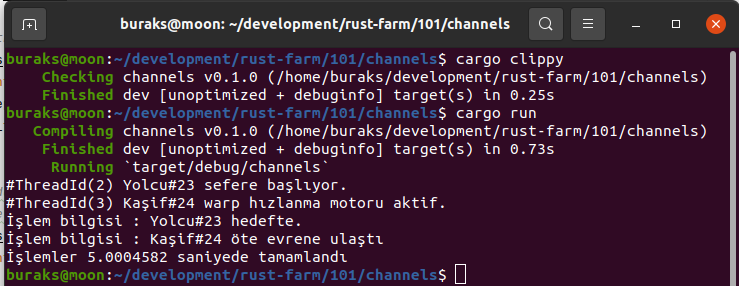
 Rust dilinin en güçlü olduğu yer etkili bellek yönetimi ve olası kaosların önüne herhangi bir garbage collector veya başka bir unsura ihtiyaç duymadan geçebilecek kural setleri barındırmasıdır. Özellikle Memory Leak, Double Free, Data Race gibi C, C++ dillerinde sıklıkla rastlanan durumların oluşmaması için basit kurallar barındırır. Bu kurallar ilk başlarda rust öğrenenleri epey zorlar fakat bir kez alışılınca her şey çok daha net ve berrak hale gelir. Bellek yönetimi denilince içeride neler oluyor bitiyor görmek de önemlidir. Fonksiyonlar birer kapsam olarak Stack'e yığılır, çeşitli veri türleri(String gibi) heap'e açılıp pointer alır, kapsamlar sonlandığında bir şeyler olur vs
Rust dilinin en güçlü olduğu yer etkili bellek yönetimi ve olası kaosların önüne herhangi bir garbage collector veya başka bir unsura ihtiyaç duymadan geçebilecek kural setleri barındırmasıdır. Özellikle Memory Leak, Double Free, Data Race gibi C, C++ dillerinde sıklıkla rastlanan durumların oluşmaması için basit kurallar barındırır. Bu kurallar ilk başlarda rust öğrenenleri epey zorlar fakat bir kez alışılınca her şey çok daha net ve berrak hale gelir. Bellek yönetimi denilince içeride neler oluyor bitiyor görmek de önemlidir. Fonksiyonlar birer kapsam olarak Stack'e yığılır, çeşitli veri türleri(String gibi) heap'e açılıp pointer alır, kapsamlar sonlandığında bir şeyler olur vs
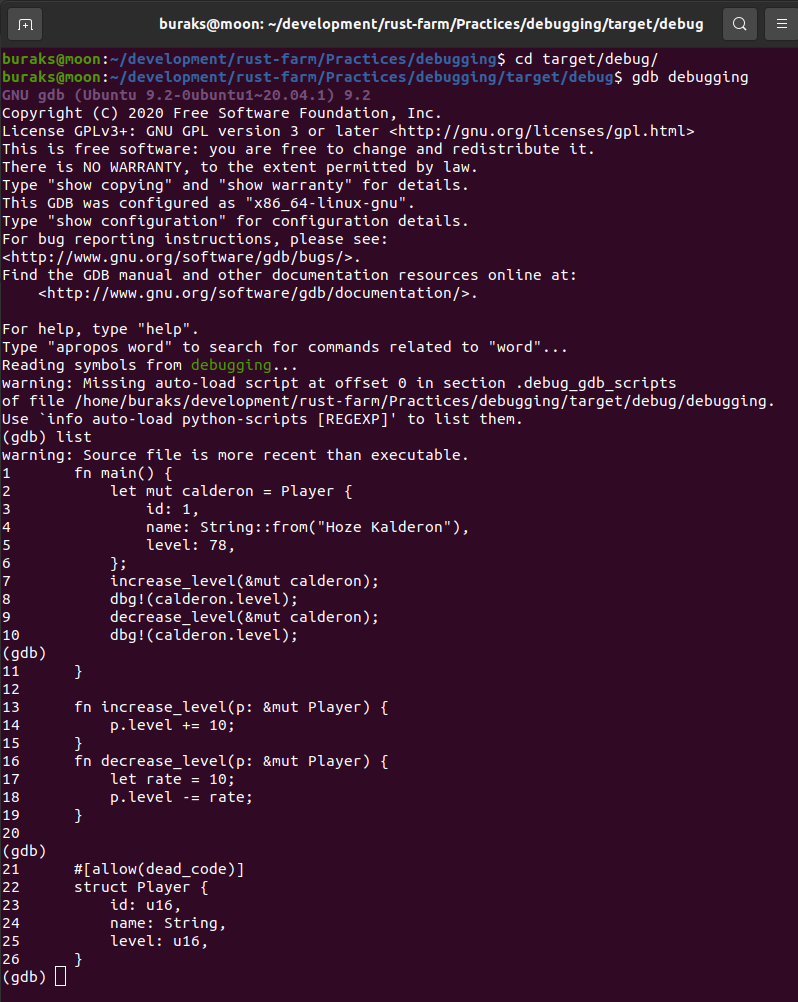
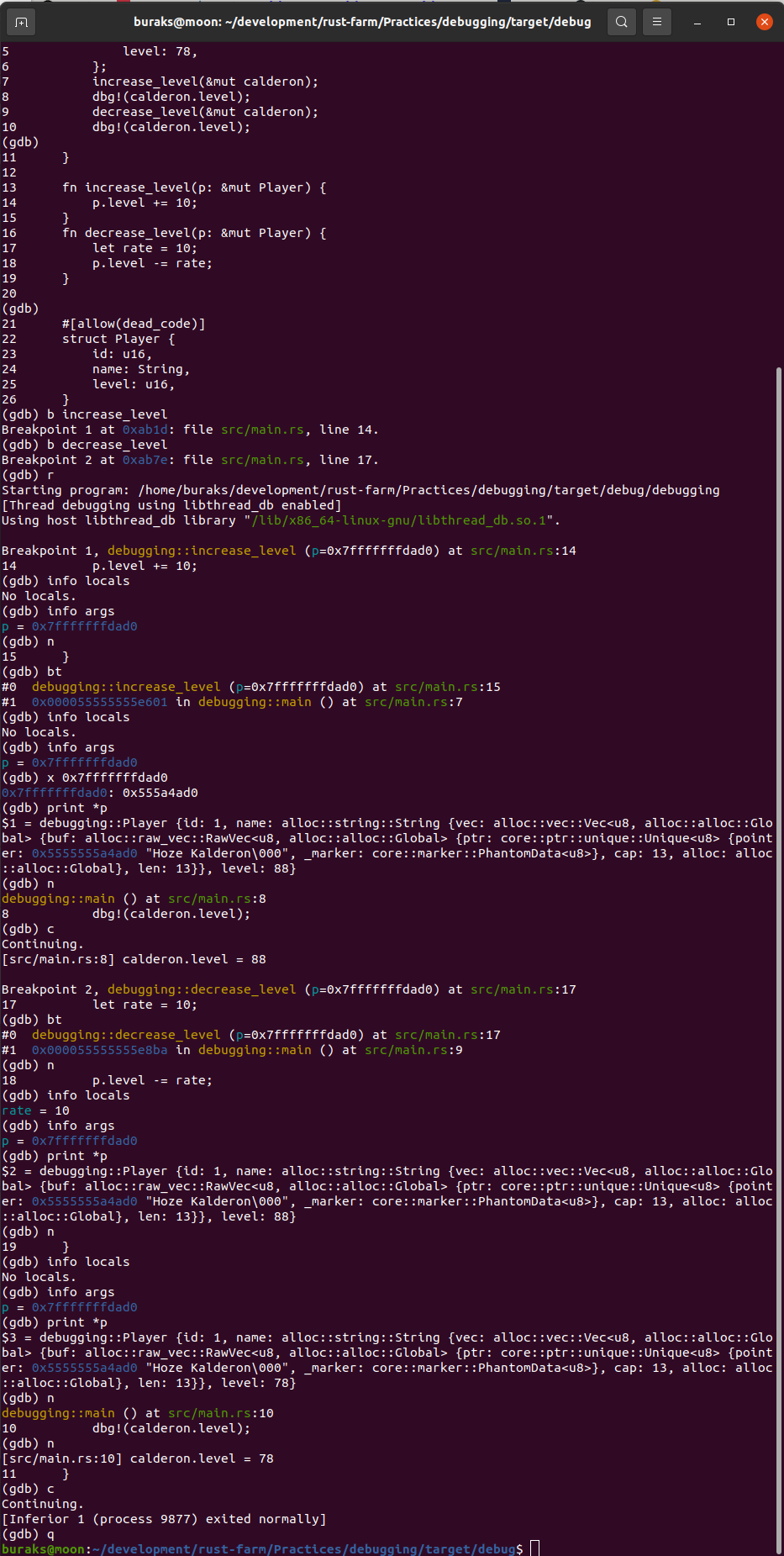
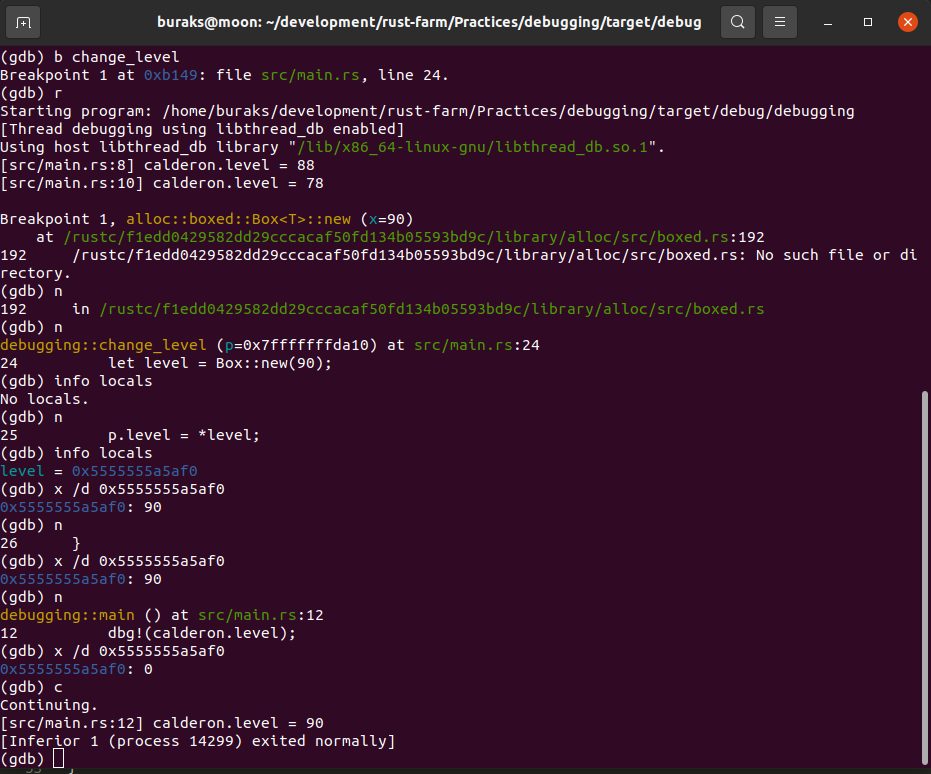
 Rust'ın özellikle Garbage Collector kullanan dillerden çok farklı olduğunu bellek yönetimi için getirdiği kurallardan dolayı biliyoruz. Ownership, borrowing gibi hususlar sayesinde güvenli bir bellek ortamını garanti etmek üzerine ihtisas yapmış bir dil olduğunu söylesek yeridir. Bunlar pek çok dilde otomatik yönetildiği için Rust'ı öğrenmek biraz zaman alabiliyor ve bu yolda karşımıza çıkacak zor konulardan birisi de Lifetimes mevzusu. Kısaca nesnelere yaşam süresini bilinçli olarak vermek diye ifade edebileceğimiz bu konuyu esasında sevgili
Rust'ın özellikle Garbage Collector kullanan dillerden çok farklı olduğunu bellek yönetimi için getirdiği kurallardan dolayı biliyoruz. Ownership, borrowing gibi hususlar sayesinde güvenli bir bellek ortamını garanti etmek üzerine ihtisas yapmış bir dil olduğunu söylesek yeridir. Bunlar pek çok dilde otomatik yönetildiği için Rust'ı öğrenmek biraz zaman alabiliyor ve bu yolda karşımıza çıkacak zor konulardan birisi de Lifetimes mevzusu. Kısaca nesnelere yaşam süresini bilinçli olarak vermek diye ifade edebileceğimiz bu konuyu esasında sevgili 
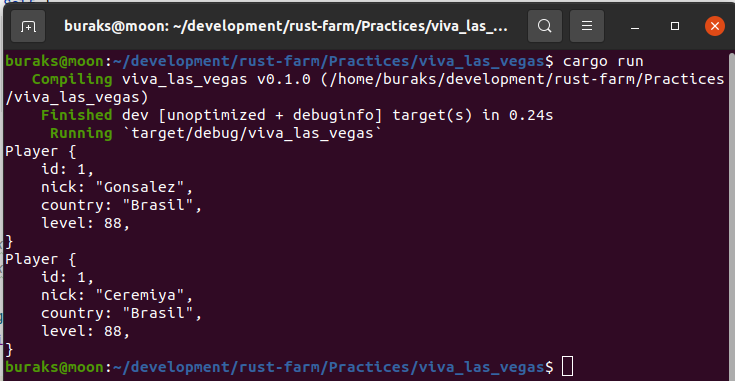
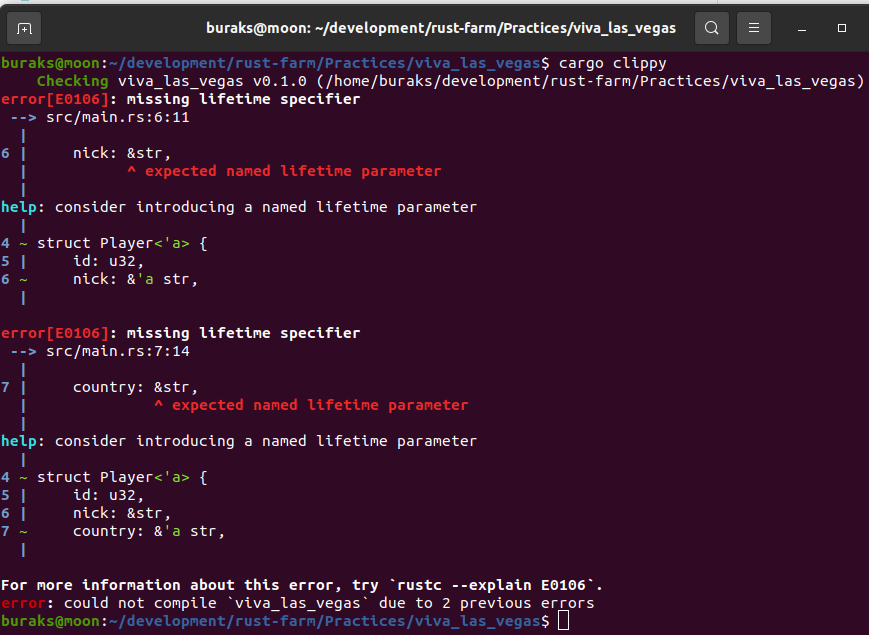
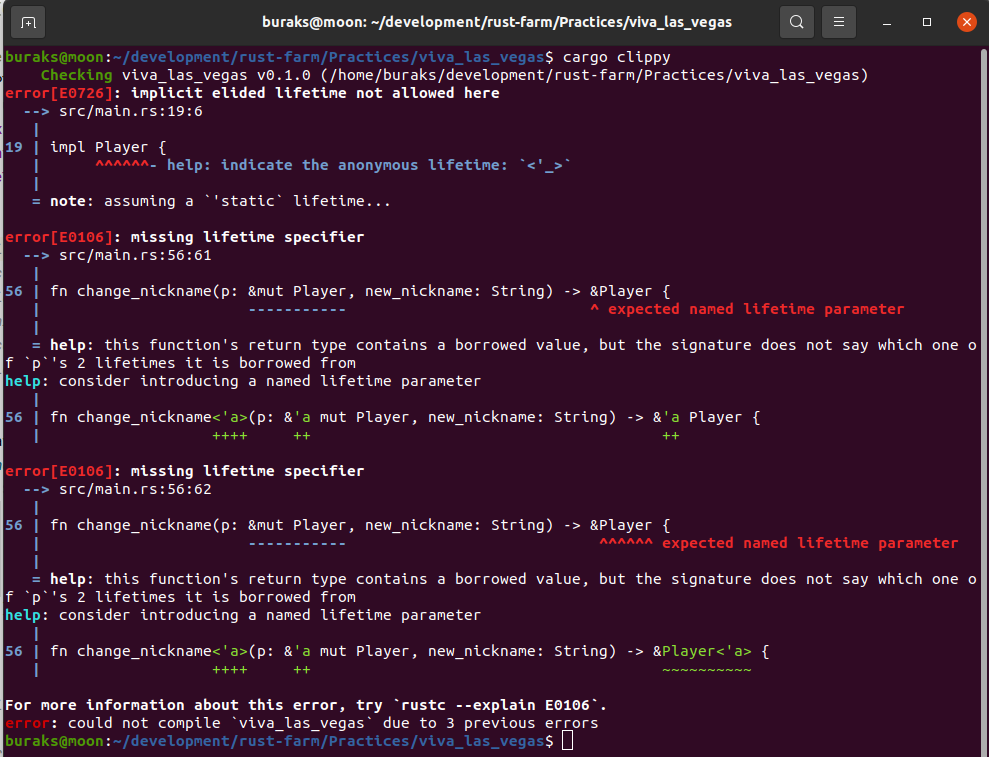
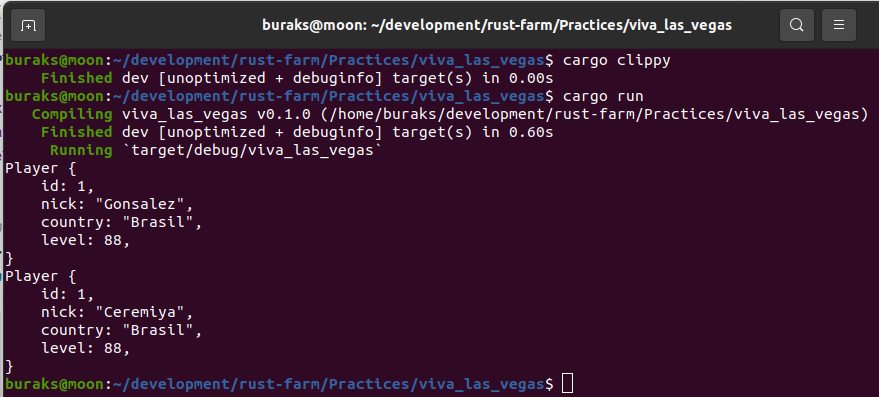
 Sanıyorum JSON veriler ile çalışmayan programlama dili veya ortam yoktur. Sonuç itibariyle bir takım verileri düzenli, standart ve insan gözüyle okunabilir bir formatta tutmanın en iyi yollarından birisi şüphesiz ki JSON. Öncesinden gelen XML formatına göre daha az yer tutması da cazibesini artırmaktadır. Tabii günümüzde BSON gibi sıkıştırılabilir ve çok daha hızlı yol alabilen seçenekler de mevcut ama rust dilini öğrenirken bunun pratiğini yapmadan olmaz. Bu noktada işimizi epey kolaylaştıran bir kütüphane olduğunu ifade edebilirim.
Sanıyorum JSON veriler ile çalışmayan programlama dili veya ortam yoktur. Sonuç itibariyle bir takım verileri düzenli, standart ve insan gözüyle okunabilir bir formatta tutmanın en iyi yollarından birisi şüphesiz ki JSON. Öncesinden gelen XML formatına göre daha az yer tutması da cazibesini artırmaktadır. Tabii günümüzde BSON gibi sıkıştırılabilir ve çok daha hızlı yol alabilen seçenekler de mevcut ama rust dilini öğrenirken bunun pratiğini yapmadan olmaz. Bu noktada işimizi epey kolaylaştıran bir kütüphane olduğunu ifade edebilirim.